 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Depth and Width on Transformer Language Model Generalization
Paper and Code
Oct 30, 2023
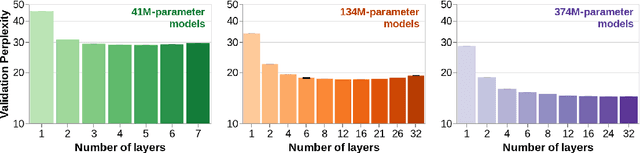

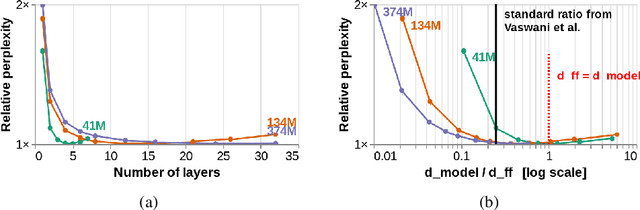
To process novel sentences, language models (LMs) must generalize compositionally -- combine familiar elements in new ways. What aspects of a model's structure promote compositional generalization? Focusing on transformers, we test the hypothesis, motivated by recent theoretical and empirical work, that transformers generalize more compositionally when they are deeper (have more layers). Because simply adding layers increases the total number of parameters, confounding depth and size, we construct three classes of models which trade off depth for width such that the total number of parameters is kept constant (41M, 134M and 374M parameters). We pretrain all models as LMs and fine-tune them on tasks that test for compositional generalization. We report three main conclusions: (1) after fine-tuning, deeper models generalize better out-of-distribution than shallower models do, but the relative benefit of additional layers diminishes rapidly; (2) within each family, deeper models show better language modeling performance, but returns are similarly diminishing; (3) the benefits of depth for compositional generalization cannot be attributed solely to better performance on language modeling or on in-distribution data.