 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Video Masked Autoencoders
Dec 15, 2025We present Recurrent Video Masked-Autoencoders (RVM): a novel video representation learning approach that uses a transformer-based recurrent neural network to aggregate dense image features over time, effectively capturing the spatio-temporal structure of natural video data. RVM learns via an asymmetric masked prediction task requiring only a standard pixel reconstruction objective. This design yields a highly efficient ``generalist'' encoder: RVM achieves competitive performance with state-of-the-art video models (e.g. VideoMAE, V-JEPA) on video-level tasks like action recognition and point/object tracking, while also performing favorably against image models (e.g. DINOv2) on tasks that test geometric and dense spatial understanding. Notably, RVM achieves strong performance in the small-model regime without requiring knowledge distillation, exhibiting up to 30x greater parameter efficiency than competing video masked autoencoders. Moreover, we demonstrate that RVM's recurrent nature allows for stable feature propagation over long temporal horizons with linear computational cost, overcoming some of the limitations of standard spatio-temporal attention-based architectures. Finally, we use qualitative visualizations to highlight that RVM learns rich representations of scene semantics, structure, and motion.
Direct Motion Models for Assessing Generated Videos
Apr 30, 2025A current limitation of video generative video models is that they generate plausible looking frames, but poor motion -- an issue that is not well captured by FVD and other popular methods for evaluating generated videos. Here we go beyond FVD by developing a metric which better measures plausible object interactions and motion. Our novel approach is based on auto-encoding point tracks and yields motion features that can be used to not only compare distributions of videos (as few as one generated and one ground truth, or as many as two datasets), but also for evaluating motion of single videos. We show that using point tracks instead of pixel reconstruction or action recognition features results in a metric which is markedly more sensitive to temporal distortions in synthetic data, and can predict human evaluations of temporal consistency and realism in generated videos obtained from open-source models better than a wide range of alternatives. We also show that by using a point track representation, we can spatiotemporally localize generative video inconsistencies, providing extra interpretability of generated video errors relative to prior work. An overview of the results and link to the code can be found on the project page: http://trajan-paper.github.io.
Probabilistic Inverse Cameras: Image to 3D via Multiview Geometry
Dec 13, 2024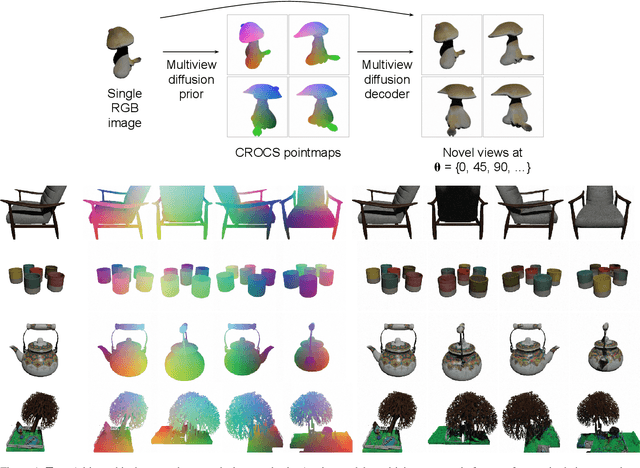

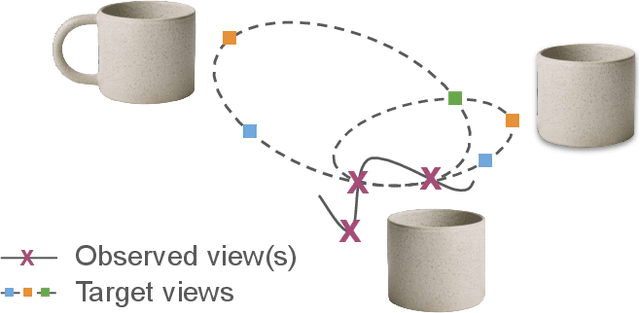

We introduce a hierarchical probabilistic approach to go from a 2D image to multiview 3D: a diffusion "prior" models the unseen 3D geometry, which then conditions a diffusion "decoder" to generate novel views of the subject. We use a pointmap-based geometric representation in a multiview image format to coordinate the generation of multiple target views simultaneously. We facilitate correspondence between views by assuming fixed target camera poses relative to the source camera, and constructing a predictable distribution of geometric features per target. Our modular, geometry-driven approach to novel-view synthesis (called "unPIC") beats SoTA baselines such as CAT3D and One-2-3-45 on held-out objects from ObjaverseXL, as well as real-world objects ranging from Google Scanned Objects, Amazon Berkeley Objects, to the Digital Twin Catalog.
Moving Off-the-Grid: Scene-Grounded Video Representations
Nov 08, 2024



Current vision models typically maintain a fixed correspondence between their representation structure and image space. Each layer comprises a set of tokens arranged "on-the-grid," which biases patches or tokens to encode information at a specific spatio(-temporal) location. In this work we present Moving Off-the-Grid (MooG), a self-supervised video representation model that offers an alternative approach, allowing tokens to move "off-the-grid" to better enable them to represent scene elements consistently, even as they move across the image plane through time. By using a combination of cross-attention and positional embeddings we disentangle the representation structure and image structure. We find that a simple self-supervised objective--next frame prediction--trained on video data, results in a set of latent tokens which bind to specific scene structures and track them as they move. We demonstrate the usefulness of MooG's learned representation both qualitatively and quantitatively by training readouts on top of the learned representation on a variety of downstream tasks. We show that MooG can provide a strong foundation for different vision tasks when compared to "on-the-grid" baselines.
TAPIR: Tracking Any Point with per-frame Initialization and temporal Refinement
Jun 14, 2023We present a novel model for Tracking Any Point (TAP) that effectively tracks any queried point on any physical surface throughout a video sequence. Our approach employs two stages: (1) a matching stage, which independently locates a suitable candidate point match for the query point on every other frame, and (2) a refinement stage, which updates both the trajectory and query features based on local correlations. The resulting model surpasses all baseline methods by a significant margin on the TAP-Vid benchmark, as demonstrated by an approximate 20% absolute average Jaccard (AJ) improvement on DAVIS. Our model facilitates fast inference on long and high-resolution video sequences. On a modern GPU, our implementation has the capacity to track points faster than real-time. Visualizations, source code, and pretrained models can be found on our project webpage.
Compressed Vision for Efficient Video Understanding
Oct 06, 2022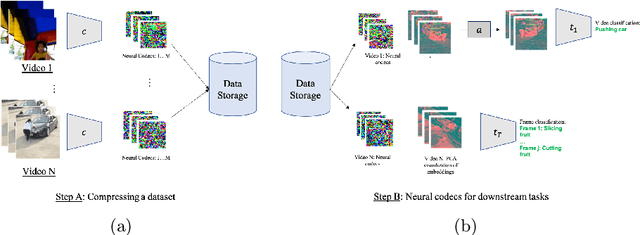
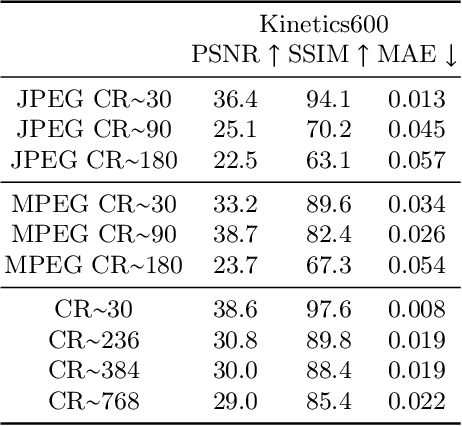
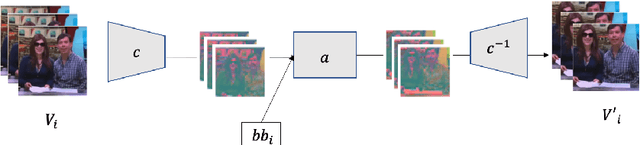

Experience and reasoning occur across multiple temporal scales: milliseconds, seconds, hours or days. The vast majority of computer vision research, however, still focuses on individual images or short videos lasting only a few seconds. This is because handling longer videos require more scalable approaches even to process them. In this work, we propose a framework enabling research on hour-long videos with the same hardware that can now process second-long videos. We replace standard video compression, e.g. JPEG, with neural compression and show that we can directly feed compressed videos as inputs to regular video networks. Operating on compressed videos improves efficiency at all pipeline levels -- data transfer, speed and memory -- making it possible to train models faster and on much longer videos. Processing compressed signals has, however, the downside of precluding standard augmentation techniques if done naively. We address that by introducing a small network that can apply transformations to latent codes corresponding to commonly used augmentations in the original video space. We demonstrate that with our compressed vision pipeline, we can train video models more efficiently on popular benchmarks such as Kinetics600 and COIN. We also perform proof-of-concept experiments with new tasks defined over hour-long videos at standard frame rates. Processing such long videos is impossible without using compressed representation.
Hierarchical Perceiver
Feb 22, 2022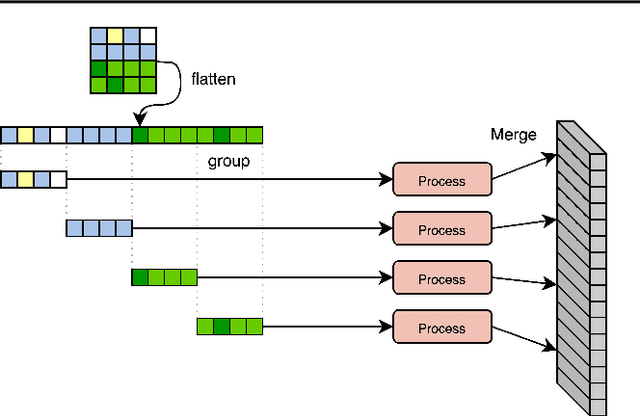

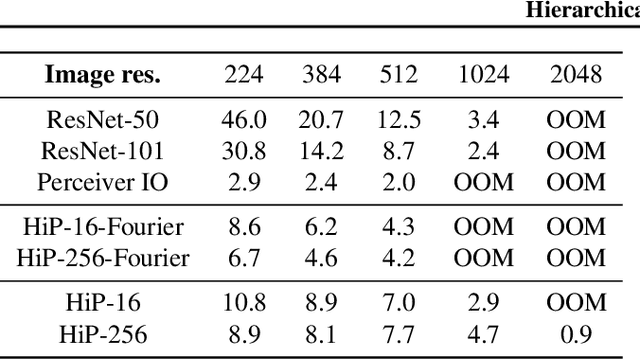

General perception systems such as Perceivers can process arbitrary modalities in any combination and are able to handle up to a few hundred thousand inputs. They achieve this generality by exclusively using global attention operations. This however hinders them from scaling up to the inputs sizes required to process raw high-resolution images or video. In this paper, we show that some degree of locality can be introduced back into these models, greatly improving their efficiency while preserving their generality. To scale them further, we introduce a self-supervised approach that enables learning dense low-dimensional positional embeddings for very large signals. We call the resulting model a Hierarchical Perceiver (HiP). HiP retains the ability to process arbitrary modalities, but now at higher-resolution and without any specialized preprocessing, improving over flat Perceivers in both efficiency and accuracy on the ImageNet, Audioset and PASCAL VOC datasets.
Towards Learning Universal Audio Representations
Dec 01, 2021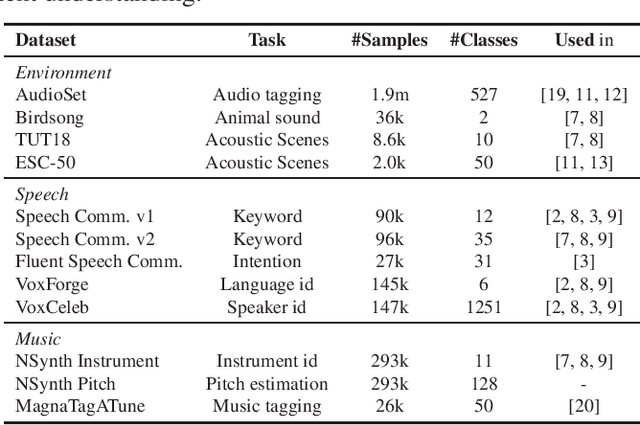
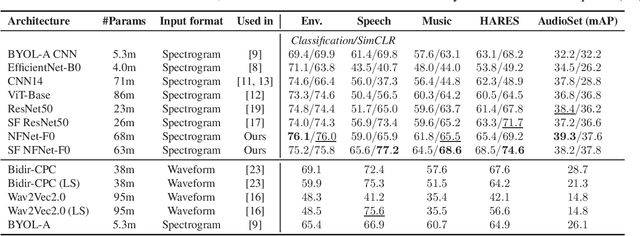
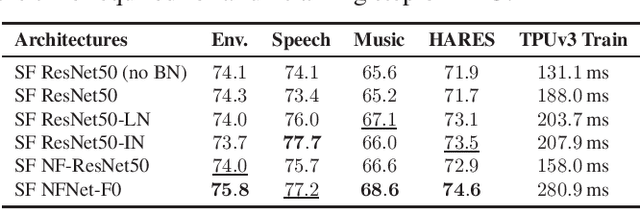
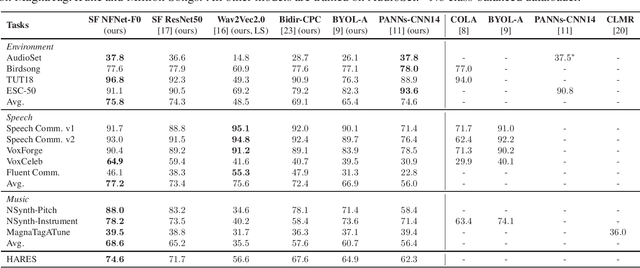
The ability to learn universal audio representations that can solve diverse speech, music, and environment tasks can spur many applications that require general sound content understanding. In this work, we introduce a holistic audio representation evaluation suite (HARES) spanning 12 downstream tasks across audio domains and provide a thorough empirical study of recent sound representation learning systems on that benchmark. We discover that previous sound event classification or speech models do not generalize outside of their domains. We observe that more robust audio representations can be learned with the SimCLR objective; however, the model's transferability depends heavily on the model architecture. We find the Slowfast architecture is good at learning rich representations required by different domains, but its performance is affected by the normalization scheme. Based on these findings, we propose a novel normalizer-free Slowfast NFNet and achieve state-of-the-art performance across all domains.
Gradient Forward-Propagation for Large-Scale Temporal Video Modelling
Jul 12, 2021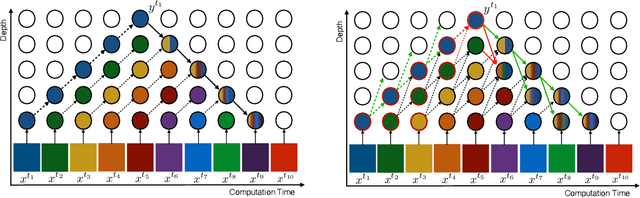
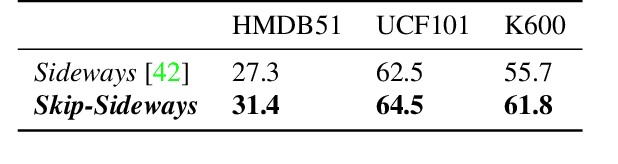
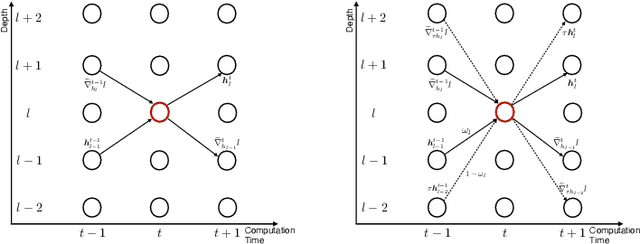

How can neural networks be trained on large-volume temporal data efficiently? To compute the gradients required to update parameters, backpropagation blocks computations until the forward and backward passes are completed. For temporal signals, this introduces high latency and hinders real-time learning. It also creates a coupling between consecutive layers, which limits model parallelism and increases memory consumption. In this paper, we build upon Sideways, which avoids blocking by propagating approximate gradients forward in time, and we propose mechanisms for temporal integration of information based on different variants of skip connections. We also show how to decouple computation and delegate individual neural modules to different devices, allowing distributed and parallel training. The proposed Skip-Sideways achieves low latency training, model parallelism, and, importantly, is capable of extracting temporal features, leading to more stable training and improved performance on real-world action recognition video datasets such as HMDB51, UCF101, and the large-scale Kinetics-600. Finally, we also show that models trained with Skip-Sideways generate better future frames than Sideways models, and hence they can better utilize motion cues.
Perceiver: General Perception with Iterative Attention
Mar 04, 2021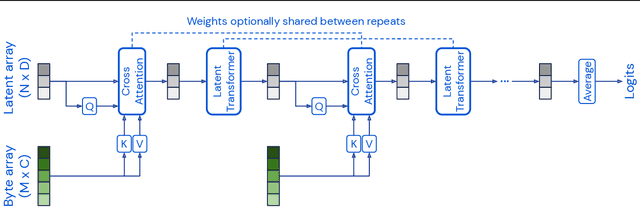

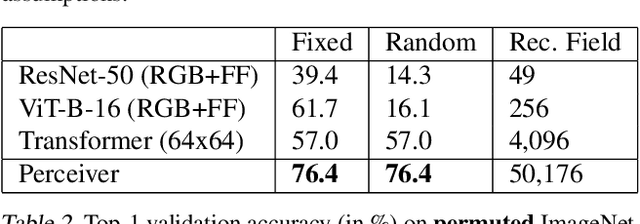
Biological systems understand the world by simultaneously processing high-dimensional inputs from modalities as diverse as vision, audition, touch, proprioception, etc. The perception models used in deep learning on the other hand are designed for individual modalities, often relying on domain-specific assumptions such as the local grid structures exploited by virtually all existing vision models. These priors introduce helpful inductive biases, but also lock models to individual modalities. In this paper we introduce the Perceiver - a model that builds upon Transformers and hence makes few architectural assumptions about the relationship between its inputs, but that also scales to hundreds of thousands of inputs, like ConvNets. The model leverages an asymmetric attention mechanism to iteratively distill inputs into a tight latent bottleneck, allowing it to scale to handle very large inputs. We show that this architecture performs competitively or beyond strong, specialized models on classification tasks across various modalities: images, point clouds, audio, video and video+audio. The Perceiver obtains performance comparable to ResNet-50 on ImageNet without convolutions and by directly attending to 50,000 pixels. It also surpasses state-of-the-art results for all modalities in AudioSet.