 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Short Note on the Kinetics-700 Human Action Dataset
Jul 15, 2019
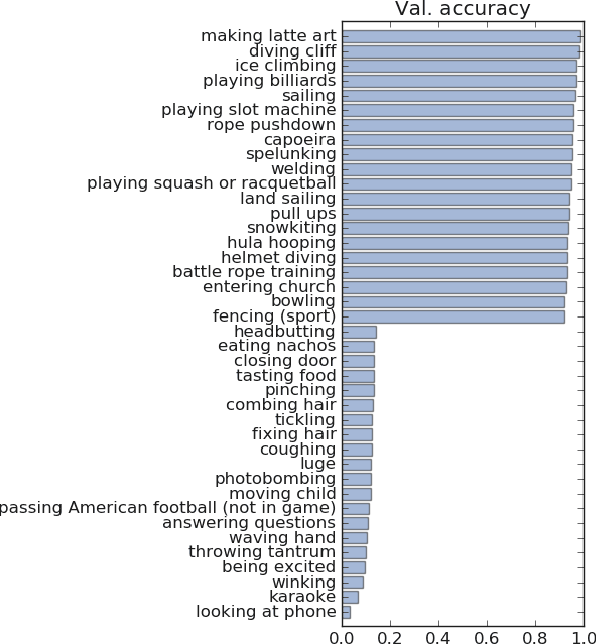
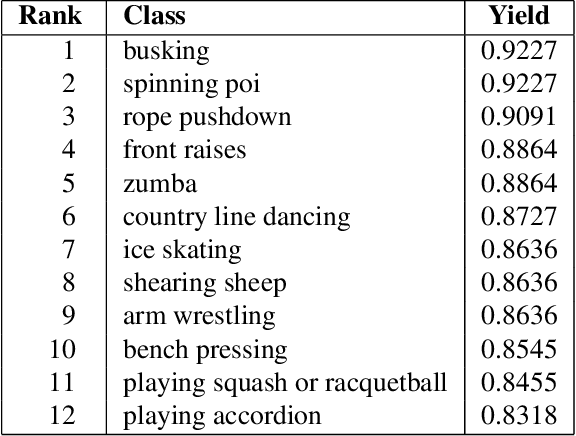

We describe an extension of the DeepMind Kinetics human action dataset from 600 classes to 700 classes, where for each class there are at least 600 video clips from different YouTube videos. This paper details the changes introduced for this new release of the dataset, and includes a comprehensive set of statistics as well as baseline results using the I3D neural network architecture.
A Short Note about Kinetics-600
Aug 03, 2018

We describe an extension of the DeepMind Kinetics human action dataset from 400 classes, each with at least 400 video clips, to 600 classes, each with at least 600 video clips. In order to scale up the dataset we changed the data collection process so it uses multiple queries per class, with some of them in a language other than english -- portuguese. This paper details the changes between the two versions of the dataset and includes a comprehensive set of statistics of the new version as well as baseline results using the I3D neural network architecture. The paper is a companion to the release of the ground truth labels for the public test set.
Unsupervised Predictive Memory in a Goal-Directed Agent
Mar 28, 2018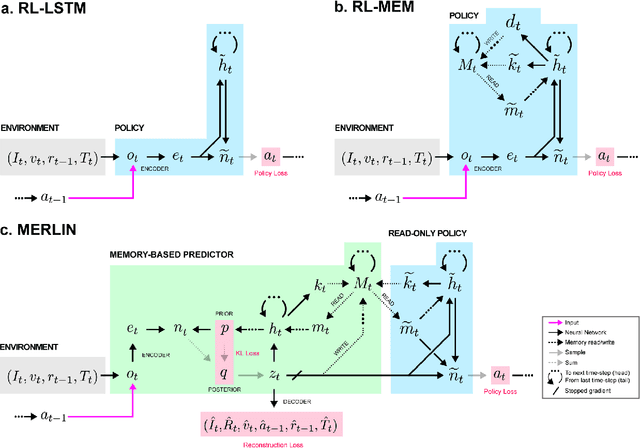
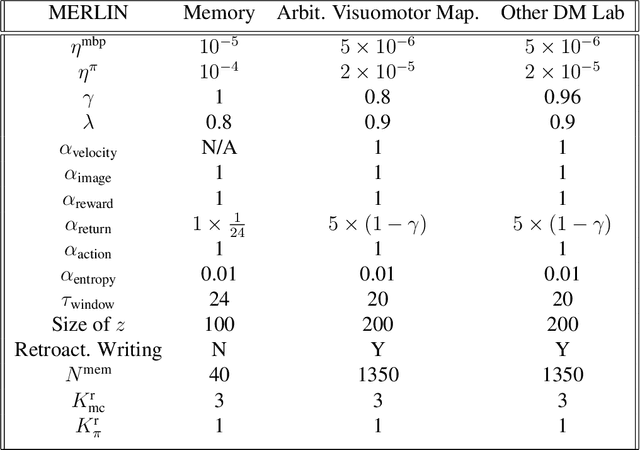
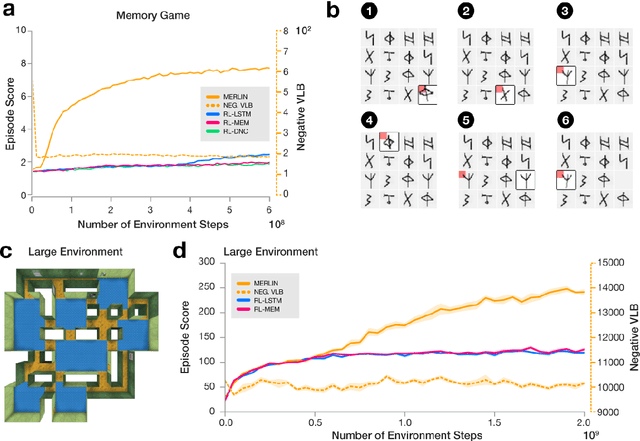

Animals execute goal-directed behaviours despite the limited range and scope of their sensors. To cope, they explore environments and store memories maintaining estimates of important information that is not presently available. Recently, progress has been made with artificial intelligence (AI) agents that learn to perform tasks from sensory input, even at a human level, by merging reinforcement learning (RL) algorithms with deep neural networks, and the excitement surrounding these results has led to the pursuit of related ideas as explanations of non-human animal learning. However, we demonstrate that contemporary RL algorithms struggle to solve simple tasks when enough information is concealed from the sensors of the agent, a property called "partial observability". An obvious requirement for handling partially observed tasks is access to extensive memory, but we show memory is not enough; it is critical that the right information be stored in the right format. We develop a model, the Memory, RL, and Inference Network (MERLIN), in which memory formation is guided by a process of predictive modeling. MERLIN facilitates the solution of tasks in 3D virtual reality environments for which partial observability is severe and memories must be maintained over long durations. Our model demonstrates a single learning agent architecture that can solve canonical behavioural tasks in psychology and neurobiology without strong simplifying assumptions about the dimensionality of sensory input or the duration of experiences.
The Kinetics Human Action Video Dataset
May 19, 2017
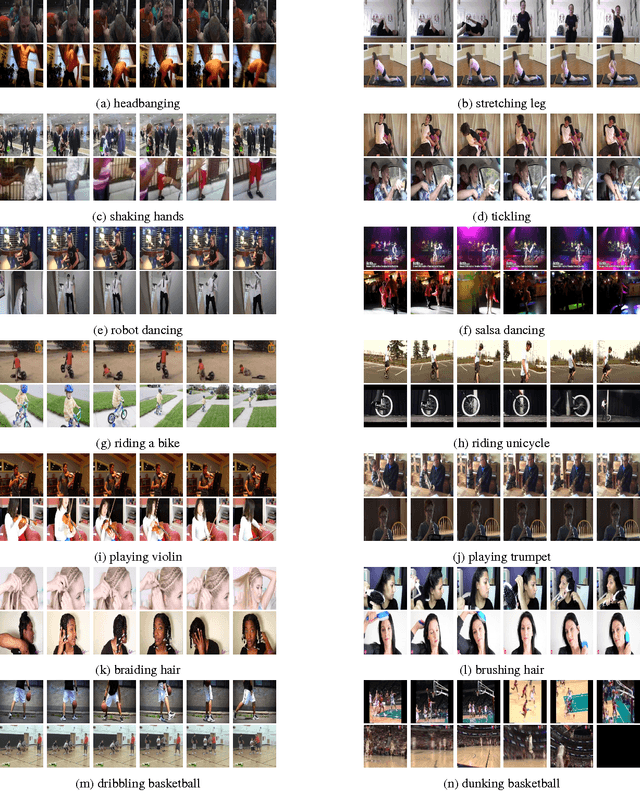
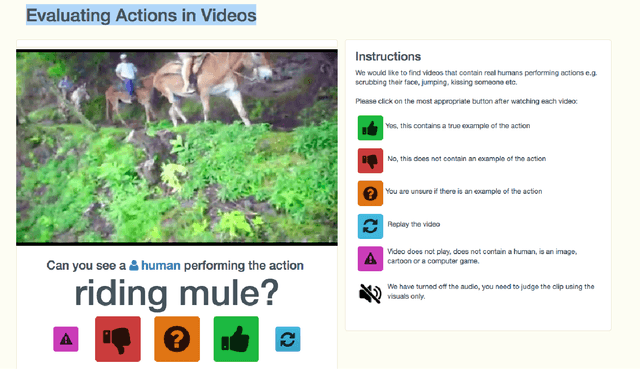
We describe the DeepMind Kinetics human action video dataset. The dataset contains 400 human action classes, with at least 400 video clips for each action. Each clip lasts around 10s and is taken from a different YouTube video. The actions are human focussed and cover a broad range of classes including human-object interactions such as playing instruments, as well as human-human interactions such as shaking hands. We describe the statistics of the dataset, how it was collected, and give some baseline performance figures for neural network architectures trained and tested for human action classification on this dataset. We also carry out a preliminary analysis of whether imbalance in the dataset leads to bias in the classifiers.