 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe StreetLearn Environment and Dataset
Mar 04, 2019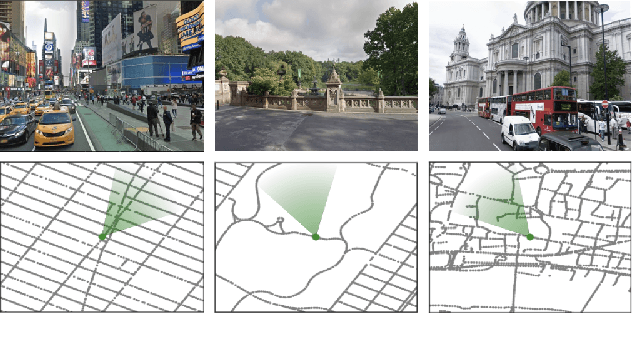

Navigation is a rich and well-grounded problem domain that drives progress in many different areas of research: perception, planning, memory, exploration, and optimisation in particular. Historically these challenges have been separately considered and solutions built that rely on stationary datasets - for example, recorded trajectories through an environment. These datasets cannot be used for decision-making and reinforcement learning, however, and in general the perspective of navigation as an interactive learning task, where the actions and behaviours of a learning agent are learned simultaneously with the perception and planning, is relatively unsupported. Thus, existing navigation benchmarks generally rely on static datasets (Geiger et al., 2013; Kendall et al., 2015) or simulators (Beattie et al., 2016; Shah et al., 2018). To support and validate research in end-to-end navigation, we present StreetLearn: an interactive, first-person, partially-observed visual environment that uses Google Street View for its photographic content and broad coverage, and give performance baselines for a challenging goal-driven navigation task. The environment code, baseline agent code, and the dataset are available at http://streetlearn.cc
Learning To Follow Directions in Street View
Mar 01, 2019

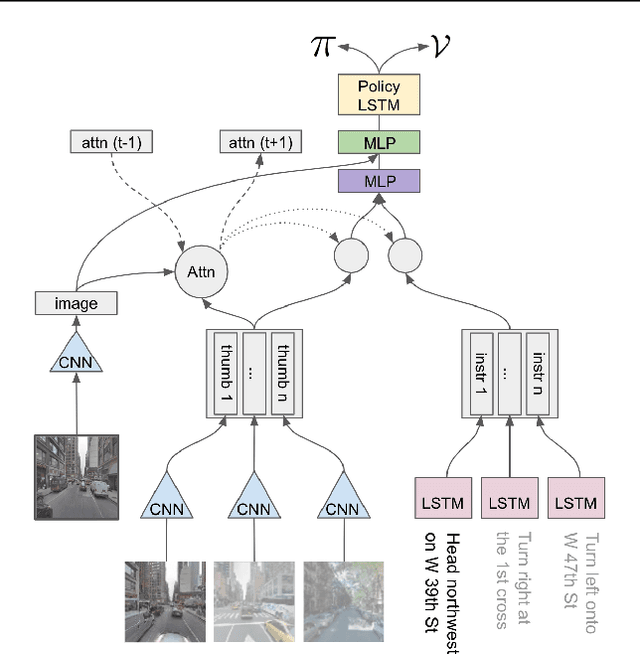
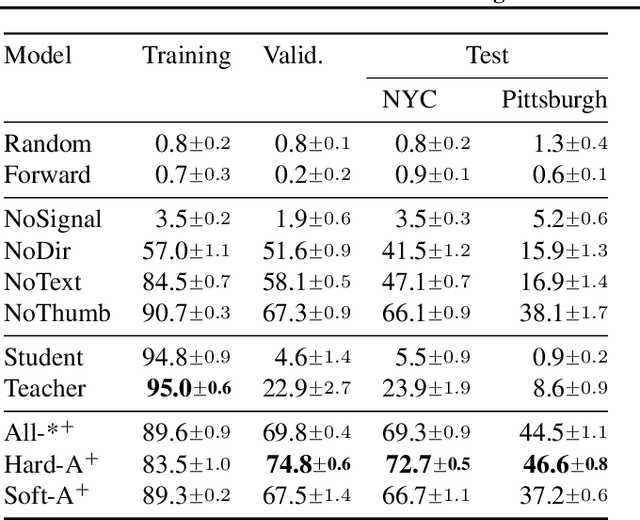
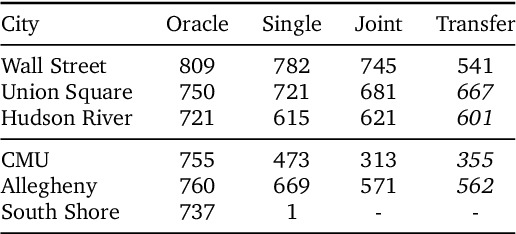
Navigating and understanding the real world remains a key challenge in machine learning and inspires a great variety of research in areas such as language grounding, planning, navigation and computer vision. We propose an instruction-following task that requires all of the above, and which combines the practicality of simulated environments with the challenges of ambiguous, noisy real world data. StreetNav is built on top of Google Street View and provides visually accurate environments representing real places. Agents are given driving instructions which they must learn to interpret in order to successfully navigate in this environment. Since humans equipped with driving instructions can readily navigate in previously unseen cities, we set a high bar and test our trained agents for similar cognitive capabilities. Although deep reinforcement learning (RL) methods are frequently evaluated only on data that closely follow the training distribution, our dataset extends to multiple cities and has a clean train/test separation. This allows for thorough testing of generalisation ability. This paper presents the StreetNav environment and tasks, a set of novel models that establish strong baselines, and analysis of the task and the trained agents.
A Short Note about Kinetics-600
Aug 03, 2018

We describe an extension of the DeepMind Kinetics human action dataset from 400 classes, each with at least 400 video clips, to 600 classes, each with at least 600 video clips. In order to scale up the dataset we changed the data collection process so it uses multiple queries per class, with some of them in a language other than english -- portuguese. This paper details the changes between the two versions of the dataset and includes a comprehensive set of statistics of the new version as well as baseline results using the I3D neural network architecture. The paper is a companion to the release of the ground truth labels for the public test set.