 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble Horizon Model-Based Policy Optimization
Dec 17, 2025Model-based reinforcement learning (MBRL) reduces the cost of real-environment sampling by generating synthetic trajectories (called rollouts) from a learned dynamics model. However, choosing the length of the rollouts poses two dilemmas: (1) Longer rollouts better preserve on-policy training but amplify model bias, indicating the need for an intermediate horizon to mitigate distribution shift (i.e., the gap between on-policy and past off-policy samples). (2) Moreover, a longer model rollout may reduce value estimation bias but raise the variance of policy gradients due to backpropagation through multiple steps, implying another intermediate horizon for stable gradient estimates. However, these two optimal horizons may differ. To resolve this conflict, we propose Double Horizon Model-Based Policy Optimization (DHMBPO), which divides the rollout procedure into a long "distribution rollout" (DR) and a short "training rollout" (TR). The DR generates on-policy state samples for mitigating distribution shift. In contrast, the short TR leverages differentiable transitions to offer accurate value gradient estimation with stable gradient updates, thereby requiring fewer updates and reducing overall runtime. We demonstrate that the double-horizon approach effectively balances distribution shift, model bias, and gradient instability, and surpasses existing MBRL methods on continuous-control benchmarks in terms of both sample efficiency and runtime.
Robust off-policy Reinforcement Learning via Soft Constrained Adversary
Aug 31, 2024Recently, robust reinforcement learning (RL) methods against input observation have garnered significant attention and undergone rapid evolution due to RL's potential vulnerability. Although these advanced methods have achieved reasonable success, there have been two limitations when considering adversary in terms of long-term horizons. First, the mutual dependency between the policy and its corresponding optimal adversary limits the development of off-policy RL algorithms; although obtaining optimal adversary should depend on the current policy, this has restricted applications to off-policy RL. Second, these methods generally assume perturbations based only on the $L_p$-norm, even when prior knowledge of the perturbation distribution in the environment is available. We here introduce another perspective on adversarial RL: an f-divergence constrained problem with the prior knowledge distribution. From this, we derive two typical attacks and their corresponding robust learning frameworks. The evaluation of robustness is conducted and the results demonstrate that our proposed methods achieve excellent performance in sample-efficient off-policy RL.
A Simple, Solid, and Reproducible Baseline for Bridge Bidding AI
Jun 14, 2024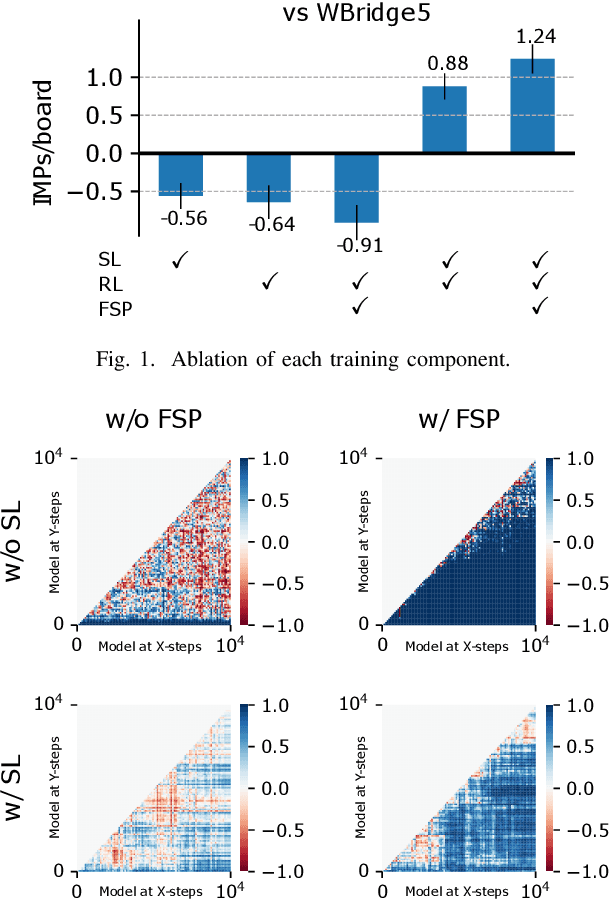

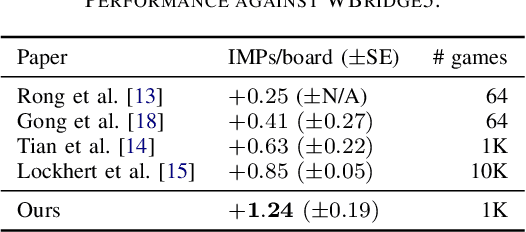
Contract bridge, a cooperative game characterized by imperfect information and multi-agent dynamics, poses significant challenges and serves as a critical benchmark in artificial intelligence (AI) research. Success in this domain requires agents to effectively cooperate with their partners. This study demonstrates that an appropriate combination of existing methods can perform surprisingly well in bridge bidding against WBridge5, a leading benchmark in the bridge bidding system and a multiple-time World Computer-Bridge Championship winner. Our approach is notably simple, yet it outperforms the current state-of-the-art methodologies in this field. Furthermore, we have made our code and models publicly available as open-source software. This initiative provides a strong starting foundation for future bridge AI research, facilitating the development and verification of new strategies and advancements in the field.
A Batch Sequential Halving Algorithm without Performance Degradation
Jun 01, 2024In this paper, we investigate the problem of pure exploration in the context of multi-armed bandits, with a specific focus on scenarios where arms are pulled in fixed-size batches. Batching has been shown to enhance computational efficiency, but it can potentially lead to a degradation compared to the original sequential algorithm's performance due to delayed feedback and reduced adaptability. We introduce a simple batch version of the Sequential Halving (SH) algorithm (Karnin et al., 2013) and provide theoretical evidence that batching does not degrade the performance of the original algorithm under practical conditions. Furthermore, we empirically validate our claim through experiments, demonstrating the robust nature of the SH algorithm in fixed-size batch settings.
End-to-End Policy Gradient Method for POMDPs and Explainable Agents
Apr 19, 2023Real-world decision-making problems are often partially observable, and many can be formulated as a Partially Observable Markov Decision Process (POMDP). When we apply reinforcement learning (RL) algorithms to the POMDP, reasonable estimation of the hidden states can help solve the problems. Furthermore, explainable decision-making is preferable, considering their application to real-world tasks such as autonomous driving cars. We proposed an RL algorithm that estimates the hidden states by end-to-end training, and visualize the estimation as a state-transition graph. Experimental results demonstrated that the proposed algorithm can solve simple POMDP problems and that the visualization makes the agent's behavior interpretable to humans.
Pgx: Hardware-accelerated parallel game simulation for reinforcement learning
Mar 29, 2023
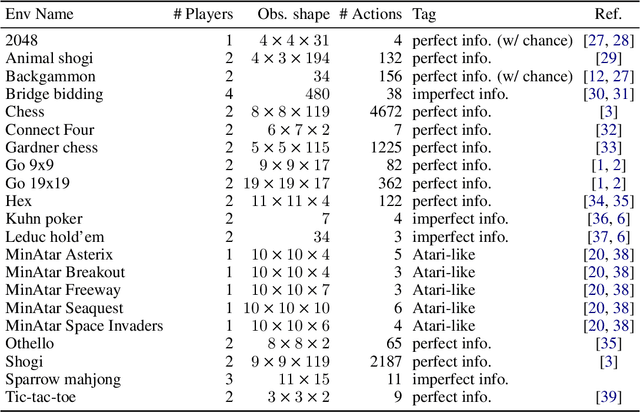


We propose Pgx, a collection of board game simulators written in JAX. Thanks to auto-vectorization and Just-In-Time compilation of JAX, Pgx scales easily to thousands of parallel execution on GPU/TPU accelerators. We found that the simulation of Pgx on a single A100 GPU is 10x faster than that of existing reinforcement learning libraries. Pgx implements games considered vital benchmarks in artificial intelligence research, such as Backgammon, Shogi, and Go. Pgx is available at https://github.com/sotetsuk/pgx.
EEGFuseNet: Hybrid Unsupervised Deep Feature Characterization and Fusion for High-Dimensional EEG with An Application to Emotion Recognition
Feb 07, 2021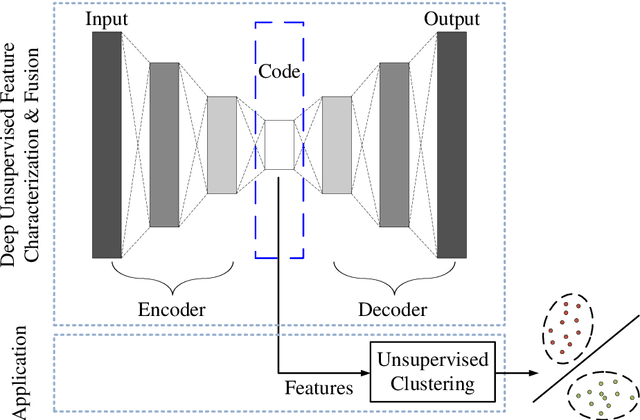
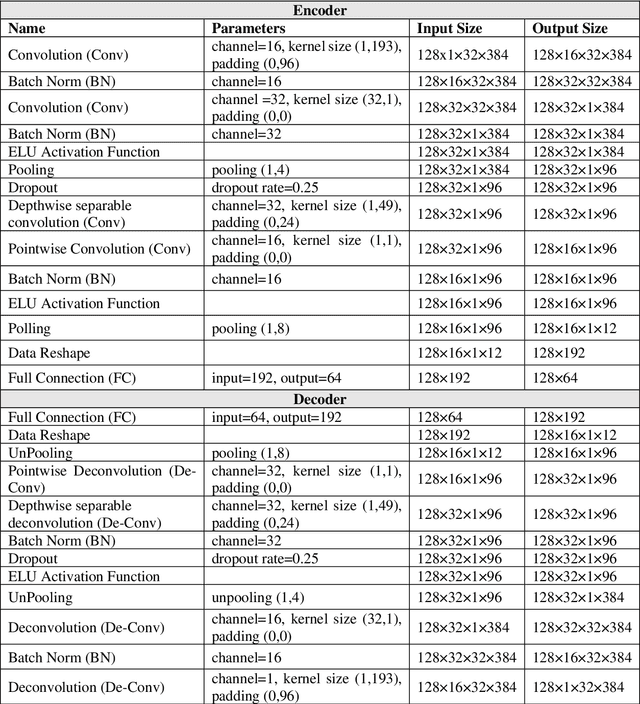
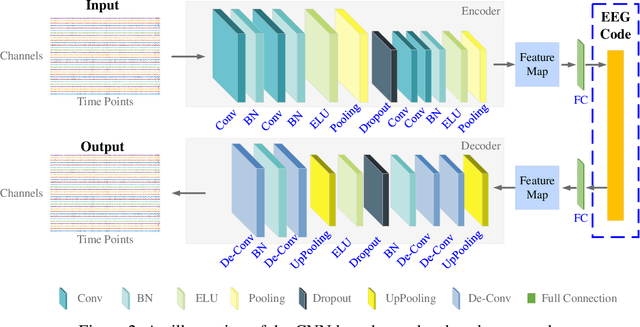
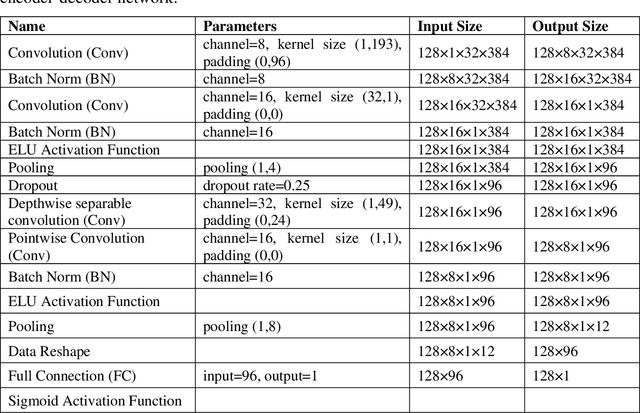
How to effectively and efficiently extract valid and reliable features from high-dimensional electroencephalography (EEG), particularly how to fuse the spatial and temporal dynamic brain information into a better feature representation, is a critical issue in brain data analysis. Most current EEG studies are working on handcrafted features with a supervised modeling, which would be limited by experience and human feedbacks to a great extent. In this paper, we propose a practical hybrid unsupervised deep CNN-RNN-GAN based EEG feature characterization and fusion model, which is termed as EEGFuseNet. EEGFuseNet is trained in an unsupervised manner, and deep EEG features covering spatial and temporal dynamics are automatically characterized. Comparing to the handcrafted features, the deep EEG features could be considered to be more generic and independent of any specific EEG task. The performance of the extracted deep and low-dimensional features by EEGFuseNet is carefully evaluated in an unsupervised emotion recognition application based on a famous public emotion database. The results demonstrate the proposed EEGFuseNet is a robust and reliable model, which is easy to train and manage and perform efficiently in the representation and fusion of dynamic EEG features. In particular, EEGFuseNet is established as an optimal unsupervised fusion model with promising subject-based leave-one-out results in the recognition of four emotion dimensions (valence, arousal, dominance and liking), which demonstrates the possibility of realizing EEG based cross-subject emotion recognition in a pure unsupervised manner.
MarmoNet: a pipeline for automated projection mapping of the common marmoset brain from whole-brain serial two-photon tomography
Aug 02, 2019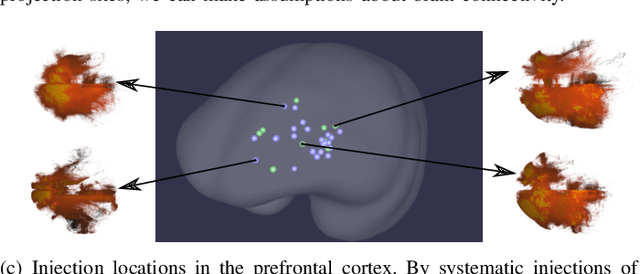
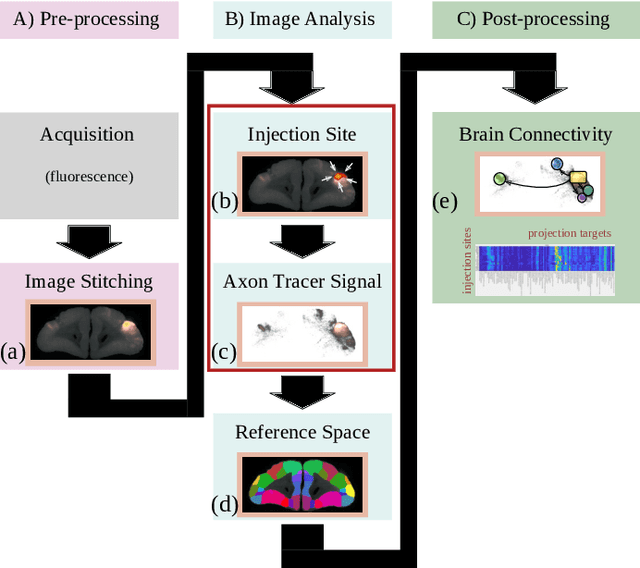

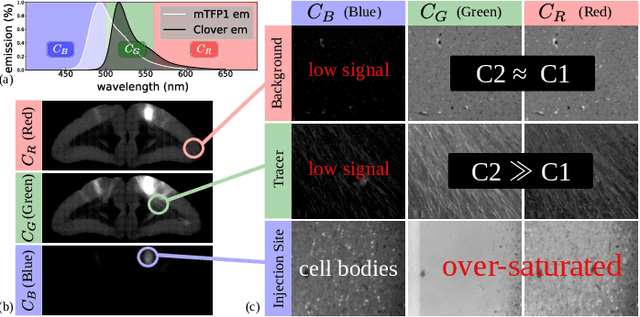
Understanding the connectivity in the brain is an important prerequisite for understanding how the brain processes information. In the Brain/MINDS project, a connectivity study on marmoset brains uses two-photon microscopy fluorescence images of axonal projections to collect the neuron connectivity from defined brain regions at the mesoscopic scale. The processing of the images requires the detection and segmentation of the axonal tracer signal. The objective is to detect as much tracer signal as possible while not misclassifying other background structures as the signal. This can be challenging because of imaging noise, a cluttered image background, distortions or varying image contrast cause problems. We are developing MarmoNet, a pipeline that processes and analyzes tracer image data of the common marmoset brain. The pipeline incorporates state-of-the-art machine learning techniques based on artificial convolutional neural networks (CNN) and image registration techniques to extract and map all relevant information in a robust manner. The pipeline processes new images in a fully automated way. This report introduces the current state of the tracer signal analysis part of the pipeline.
Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning
Jun 27, 2018



We propose a new regularization method based on virtual adversarial loss: a new measure of local smoothness of the conditional label distribution given input. Virtual adversarial loss is defined as the robustness of the conditional label distribution around each input data point against local perturbation. Unlike adversarial training, our method defines the adversarial direction without label information and is hence applicable to semi-supervised learning. Because the directions in which we smooth the model are only "virtually" adversarial, we call our method virtual adversarial training (VAT). The computational cost of VAT is relatively low. For neural networks, the approximated gradient of virtual adversarial loss can be computed with no more than two pairs of forward- and back-propagations. In our experiments, we applied VAT to supervised and semi-supervised learning tasks on multiple benchmark datasets. With a simple enhancement of the algorithm based on the entropy minimization principle, our VAT achieves state-of-the-art performance for semi-supervised learning tasks on SVHN and CIFAR-10.
Efficient Diverse Ensemble for Discriminative Co-Tracking
Jun 07, 2018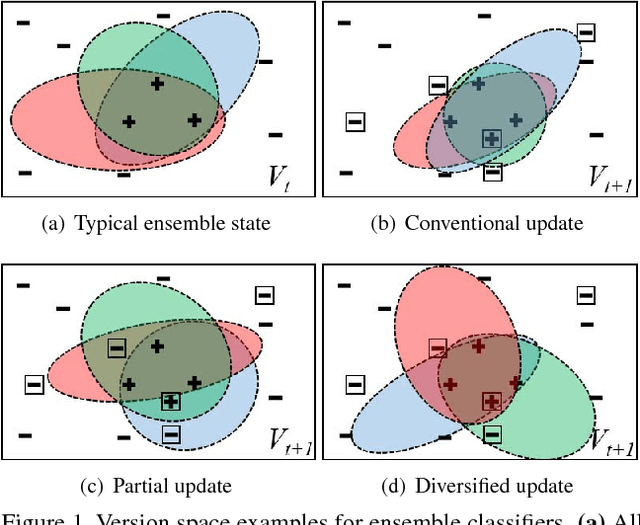
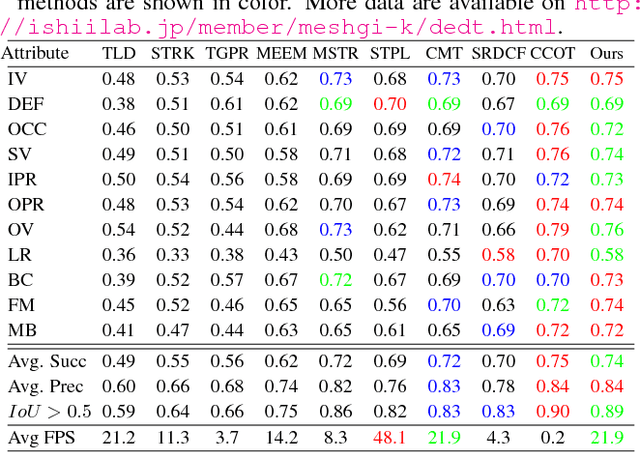
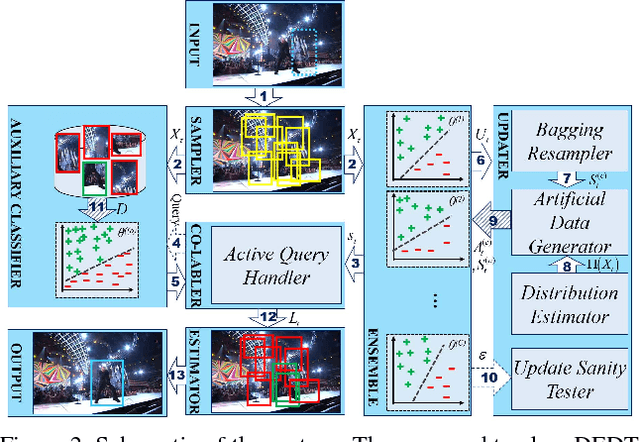
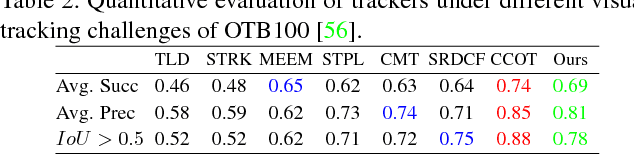
Ensemble discriminative tracking utilizes a committee of classifiers, to label data samples, which are in turn, used for retraining the tracker to localize the target using the collective knowledge of the committee. Committee members could vary in their features, memory update schemes, or training data, however, it is inevitable to have committee members that excessively agree because of large overlaps in their version space. To remove this redundancy and have an effective ensemble learning, it is critical for the committee to include consistent hypotheses that differ from one-another, covering the version space with minimum overlaps. In this study, we propose an online ensemble tracker that directly generates a diverse committee by generating an efficient set of artificial training. The artificial data is sampled from the empirical distribution of the samples taken from both target and background, whereas the process is governed by query-by-committee to shrink the overlap between classifiers. The experimental results demonstrate that the proposed scheme outperforms conventional ensemble trackers on public benchmarks.