 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabRet: Pre-training Transformer-based Tabular Models for Unseen Columns
Paper and Code
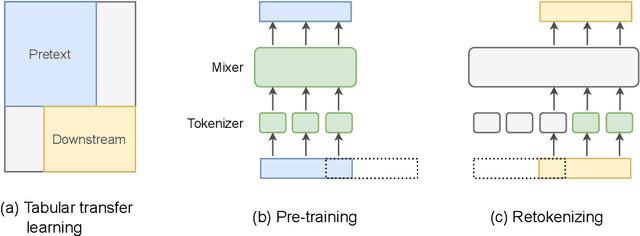
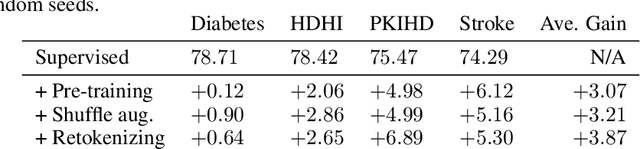
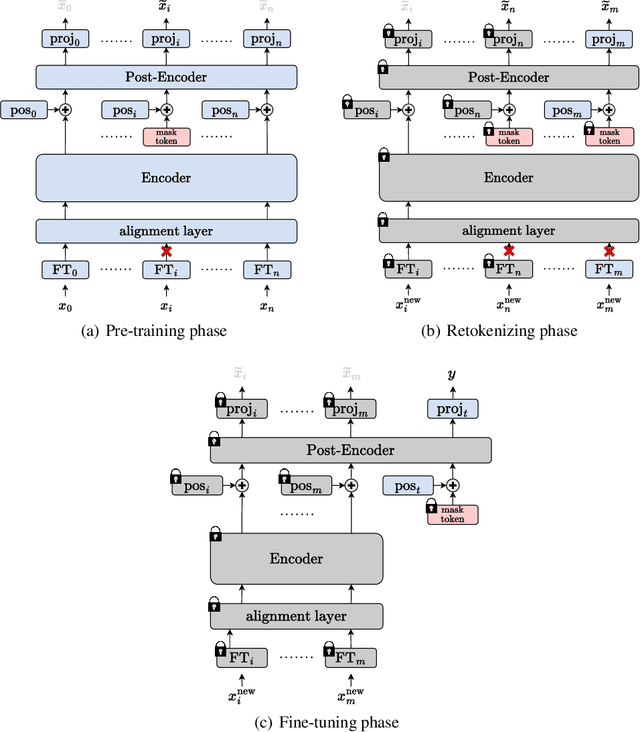
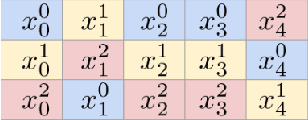
We present \emph{TabRet}, a pre-trainable Transformer-based model for tabular data. TabRet is designed to work on a downstream task that contains columns not seen in pre-training. Unlike other methods, TabRet has an extra learning step before fine-tuning called \emph{retokenizing}, which calibrates feature embeddings based on the masked autoencoding loss. In experiments, we pre-trained TabRet with a large collection of public health surveys and fine-tuned it on classification tasks in healthcare, and TabRet achieved the best AUC performance on four datasets. In addition, an ablation study shows retokenizing and random shuffle augmentation of columns during pre-training contributed to performance gains. The code is available at https://github.com/pfnet-research/tabret .