 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Neural Reward Models Learn Features for Policy Optimization: A Single-Index Analysis
May 23, 2026Reward modeling is not only a prediction problem: in KL-regularized policy optimization, the learned reward is exponentiated to define the deployed policy, so downstream value depends on errors in reward-tilted regions. We study this feedback in a Gaussian single-index model with $r^*(x) = σ^*(\langle θ^*, x\rangle)$ and $x \sim N(0, I_d)$. We analyze a two-stage neural reward model that first learns the hidden direction $θ^*$ from reward-weighted samples and then fits the readout layer by weighted ridge regression. Exponential reward weighting changes the Hermite signal available to the first layer; for any feature-learning temperature $β_1$ above a dimension-free $O(1)$ threshold, a constant fraction of neurons recover the hidden direction, with weak-recovery complexity governed by the generative exponent. After feature recovery, we derive tilted-policy value-gap bounds for an idealized label-weighted fit with weights $e^{y/β_2}$ and a more practical surrogate-weighted fit with weights $e^{r_{a_0}(x)/β_2}$. Keeping the $β_2$-dependence explicit yields an admissible set of deployment temperatures, balancing the gain from lowering $β_2$ against the learning cost amplified by exponential weighting; in the surrogate-weighted case, proxy-dependent factors shrink this admissible set.
Transformers as Measure-Theoretic Associative Memory: A Statistical Perspective and Minimax Optimality
Feb 02, 2026Transformers excel through content-addressable retrieval and the ability to exploit contexts of, in principle, unbounded length. We recast associative memory at the level of probability measures, treating a context as a distribution over tokens and viewing attention as an integral operator on measures. Concretely, for mixture contexts $ν= I^{-1} \sum_{i=1}^I μ^{(i^*)}$ and a query $x_{\mathrm{q}}(i^*)$, the task decomposes into (i) recall of the relevant component $μ^{(i^*)}$ and (ii) prediction from $(μ_{i^*},x_\mathrm{q})$. We study learned softmax attention (not a frozen kernel) trained by empirical risk minimization and show that a shallow measure-theoretic Transformer composed with an MLP learns the recall-and-predict map under a spectral assumption on the input densities. We further establish a matching minimax lower bound with the same rate exponent (up to multiplicative constants), proving sharpness of the convergence order. The framework offers a principled recipe for designing and analyzing Transformers that recall from arbitrarily long, distributional contexts with provable generalization guarantees.
From Shortcut to Induction Head: How Data Diversity Shapes Algorithm Selection in Transformers
Dec 21, 2025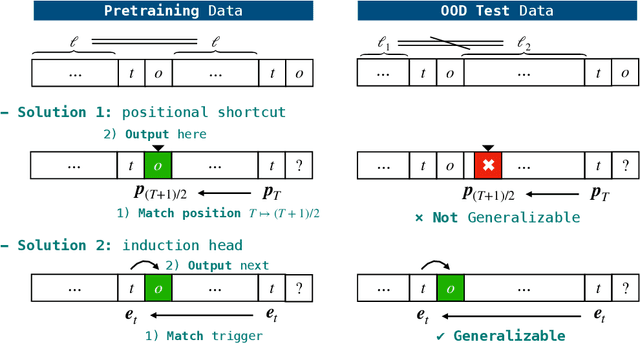
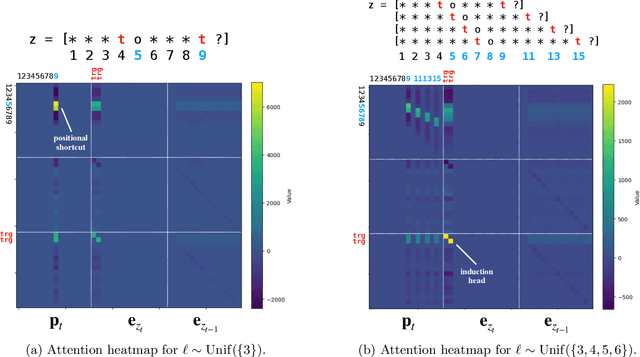
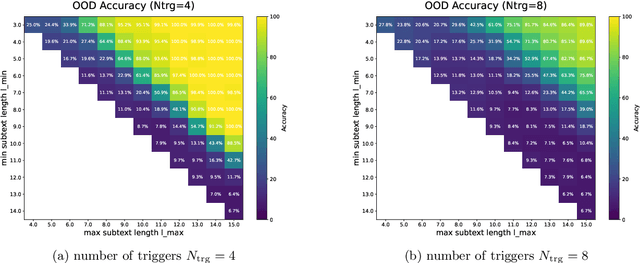
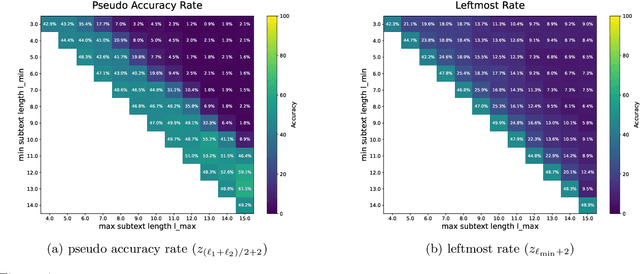
Transformers can implement both generalizable algorithms (e.g., induction heads) and simple positional shortcuts (e.g., memorizing fixed output positions). In this work, we study how the choice of pretraining data distribution steers a shallow transformer toward one behavior or the other. Focusing on a minimal trigger-output prediction task -- copying the token immediately following a special trigger upon its second occurrence -- we present a rigorous analysis of gradient-based training of a single-layer transformer. In both the infinite and finite sample regimes, we prove a transition in the learned mechanism: if input sequences exhibit sufficient diversity, measured by a low ``max-sum'' ratio of trigger-to-trigger distances, the trained model implements an induction head and generalizes to unseen contexts; by contrast, when this ratio is large, the model resorts to a positional shortcut and fails to generalize out-of-distribution (OOD). We also reveal a trade-off between the pretraining context length and OOD generalization, and derive the optimal pretraining distribution that minimizes computational cost per sample. Finally, we validate our theoretical predictions with controlled synthetic experiments, demonstrating that broadening context distributions robustly induces induction heads and enables OOD generalization. Our results shed light on the algorithmic biases of pretrained transformers and offer conceptual guidelines for data-driven control of their learned behaviors.
When Does Metadata Conditioning (NOT) Work for Language Model Pre-Training? A Study with Context-Free Grammars
Apr 24, 2025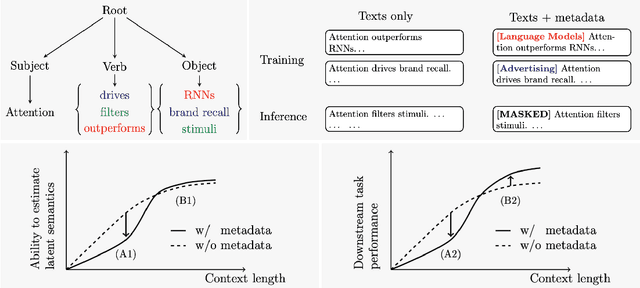
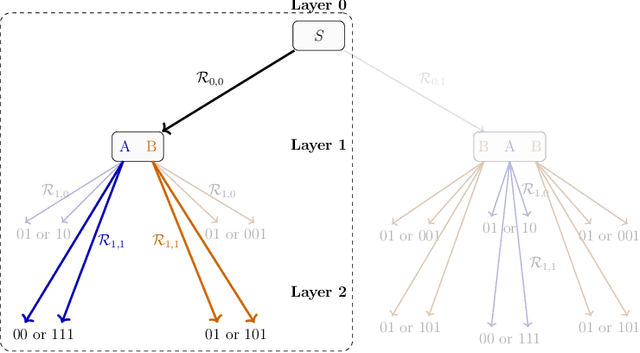
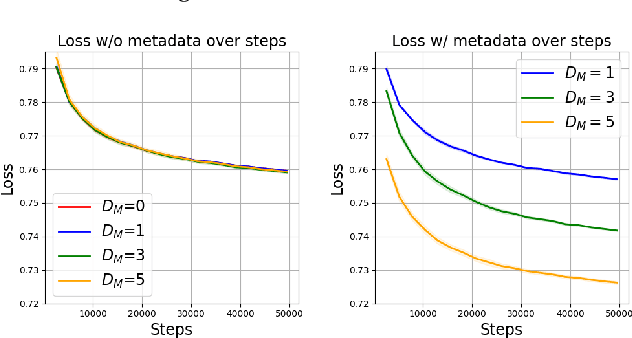

The ability to acquire latent semantics is one of the key properties that determines the performance of language models. One convenient approach to invoke this ability is to prepend metadata (e.g. URLs, domains, and styles) at the beginning of texts in the pre-training data, making it easier for the model to access latent semantics before observing the entire text. Previous studies have reported that this technique actually improves the performance of trained models in downstream tasks; however, this improvement has been observed only in specific downstream tasks, without consistent enhancement in average next-token prediction loss. To understand this phenomenon, we closely investigate how prepending metadata during pre-training affects model performance by examining its behavior using artificial data. Interestingly, we found that this approach produces both positive and negative effects on the downstream tasks. We demonstrate that the effectiveness of the approach depends on whether latent semantics can be inferred from the downstream task's prompt. Specifically, through investigations using data generated by probabilistic context-free grammars, we show that training with metadata helps improve model's performance when the given context is long enough to infer the latent semantics. In contrast, the technique negatively impacts performance when the context lacks the necessary information to make an accurate posterior inference.
Direct Distributional Optimization for Provable Alignment of Diffusion Models
Feb 05, 2025



We introduce a novel alignment method for diffusion models from distribution optimization perspectives while providing rigorous convergence guarantees. We first formulate the problem as a generic regularized loss minimization over probability distributions and directly optimize the distribution using the Dual Averaging method. Next, we enable sampling from the learned distribution by approximating its score function via Doob's $h$-transform technique. The proposed framework is supported by rigorous convergence guarantees and an end-to-end bound on the sampling error, which imply that when the original distribution's score is known accurately, the complexity of sampling from shifted distributions is independent of isoperimetric conditions. This framework is broadly applicable to general distribution optimization problems, including alignment tasks in Reinforcement Learning with Human Feedback (RLHF), Direct Preference Optimization (DPO), and Kahneman-Tversky Optimization (KTO). We empirically validate its performance on synthetic and image datasets using the DPO objective.