 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Neural Surface Reconstruction with Structured Light
Nov 22, 2022



Three-dimensional (3D) object reconstruction based on differentiable rendering (DR) is an active research topic in computer vision. DR-based methods minimize the difference between the rendered and target images by optimizing both the shape and appearance and realizing a high visual reproductivity. However, most approaches perform poorly for textureless objects because of the geometrical ambiguity, which means that multiple shapes can have the same rendered result in such objects. To overcome this problem, we introduce active sensing with structured light (SL) into multi-view 3D object reconstruction based on DR to learn the unknown geometry and appearance of arbitrary scenes and camera poses. More specifically, our framework leverages the correspondences between pixels in different views calculated by structured light as an additional constraint in the DR-based optimization of implicit surface, color representations, and camera poses. Because camera poses can be optimized simultaneously, our method realizes high reconstruction accuracy in the textureless region and reduces efforts for camera pose calibration, which is required for conventional SL-based methods. Experiment results on both synthetic and real data demonstrate that our system outperforms conventional DR- and SL-based methods in a high-quality surface reconstruction, particularly for challenging objects with textureless or shiny surfaces.
Decomposing NeRF for Editing via Feature Field Distillation
May 31, 2022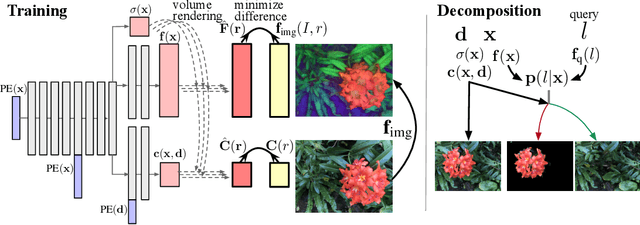



Emerging neural radiance fields (NeRF) are a promising scene representation for computer graphics, enabling high-quality 3D reconstruction and novel view synthesis from image observations. However, editing a scene represented by a NeRF is challenging, as the underlying connectionist representations such as MLPs or voxel grids are not object-centric or compositional. In particular, it has been difficult to selectively edit specific regions or objects. In this work, we tackle the problem of semantic scene decomposition of NeRFs to enable query-based local editing of the represented 3D scenes. We propose to distill the knowledge of off-the-shelf, self-supervised 2D image feature extractors such as CLIP-LSeg or DINO into a 3D feature field optimized in parallel to the radiance field. Given a user-specified query of various modalities such as text, an image patch, or a point-and-click selection, 3D feature fields semantically decompose 3D space without the need for re-training and enable us to semantically select and edit regions in the radiance field. Our experiments validate that the distilled feature fields (DFFs) can transfer recent progress in 2D vision and language foundation models to 3D scene representations, enabling convincing 3D segmentation and selective editing of emerging neural graphics representations.
Surface-Aligned Neural Radiance Fields for Controllable 3D Human Synthesis
Jan 05, 2022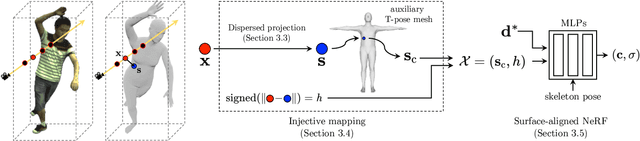
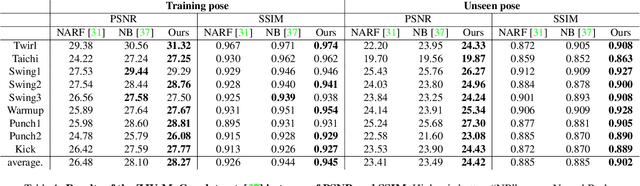
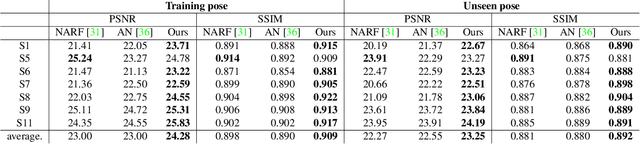
We propose a new method for reconstructing controllable implicit 3D human models from sparse multi-view RGB videos. Our method defines the neural scene representation on the mesh surface points and signed distances from the surface of a human body mesh. We identify an indistinguishability issue that arises when a point in 3D space is mapped to its nearest surface point on a mesh for learning surface-aligned neural scene representation. To address this issue, we propose projecting a point onto a mesh surface using a barycentric interpolation with modified vertex normals. Experiments with the ZJU-MoCap and Human3.6M datasets show that our approach achieves a higher quality in a novel-view and novel-pose synthesis than existing methods. We also demonstrate that our method easily supports the control of body shape and clothes.
Addressing Class Imbalance in Scene Graph Parsing by Learning to Contrast and Score
Oct 05, 2020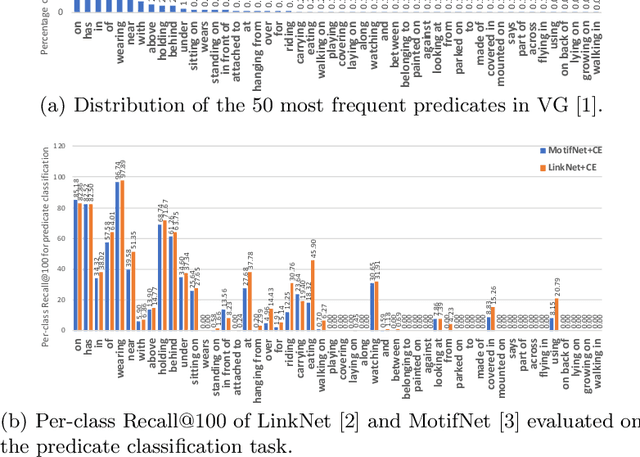
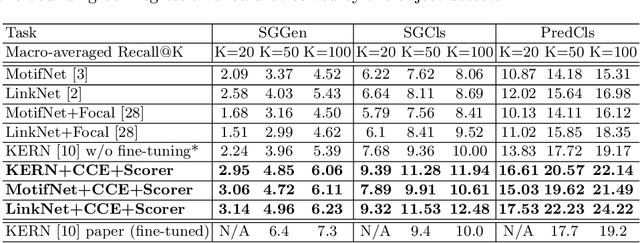
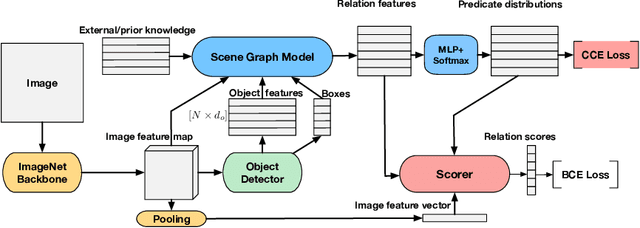
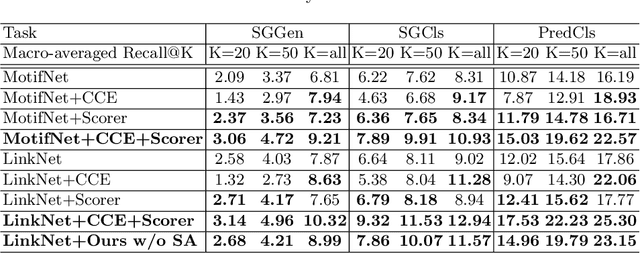
Scene graph parsing aims to detect objects in an image scene and recognize their relations. Recent approaches have achieved high average scores on some popular benchmarks, but fail in detecting rare relations, as the highly long-tailed distribution of data biases the learning towards frequent labels. Motivated by the fact that detecting these rare relations can be critical in real-world applications, this paper introduces a novel integrated framework of classification and ranking to resolve the class imbalance problem in scene graph parsing. Specifically, we design a new Contrasting Cross-Entropy loss, which promotes the detection of rare relations by suppressing incorrect frequent ones. Furthermore, we propose a novel scoring module, termed as Scorer, which learns to rank the relations based on the image features and relation features to improve the recall of predictions. Our framework is simple and effective, and can be incorporated into current scene graph models. Experimental results show that the proposed approach improves the current state-of-the-art methods, with a clear advantage of detecting rare relations.
Map-based Multi-Policy Reinforcement Learning: Enhancing Adaptability of Robots by Deep Reinforcement Learning
Oct 18, 2017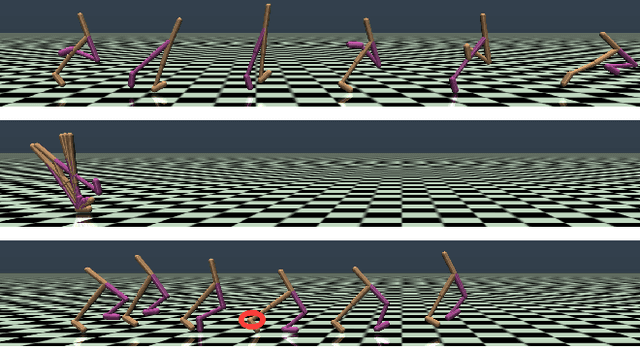
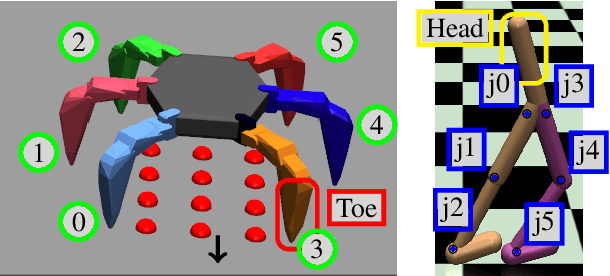

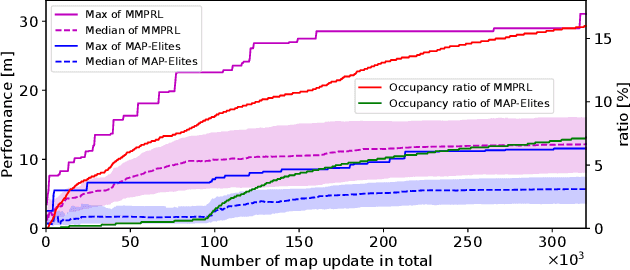
In order for robots to perform mission-critical tasks, it is essential that they are able to quickly adapt to changes in their environment as well as to injuries and or other bodily changes. Deep reinforcement learning has been shown to be successful in training robot control policies for operation in complex environments. However, existing methods typically employ only a single policy. This can limit the adaptability since a large environmental modification might require a completely different behavior compared to the learning environment. To solve this problem, we propose Map-based Multi-Policy Reinforcement Learning (MMPRL), which aims to search and store multiple policies that encode different behavioral features while maximizing the expected reward in advance of the environment change. Thanks to these policies, which are stored into a multi-dimensional discrete map according to its behavioral feature, adaptation can be performed within reasonable time without retraining the robot. An appropriate pre-trained policy from the map can be recalled using Bayesian optimization. Our experiments show that MMPRL enables robots to quickly adapt to large changes without requiring any prior knowledge on the type of injuries that could occur. A highlight of the learned behaviors can be found here: https://youtu.be/QwInbilXNOE .
Temporal Generative Adversarial Nets with Singular Value Clipping
Aug 18, 2017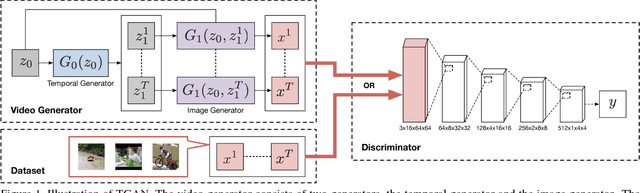
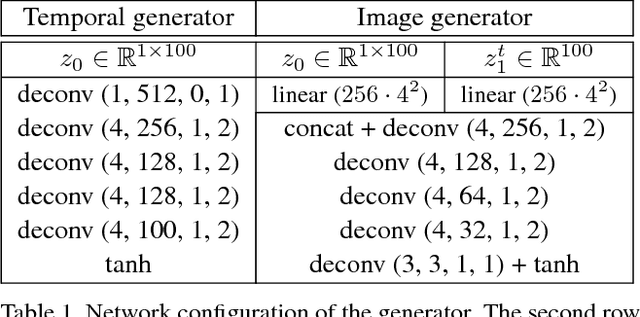


In this paper, we propose a generative model, Temporal Generative Adversarial Nets (TGAN), which can learn a semantic representation of unlabeled videos, and is capable of generating videos. Unlike existing Generative Adversarial Nets (GAN)-based methods that generate videos with a single generator consisting of 3D deconvolutional layers, our model exploits two different types of generators: a temporal generator and an image generator. The temporal generator takes a single latent variable as input and outputs a set of latent variables, each of which corresponds to an image frame in a video. The image generator transforms a set of such latent variables into a video. To deal with instability in training of GAN with such advanced networks, we adopt a recently proposed model, Wasserstein GAN, and propose a novel method to train it stably in an end-to-end manner. The experimental results demonstrate the effectiveness of our methods.
Learning Discrete Representations via Information Maximizing Self-Augmented Training
Jun 14, 2017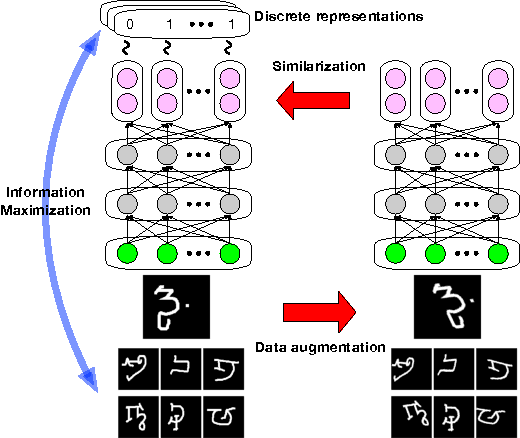
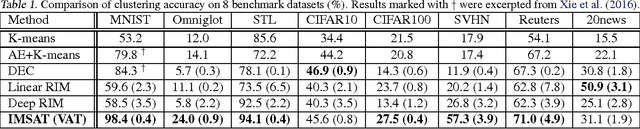


Learning discrete representations of data is a central machine learning task because of the compactness of the representations and ease of interpretation. The task includes clustering and hash learning as special cases. Deep neural networks are promising to be used because they can model the non-linearity of data and scale to large datasets. However, their model complexity is huge, and therefore, we need to carefully regularize the networks in order to learn useful representations that exhibit intended invariance for applications of interest. To this end, we propose a method called Information Maximizing Self-Augmented Training (IMSAT). In IMSAT, we use data augmentation to impose the invariance on discrete representations. More specifically, we encourage the predicted representations of augmented data points to be close to those of the original data points in an end-to-end fashion. At the same time, we maximize the information-theoretic dependency between data and their predicted discrete representations. Extensive experiments on benchmark datasets show that IMSAT produces state-of-the-art results for both clustering and unsupervised hash learning.