 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolMERLIN: Self-Supervised Polarimetric Complex SAR Image Despeckling with Masked Networks
Jan 15, 2024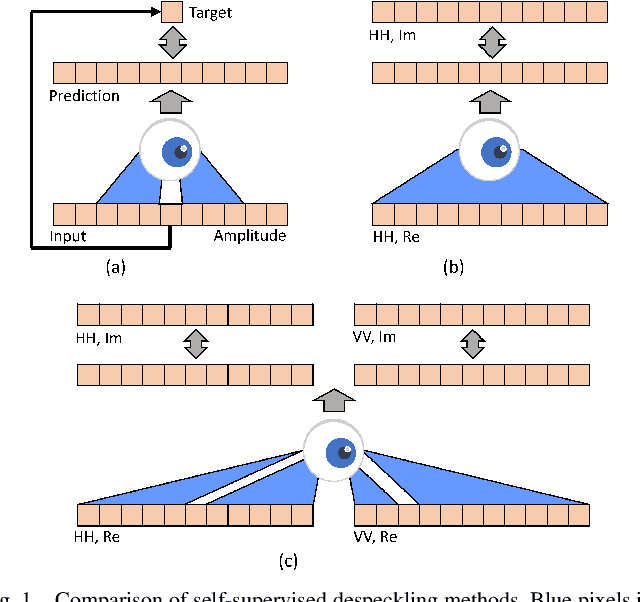
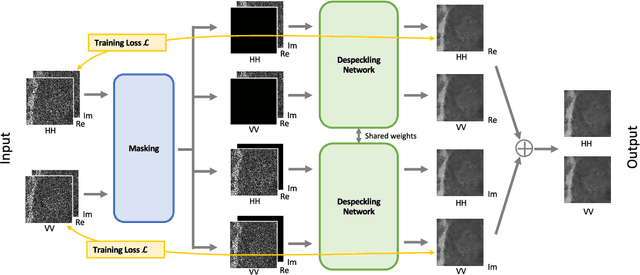


Despeckling is a crucial noise reduction task in improving the quality of synthetic aperture radar (SAR) images. Directly obtaining noise-free SAR images is a challenging task that has hindered the development of accurate despeckling algorithms. The advent of deep learning has facilitated the study of denoising models that learn from only noisy SAR images. However, existing methods deal solely with single-polarization images and cannot handle the multi-polarization images captured by modern satellites. In this work, we present an extension of the existing model for generating single-polarization SAR images to handle multi-polarization SAR images. Specifically, we propose a novel self-supervised despeckling approach called channel masking, which exploits the relationship between polarizations. Additionally, we utilize a spatial masking method that addresses pixel-to-pixel correlations to further enhance the performance of our approach. By effectively incorporating multiple polarization information, our method surpasses current state-of-the-art methods in quantitative evaluation in both synthetic and real-world scenarios.
TGANv2: Efficient Training of Large Models for Video Generation with Multiple Subsampling Layers
Nov 22, 2018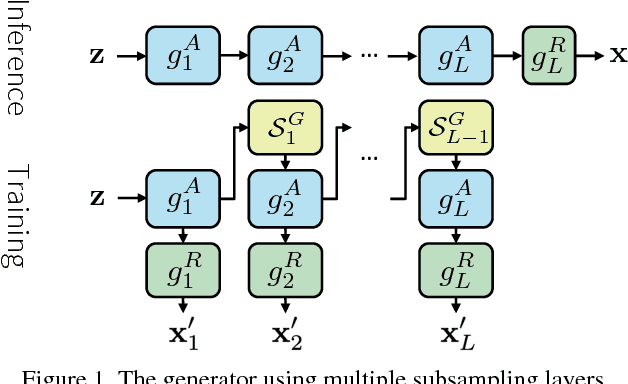
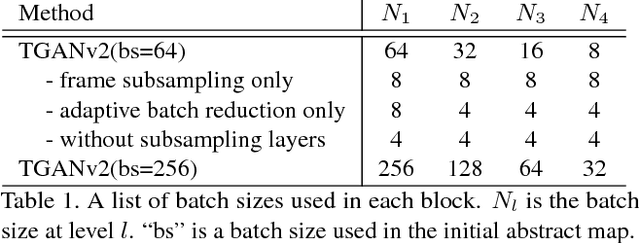
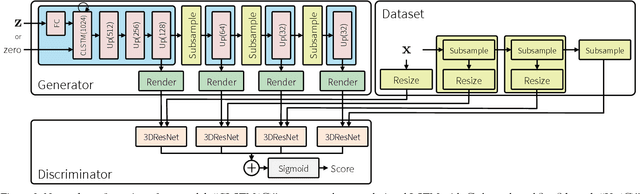

In this paper, we propose a novel method to efficiently train a Generative Adversarial Network (GAN) on high dimensional samples. The key idea is to introduce a differentiable subsampling layer which appropriately reduces the dimensionality of intermediate feature maps in the generator during training. In general, generators require large memory and computational costs in the latter stages of the network as the feature maps become larger, though the latter stages have relatively fewer parameters than the earlier stages. It makes training large models for video generation difficult due to the limited computational resource. We solve this problem by introducing a method that gradually reduces the dimensionality of feature maps in the generator with multiple subsampling layers. We also propose a network (Temporal GAN v2) with such layers and perform video generation experiments. As a consequence, our model trained on the UCF101 dataset at $192 \times 192$ pixels achieves an Inception Score (IS) of 24.34, which shows a significant improvement over the previous state-of-the-art score of 14.56.
ChainerCV: a Library for Deep Learning in Computer Vision
Aug 28, 2017


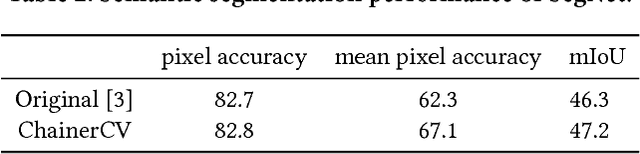
Despite significant progress of deep learning in the field of computer vision, there has not been a software library that covers these methods in a unifying manner. We introduce ChainerCV, a software library that is intended to fill this gap. ChainerCV supports numerous neural network models as well as software components needed to conduct research in computer vision. These implementations emphasize simplicity, flexibility and good software engineering practices. The library is designed to perform on par with the results reported in published papers and its tools can be used as a baseline for future research in computer vision. Our implementation includes sophisticated models like Faster R-CNN and SSD, and covers tasks such as object detection and semantic segmentation.
Temporal Generative Adversarial Nets with Singular Value Clipping
Aug 18, 2017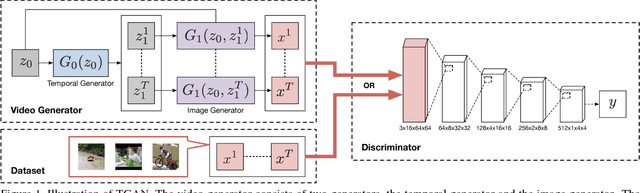
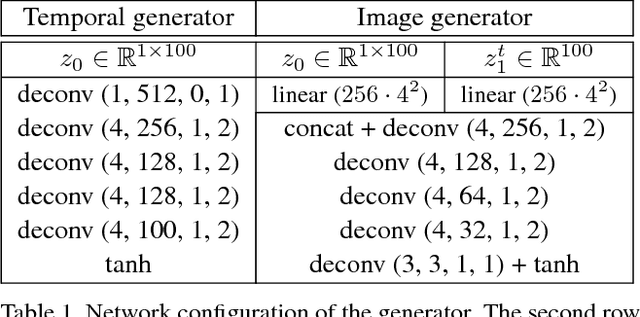


In this paper, we propose a generative model, Temporal Generative Adversarial Nets (TGAN), which can learn a semantic representation of unlabeled videos, and is capable of generating videos. Unlike existing Generative Adversarial Nets (GAN)-based methods that generate videos with a single generator consisting of 3D deconvolutional layers, our model exploits two different types of generators: a temporal generator and an image generator. The temporal generator takes a single latent variable as input and outputs a set of latent variables, each of which corresponds to an image frame in a video. The image generator transforms a set of such latent variables into a video. To deal with instability in training of GAN with such advanced networks, we adopt a recently proposed model, Wasserstein GAN, and propose a novel method to train it stably in an end-to-end manner. The experimental results demonstrate the effectiveness of our methods.