 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolMERLIN: Self-Supervised Polarimetric Complex SAR Image Despeckling with Masked Networks
Jan 15, 2024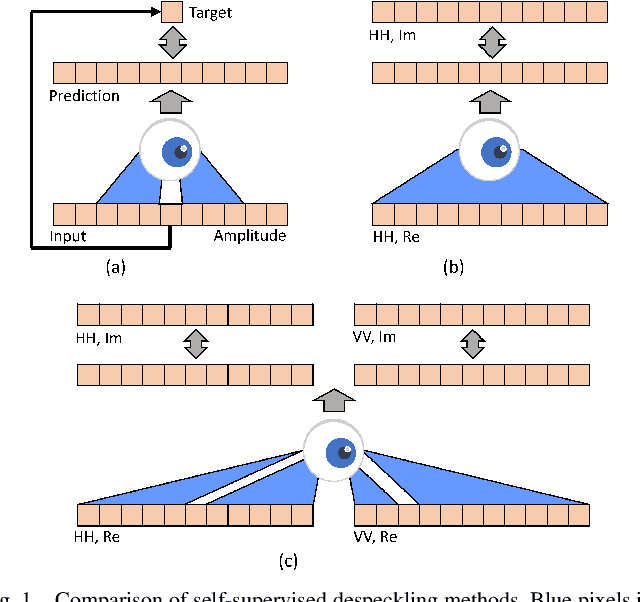
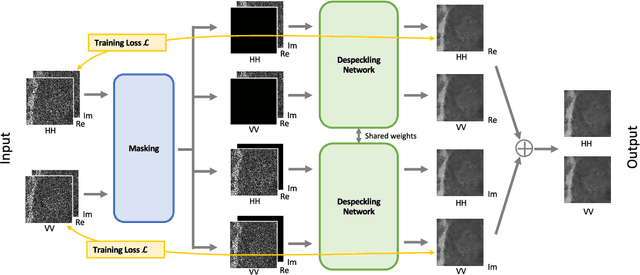


Despeckling is a crucial noise reduction task in improving the quality of synthetic aperture radar (SAR) images. Directly obtaining noise-free SAR images is a challenging task that has hindered the development of accurate despeckling algorithms. The advent of deep learning has facilitated the study of denoising models that learn from only noisy SAR images. However, existing methods deal solely with single-polarization images and cannot handle the multi-polarization images captured by modern satellites. In this work, we present an extension of the existing model for generating single-polarization SAR images to handle multi-polarization SAR images. Specifically, we propose a novel self-supervised despeckling approach called channel masking, which exploits the relationship between polarizations. Additionally, we utilize a spatial masking method that addresses pixel-to-pixel correlations to further enhance the performance of our approach. By effectively incorporating multiple polarization information, our method surpasses current state-of-the-art methods in quantitative evaluation in both synthetic and real-world scenarios.
Data Transfer Approaches to Improve Seq-to-Seq Retrosynthesis
Oct 02, 2020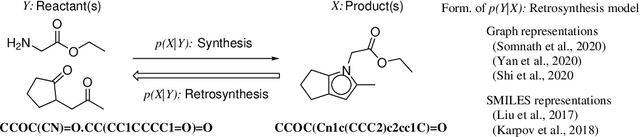

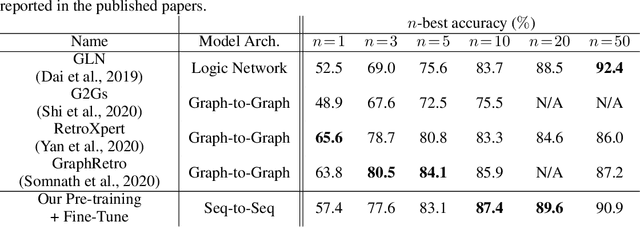
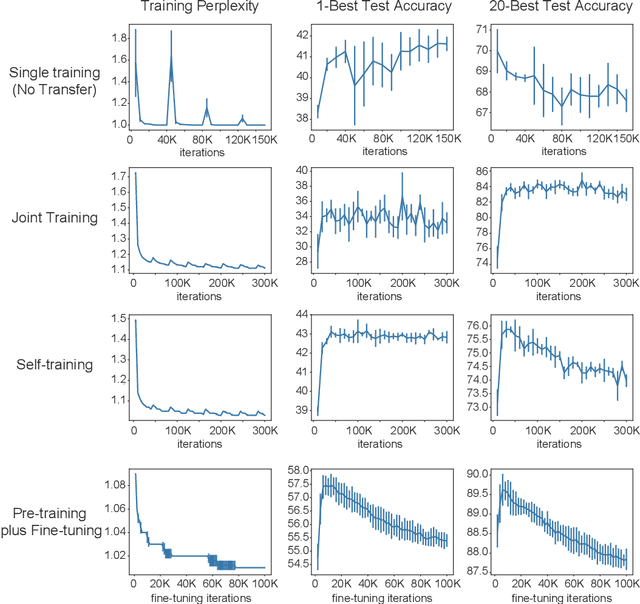
Retrosynthesis is a problem to infer reactant compounds to synthesize a given product compound through chemical reactions. Recent studies on retrosynthesis focus on proposing more sophisticated prediction models, but the dataset to feed the models also plays an essential role in achieving the best generalizing models. Generally, a dataset that is best suited for a specific task tends to be small. In such a case, it is the standard solution to transfer knowledge from a large or clean dataset in the same domain. In this paper, we conduct a systematic and intensive examination of data transfer approaches on end-to-end generative models, in application to retrosynthesis. Experimental results show that typical data transfer methods can improve test prediction scores of an off-the-shelf Transformer baseline model. Especially, the pre-training plus fine-tuning approach boosts the accuracy scores of the baseline, achieving the new state-of-the-art. In addition, we conduct a manual inspection for the erroneous prediction results. The inspection shows that the pre-training plus fine-tuning models can generate chemically appropriate or sensible proposals in almost all cases.
Weisfeiler-Lehman Embedding for Molecular Graph Neural Networks
Jun 12, 2020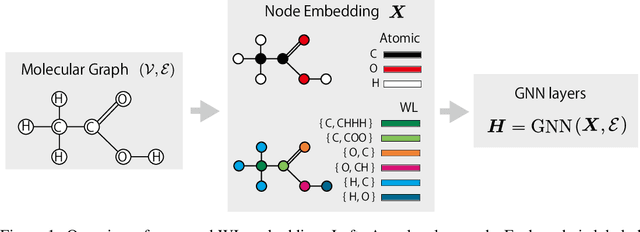
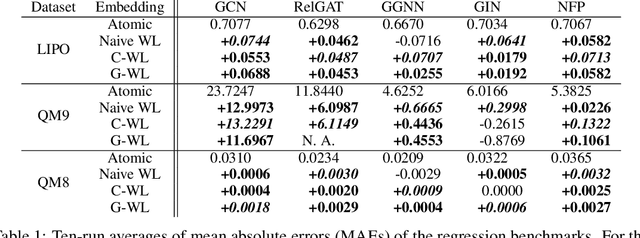
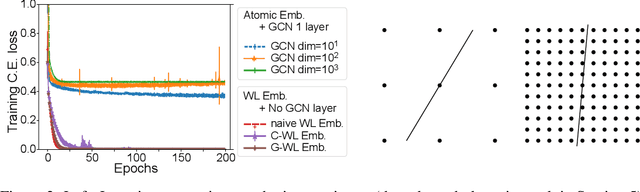
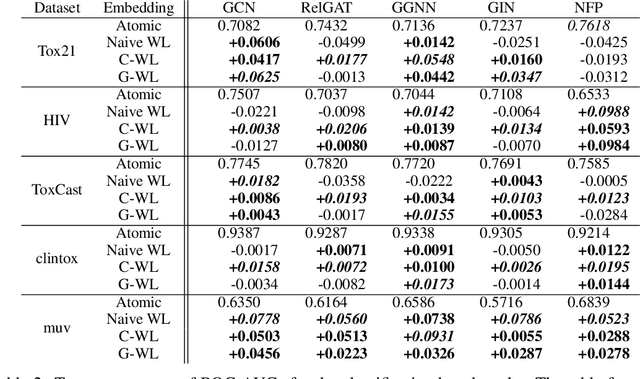
A graph neural network (GNN) is a good choice for predicting the chemical properties of molecules. Compared with other deep networks, however, the current performance of a GNN is limited owing to the "curse of depth." Inspired by long-established feature engineering in the field of chemistry, we expanded an atom representation using Weisfeiler-Lehman (WL) embedding, which is designed to capture local atomic patterns dominating the chemical properties of a molecule. In terms of representability, we show WL embedding can replace the first two layers of ReLU GNN -- a normal embedding and a hidden GNN layer -- with a smaller weight norm. We then demonstrate that WL embedding consistently improves the empirical performance over multiple GNN architectures and several molecular graph datasets.
Graph Residual Flow for Molecular Graph Generation
Sep 30, 2019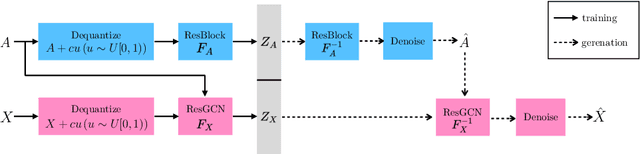
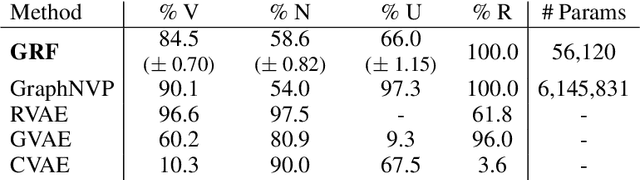
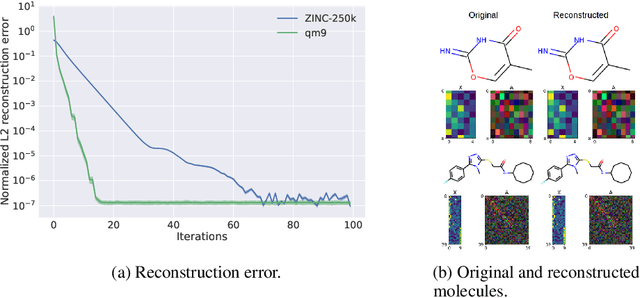
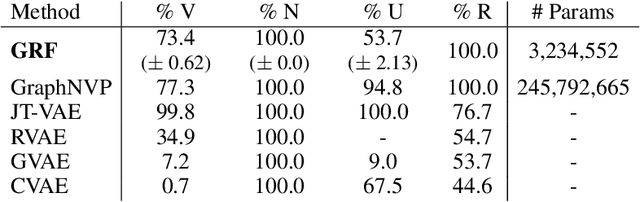
Statistical generative models for molecular graphs attract attention from many researchers from the fields of bio- and chemo-informatics. Among these models, invertible flow-based approaches are not fully explored yet. In this paper, we propose a powerful invertible flow for molecular graphs, called graph residual flow (GRF). The GRF is based on residual flows, which are known for more flexible and complex non-linear mappings than traditional coupling flows. We theoretically derive non-trivial conditions such that GRF is invertible, and present a way of keeping the entire flows invertible throughout the training and sampling. Experimental results show that a generative model based on the proposed GRF achieves comparable generation performance, with much smaller number of trainable parameters compared to the existing flow-based model.
Graph Warp Module: an Auxiliary Module for Boosting the Power of Graph Neural Networks
Apr 02, 2019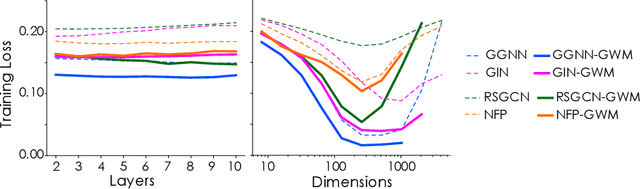

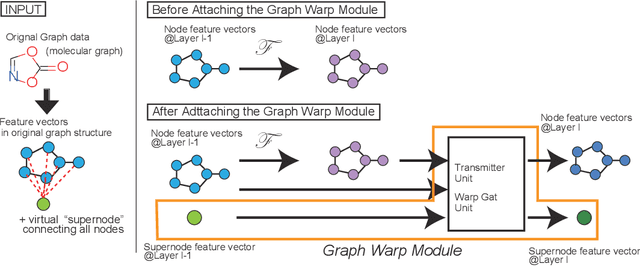
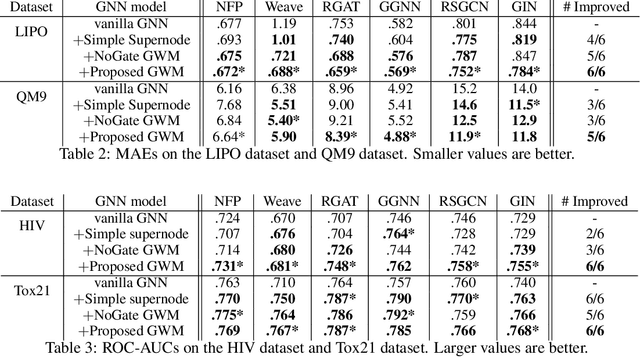
Recently, Graph Neural Networks (GNNs) are trending in the machine learning community as a family of architectures that specializes in capturing the features of graph-related datasets, such as those pertaining to social networks and chemical structures. Unlike for other families of the networks, the representation power of GNNs has much room for improvement, and many graph networks to date suffer from the problem of underfitting. In this paper we will introduce a Graph Warp Module, a supernode-based auxiliary network module that can be attached to a wide variety of existing GNNs in order to improve the representation power of the original networks. Through extensive experiments on molecular graph datasets, we will show that our GWM indeed alleviates the underfitting problem for various existing networks, and that it can even help create a network with the state-of-the-art generalization performance.
Collapsed Variational Bayes Inference of Infinite Relational Model
Sep 16, 2014
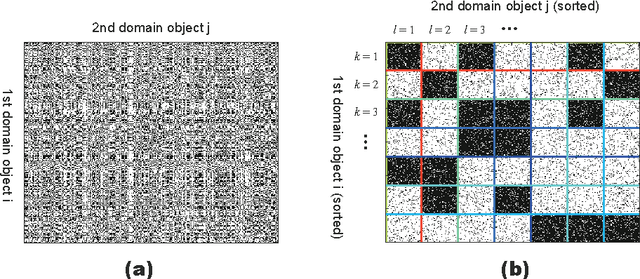
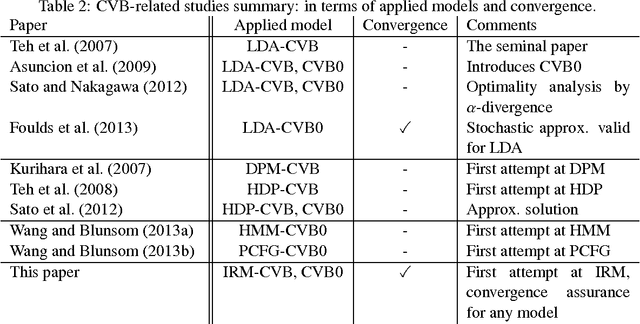

The Infinite Relational Model (IRM) is a probabilistic model for relational data clustering that partitions objects into clusters based on observed relationships. This paper presents Averaged CVB (ACVB) solutions for IRM, convergence-guaranteed and practically useful fast Collapsed Variational Bayes (CVB) inferences. We first derive ordinary CVB and CVB0 for IRM based on the lower bound maximization. CVB solutions yield deterministic iterative procedures for inferring IRM given the truncated number of clusters. Our proposal includes CVB0 updates of hyperparameters including the concentration parameter of the Dirichlet Process, which has not been studied in the literature. To make the CVB more practically useful, we further study the CVB inference in two aspects. First, we study the convergence issues and develop a convergence-guaranteed algorithm for any CVB-based inferences called ACVB, which enables automatic convergence detection and frees non-expert practitioners from difficult and costly manual monitoring of inference processes. Second, we present a few techniques for speeding up IRM inferences. In particular, we describe the linear time inference of CVB0, allowing the IRM for larger relational data uses. The ACVB solutions of IRM showed comparable or better performance compared to existing inference methods in experiments, and provide deterministic, faster, and easier convergence detection.