 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Transfer Approaches to Improve Seq-to-Seq Retrosynthesis
Oct 02, 2020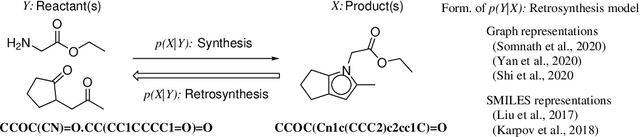

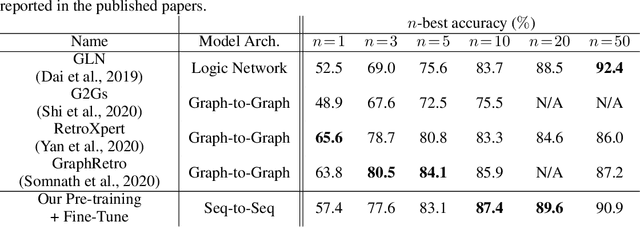
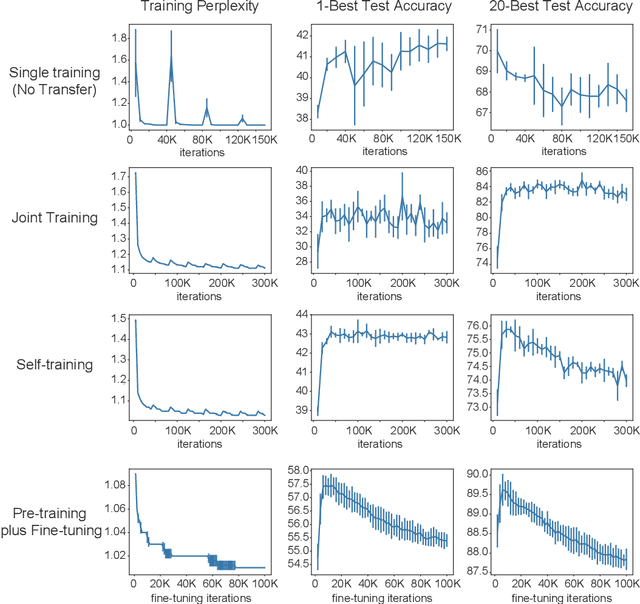
Retrosynthesis is a problem to infer reactant compounds to synthesize a given product compound through chemical reactions. Recent studies on retrosynthesis focus on proposing more sophisticated prediction models, but the dataset to feed the models also plays an essential role in achieving the best generalizing models. Generally, a dataset that is best suited for a specific task tends to be small. In such a case, it is the standard solution to transfer knowledge from a large or clean dataset in the same domain. In this paper, we conduct a systematic and intensive examination of data transfer approaches on end-to-end generative models, in application to retrosynthesis. Experimental results show that typical data transfer methods can improve test prediction scores of an off-the-shelf Transformer baseline model. Especially, the pre-training plus fine-tuning approach boosts the accuracy scores of the baseline, achieving the new state-of-the-art. In addition, we conduct a manual inspection for the erroneous prediction results. The inspection shows that the pre-training plus fine-tuning models can generate chemically appropriate or sensible proposals in almost all cases.
Extractive Summarization via Weighted Dissimilarity and Importance Aligned Key Iterative Algorithm
May 15, 2019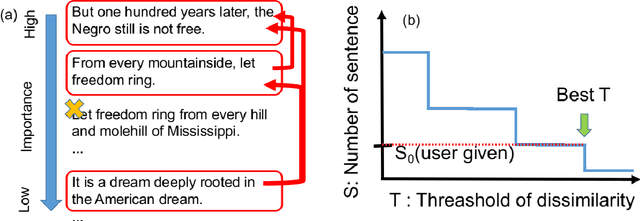

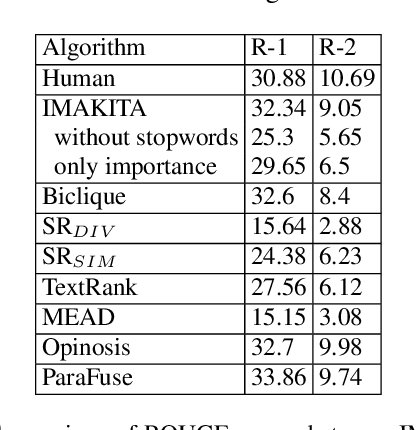
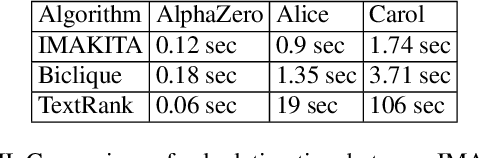
We present importance aligned key iterative algorithm for extractive summarization that is faster than conventional algorithms keeping its accuracy. The computational complexity of our algorithm is O($SNlogN$) to summarize original $N$ sentences into final $S$ sentences. Our algorithm maximizes the weighted dissimilarity defined by the product of importance and cosine dissimilarity so that the summary represents the document and at the same time the sentences of the summary are not similar to each other. The weighted dissimilarity is heuristically maximized by iterative greedy search and binary search to the sentences ordered by importance. We finally show a benchmark score based on summarization of customer reviews of products, which highlights the quality of our algorithm comparable to human and existing algorithms. We provide the source code of our algorithm on github https://github.com/qhapaq-49/imakita .