 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtractive Summarization via Weighted Dissimilarity and Importance Aligned Key Iterative Algorithm
Paper and Code
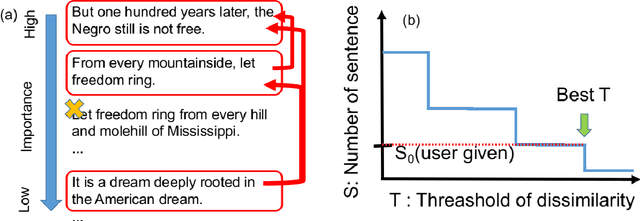

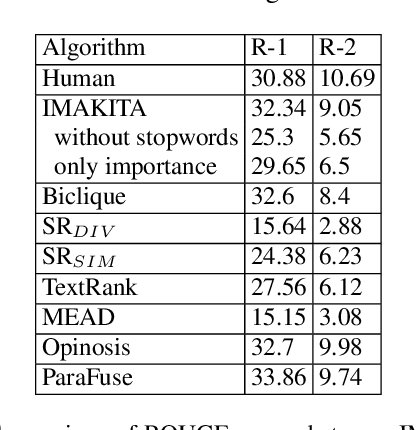
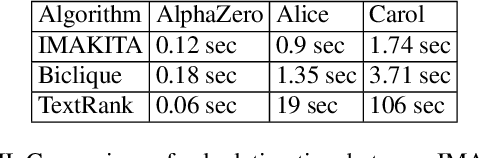
We present importance aligned key iterative algorithm for extractive summarization that is faster than conventional algorithms keeping its accuracy. The computational complexity of our algorithm is O($SNlogN$) to summarize original $N$ sentences into final $S$ sentences. Our algorithm maximizes the weighted dissimilarity defined by the product of importance and cosine dissimilarity so that the summary represents the document and at the same time the sentences of the summary are not similar to each other. The weighted dissimilarity is heuristically maximized by iterative greedy search and binary search to the sentences ordered by importance. We finally show a benchmark score based on summarization of customer reviews of products, which highlights the quality of our algorithm comparable to human and existing algorithms. We provide the source code of our algorithm on github https://github.com/qhapaq-49/imakita .