 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion Generation Considering Situation with Conditional Generative Adversarial Networks for Throwing Robots
Oct 08, 2019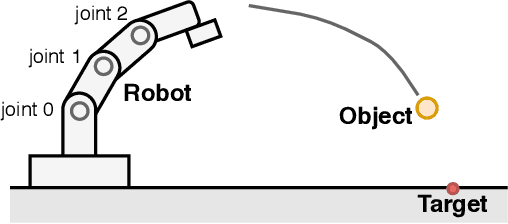


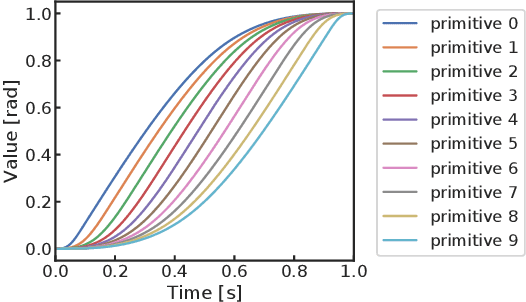
When robots work in a cluttered environment, the constraints for motions change frequently and the required action can change even for the same task. However, planning complex motions from direct calculation has the risk of resulting in poor performance local optima. In addition, machine learning approaches often require relearning for novel situations. In this paper, we propose a method of searching appropriate motions by using conditional Generative Adversarial Networks (cGANs), which can generate motions based on the conditions by mimicking training datasets. By training cGANs with various motions for a task, its latent space is fulfilled with the valid motions for the task. The appropriate motions can be found efficiently by searching the latent space of the trained cGANs instead of the motion space, while avoiding poor local optima. We demonstrate that the proposed method successfully works for an object-throwing task to given target positions in both numerical simulation and real-robot experiments. The proposed method resulted in three times higher accuracy with 2.5 times faster calculation time than searching the action space directly.
Map-based Multi-Policy Reinforcement Learning: Enhancing Adaptability of Robots by Deep Reinforcement Learning
Oct 18, 2017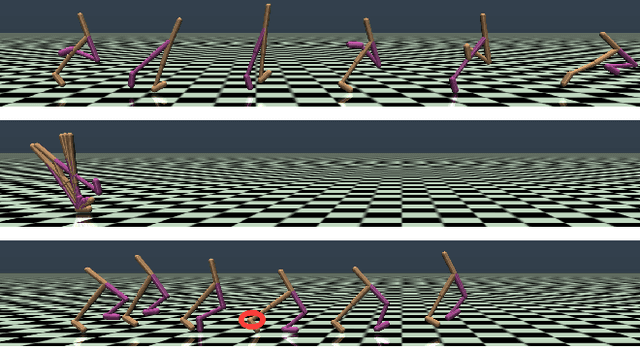
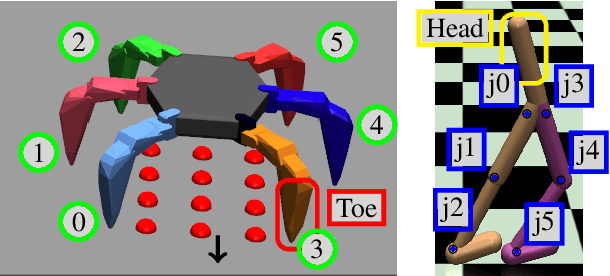

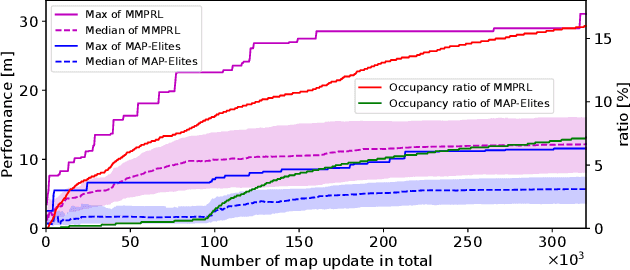
In order for robots to perform mission-critical tasks, it is essential that they are able to quickly adapt to changes in their environment as well as to injuries and or other bodily changes. Deep reinforcement learning has been shown to be successful in training robot control policies for operation in complex environments. However, existing methods typically employ only a single policy. This can limit the adaptability since a large environmental modification might require a completely different behavior compared to the learning environment. To solve this problem, we propose Map-based Multi-Policy Reinforcement Learning (MMPRL), which aims to search and store multiple policies that encode different behavioral features while maximizing the expected reward in advance of the environment change. Thanks to these policies, which are stored into a multi-dimensional discrete map according to its behavioral feature, adaptation can be performed within reasonable time without retraining the robot. An appropriate pre-trained policy from the map can be recalled using Bayesian optimization. Our experiments show that MMPRL enables robots to quickly adapt to large changes without requiring any prior knowledge on the type of injuries that could occur. A highlight of the learned behaviors can be found here: https://youtu.be/QwInbilXNOE .