 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssembly robots with optimized control stiffness through reinforcement learning
Feb 27, 2020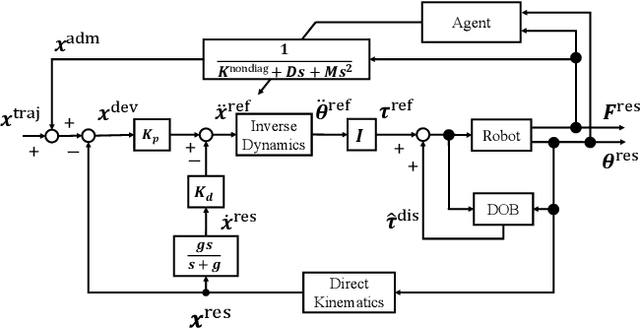
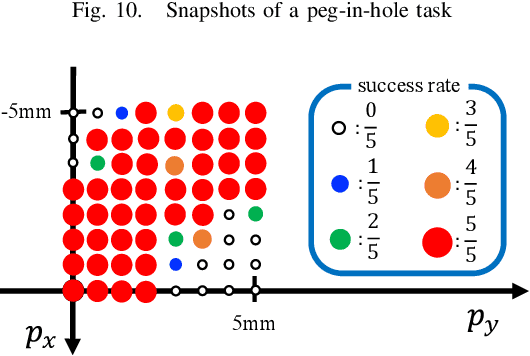
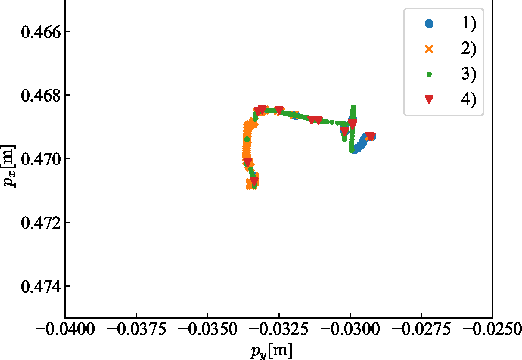
There is an increased demand for task automation in robots. Contact-rich tasks, wherein multiple contact transitions occur in a series of operations, are extensively being studied to realize high accuracy. In this study, we propose a methodology that uses reinforcement learning (RL) to achieve high performance in robots for the execution of assembly tasks that require precise contact with objects without causing damage. The proposed method ensures the online generation of stiffness matrices that help improve the performance of local trajectory optimization. The method has an advantage of rapid response owing to short sampling time of the trajectory planning. The effectiveness of the method was verified via experiments involving two contact-rich tasks. The results indicate that the proposed method can be implemented in various contact-rich manipulations. A demonstration video shows the performance. (https://youtu.be/gxSCl7Tp4-0)
Motion Generation Considering Situation with Conditional Generative Adversarial Networks for Throwing Robots
Oct 08, 2019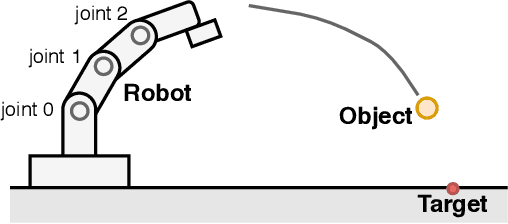


When robots work in a cluttered environment, the constraints for motions change frequently and the required action can change even for the same task. However, planning complex motions from direct calculation has the risk of resulting in poor performance local optima. In addition, machine learning approaches often require relearning for novel situations. In this paper, we propose a method of searching appropriate motions by using conditional Generative Adversarial Networks (cGANs), which can generate motions based on the conditions by mimicking training datasets. By training cGANs with various motions for a task, its latent space is fulfilled with the valid motions for the task. The appropriate motions can be found efficiently by searching the latent space of the trained cGANs instead of the motion space, while avoiding poor local optima. We demonstrate that the proposed method successfully works for an object-throwing task to given target positions in both numerical simulation and real-robot experiments. The proposed method resulted in three times higher accuracy with 2.5 times faster calculation time than searching the action space directly.