 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-fingered Hand with Gear-type Synchronization Mechanism with Magnet for Improved Small and Offset Objects Grasping: F2 Hand
Sep 20, 2023



A problem that plagues robotic grasping is the misalignment of the object and gripper due to difficulties in precise localization, actuation, etc. Under-actuated robotic hands with compliant mechanisms are used to adapt and compensate for these inaccuracies. However, these mechanisms come at the cost of controllability and coordination. For instance, adaptive functions that let the fingers of a two-fingered gripper adapt independently may affect the coordination necessary for grasping small objects. In this work, we develop a two-fingered robotic hand capable of grasping objects that are offset from the gripper's center, while still having the requisite coordination for grasping small objects via a novel gear-type synchronization mechanism with a magnet. This gear synchronization mechanism allows the adaptive finger's tips to be aligned enabling it to grasp objects as small as toothpicks and washers. The magnetic component allows this coordination to automatically turn off when needed, allowing for the grasping of objects that are offset/misaligned from the gripper. This equips the hand with the capability of grasping light, fragile objects (strawberries, creampuffs, etc) to heavy frying pan lids, all while maintaining their position and posture which is vital in numerous applications that require precise positioning or careful manipulation.
F3 Hand: A Versatile Robot Hand Inspired by Human Thumb and Index Fingers
Jun 16, 2022


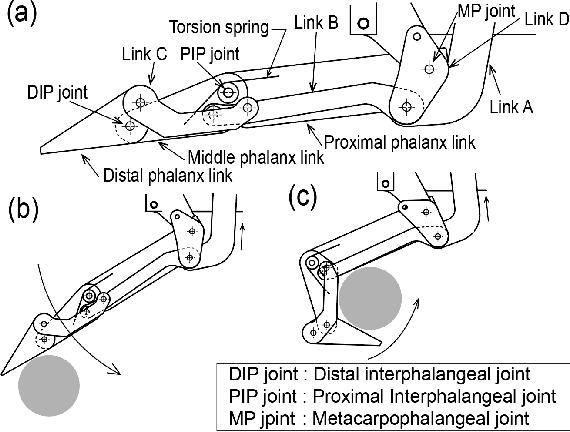
It is challenging to grasp numerous objects with varying sizes and shapes with a single robot hand. To address this, we propose a new robot hand called the 'F3 hand' inspired by the complex movements of human index finger and thumb. The F3 hand attempts to realize complex human-like grasping movements by combining a parallel motion finger and a rotational motion finger with an adaptive function. In order to confirm the performance of our hand, we attached it to a mobile manipulator - the Toyota Human Support Robot (HSR) and conducted grasping experiments. In our results, we show that it is able to grasp all YCB objects (82 in total), including washers with outer diameters as small as 6.4mm. We also built a system for intuitive operation with a 3D mouse and grasp an additional 24 objects, including small toothpicks and paper clips and large pitchers and cracker boxes. The F3 hand is able to achieve a 98% success rate in grasping even under imprecise control and positional offsets. Furthermore, owing to the finger's adaptive function, we demonstrate characteristics of the F3 hand that facilitate the grasping of soft objects such as strawberries in a desirable posture.
F1 Hand: A Versatile Fixed-Finger Gripper for Delicate Teleoperation and Autonomous Grasping
May 14, 2022
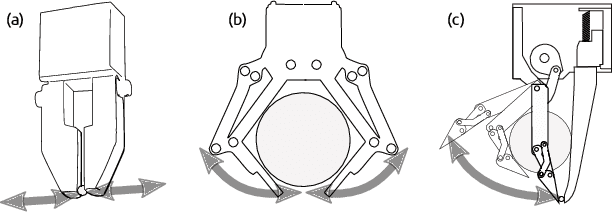


Teleoperation is often limited by the ability of an operator to react and predict the behavior of the robot as it interacts with the environment. For example, to grasp small objects on a table, the teleoperator needs to predict the position of the fingertips before the fingers are closed to avoid them hitting the table. For that reason, we developed the F1 hand, a single-motor gripper that facilitates teleoperation with the use of a fixed finger. The hand is capable of grasping objects as thin as a paper clip, and as heavy and large as a cordless drill. The applicability of the hand can be expanded by replacing the fixed finger with different shapes. This flexibility makes the hand highly versatile while being easy and cheap to develop. However, due to the atypical asymmetric structure and actuation of the hand usual grasping strategies no longer apply. Thus, we propose a controller that approximates actuation symmetry by using the motion of the whole arm. The F1 hand and its controller are compared side-by-side with the original Toyota Human Support Robot (HSR) gripper in teleoperation using 22 objects from the YCB dataset in addition to small objects. The grasping time and peak contact forces could be decreased by 20% and 70%, respectively while increasing success rates by 5%. Using an off-the-shelf grasp pose estimator for autonomous grasping, the system achieved similar success rates to the original HSR gripper, at the order of 80%.
Blending Primitive Policies in Shared Control for Assisted Teleoperation
Apr 14, 2022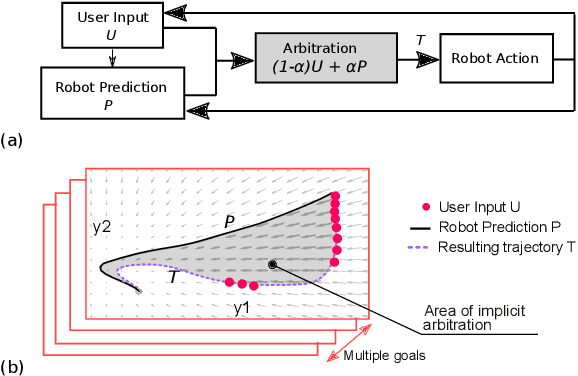
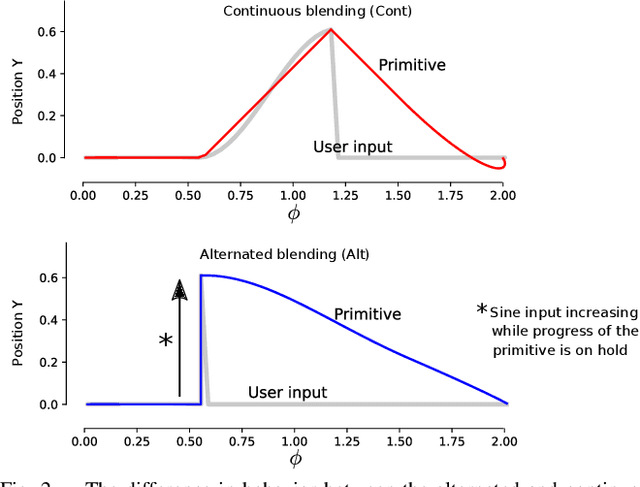
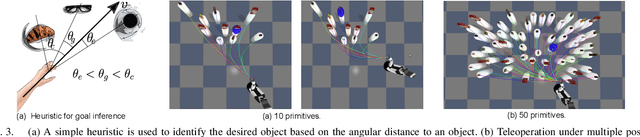
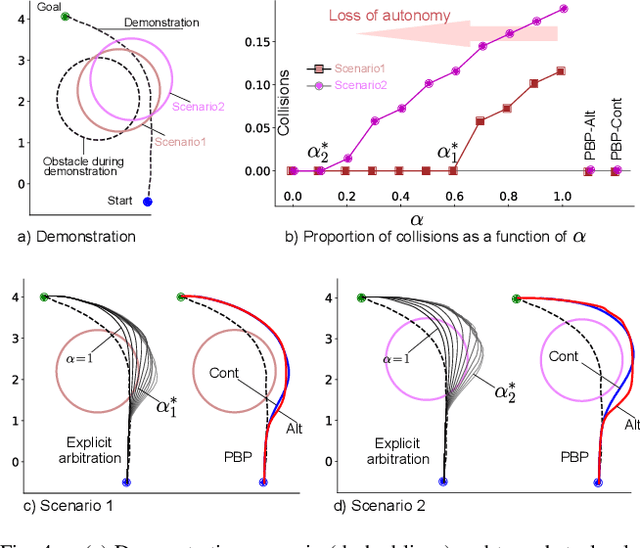
Movement primitives have the property to accommodate changes in the robot state while maintaining attraction to the original policy. As such, we investigate the use of primitives as a blending mechanism by considering that state deviations from the original policy are caused by user inputs. As the primitive recovers from the user input, it implicitly blends human and robot policies without requiring their weightings -- referred to as arbitration. In this paper, we adopt Dynamical Movement Primitives (DMPs), which allow us to avoid the need for multiple demonstrations, and are fast enough to enable numerous instantiations, one for each hypothesis of the human intent. User studies are presented on assisted teleoperation tasks of reaching multiple goals and dynamic obstacle avoidance. Comparable performance to conventional teleoperation was achieved while significantly decreasing human intervention, often by more than 60%.
Visual Task Progress Estimation with Appearance Invariant Embeddings for Robot Control and Planning
Mar 17, 2020



To fulfill the vision of full autonomy, robots must be capable of reasoning about the state of the world. In vision-based tasks, this means that a robot must understand the dissimilarities between its current perception of the environment with that of another state. To be of practical use, this dissimilarity must be quantifiable and computed over scenes with different viewpoints, nature (simulated vs. real), and appearances (shape, color, luminosity, etc.). Motivated by this problem, we propose an approach that uses the consistency of the progress among different examples and viewpoints of a task to train a deep neural network to map images into measurable features. Our method builds upon Time-Contrastive Networks (TCNs), originally proposed as a representation for continuous visuomotor skill learning, to train the network using only discrete snapshots taken at different stages of a task such that the network becomes sensitive to differences in task phases. We associate these embeddings to a sequence of images representing gradual task accomplishment, allowing a robot to iteratively query its motion planner with the current visual state to solve long-horizon tasks. We quantify the granularity achieved by the network in recognizing the number of objects in a scene and in measuring the volume of liquid in a cup. Our experiments leverage this granularity to make a mobile robot move a desired number of objects into a storage area and to control the amount of pouring in a cup.
Periodic Intra-Ensemble Knowledge Distillation for Reinforcement Learning
Feb 01, 2020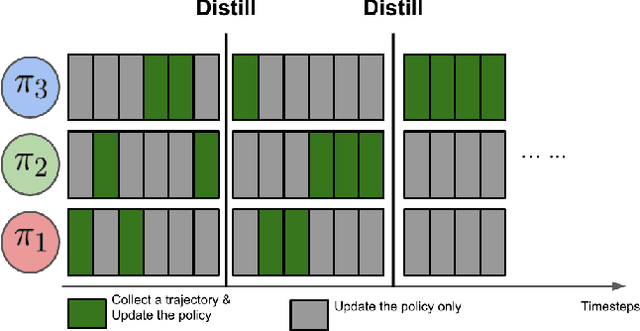
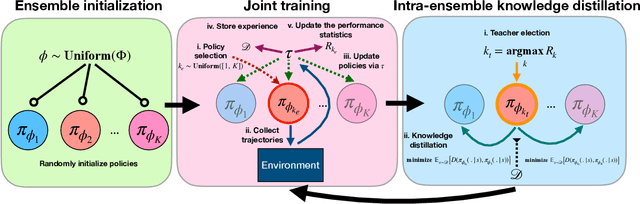

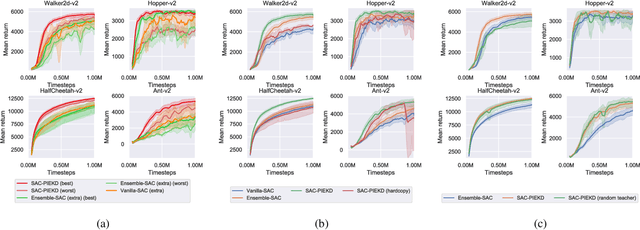
Off-policy ensemble reinforcement learning (RL) methods have demonstrated impressive results across a range of RL benchmark tasks. Recent works suggest that directly imitating experts' policies in a supervised manner before or during the course of training enables faster policy improvement for an RL agent. Motivated by these recent insights, we propose Periodic Intra-Ensemble Knowledge Distillation (PIEKD). PIEKD is a learning framework that uses an ensemble of policies to act in the environment while periodically sharing knowledge amongst policies in the ensemble through knowledge distillation. Our experiments demonstrate that PIEKD improves upon a state-of-the-art RL method in sample efficiency on several challenging MuJoCo benchmark tasks. Additionally, we perform ablation studies to better understand PIEKD.
Phase Portraits as Movement Primitives for Fast Humanoid Robot Control
Dec 07, 2019
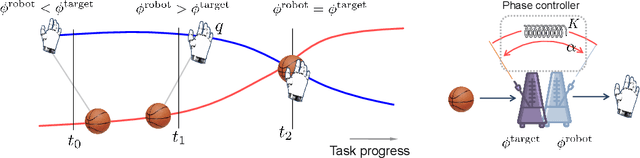
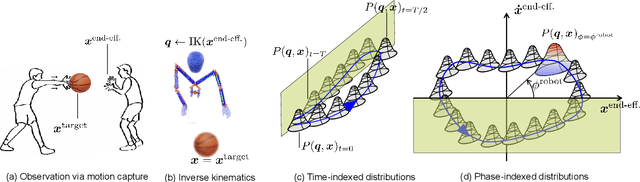
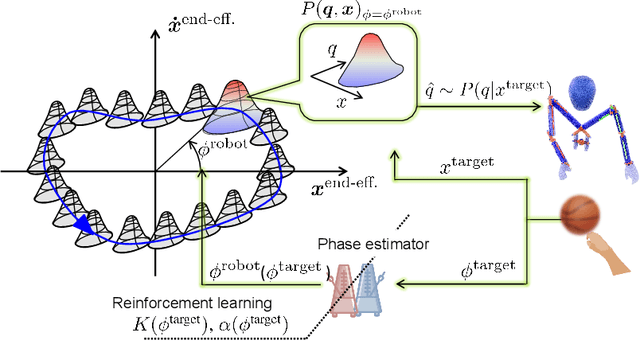
Currently, usual approaches for fast robot control are largely reliant on solving online optimal control problems. Such methods are known to be computationally intensive and sensitive to model accuracy. On the other hand, animals plan complex motor actions not only fast but seemingly with little effort even on unseen tasks. This natural sense of time and coordination motivates us to approach robot control from a motor skill learning perspective to design fast and computationally light controllers that can be learned autonomously by the robot under mild modeling assumptions. This article introduces Phase Portrait Movement Primitives (PPMP), a primitive that predicts dynamics on a low dimensional phase space which in turn is used to govern the high dimensional kinematics of the task. The stark difference with other primitive formulations is a built-in mechanism for phase prediction in the form of coupled oscillators that replaces model-based state estimators such as Kalman filters. The policy is trained by optimizing the parameters of the oscillators whose output is connected to a kinematic distribution in the form of a phase portrait. The drastic reduction in dimensionality allows us to efficiently train and execute PPMPs on a real human-sized, dual-arm humanoid upper body on a task involving 20 degrees-of-freedom. We demonstrate PPMPs in interactions requiring fast reactions times while generating anticipative pose adaptation in both discrete and cyclic tasks.
Optimizing Execution of Dynamic Goal-Directed Robot Movements with Learning Control
Mar 17, 2019


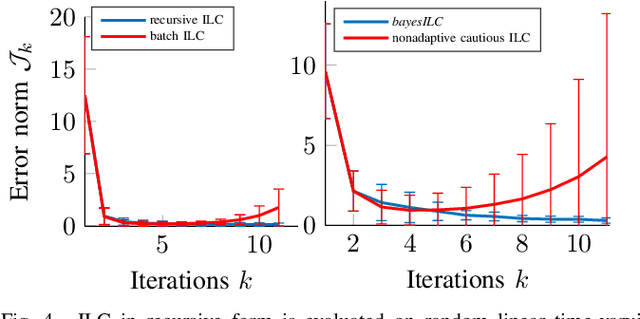
Highly dynamic tasks that require large accelerations and precise tracking usually rely on accurate models and/or high gain feedback. While kinematic optimization allows for efficient representation and online generation of hitting trajectories, learning to track such dynamic movements with inaccurate models remains an open problem. In particular, stability issues surrounding the learning performance, in the iteration domain, can prevent the successful implementation of model based learning approaches. To achieve accurate tracking for such tasks in a stable and efficient way, we propose a new adaptive Iterative Learning Control (ILC) algorithm that is implemented efficiently using a recursive approach. Moreover, covariance estimates of model matrices are used to exercise caution during learning. We evaluate the performance of the proposed approach in extensive simulations and in our robotic table tennis platform, where we show how the striking performance of two seven degree of freedom anthropomorphic robot arms can be optimized. Our implementation on the table tennis platform compares favorably with high-gain PD-control, model-free ILC (simple PD feedback type) and model-based ILC without cautious adaptation.