 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAID-NeRF: Segmentation-AIDed NeRF for Depth Completion of Transparent Objects
Mar 28, 2024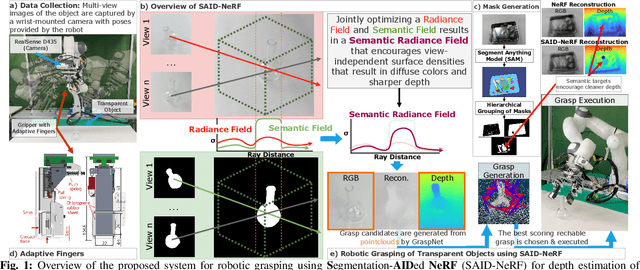
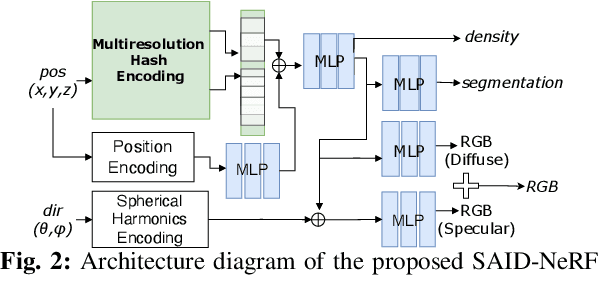


Acquiring accurate depth information of transparent objects using off-the-shelf RGB-D cameras is a well-known challenge in Computer Vision and Robotics. Depth estimation/completion methods are typically employed and trained on datasets with quality depth labels acquired from either simulation, additional sensors or specialized data collection setups and known 3d models. However, acquiring reliable depth information for datasets at scale is not straightforward, limiting training scalability and generalization. Neural Radiance Fields (NeRFs) are learning-free approaches and have demonstrated wide success in novel view synthesis and shape recovery. However, heuristics and controlled environments (lights, backgrounds, etc) are often required to accurately capture specular surfaces. In this paper, we propose using Visual Foundation Models (VFMs) for segmentation in a zero-shot, label-free way to guide the NeRF reconstruction process for these objects via the simultaneous reconstruction of semantic fields and extensions to increase robustness. Our proposed method Segmentation-AIDed NeRF (SAID-NeRF) shows significant performance on depth completion datasets for transparent objects and robotic grasping.