 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MineRL 2020 Competition on Sample Efficient Reinforcement Learning using Human Priors
Jan 26, 2021
Although deep reinforcement learning has led to breakthroughs in many difficult domains, these successes have required an ever-increasing number of samples, affording only a shrinking segment of the AI community access to their development. Resolution of these limitations requires new, sample-efficient methods. To facilitate research in this direction, we propose this second iteration of the MineRL Competition. The primary goal of the competition is to foster the development of algorithms which can efficiently leverage human demonstrations to drastically reduce the number of samples needed to solve complex, hierarchical, and sparse environments. To that end, participants compete under a limited environment sample-complexity budget to develop systems which solve the MineRL ObtainDiamond task in Minecraft, a sequential decision making environment requiring long-term planning, hierarchical control, and efficient exploration methods. The competition is structured into two rounds in which competitors are provided several paired versions of the dataset and environment with different game textures and shaders. At the end of each round, competitors submit containerized versions of their learning algorithms to the AIcrowd platform where they are trained from scratch on a hold-out dataset-environment pair for a total of 4-days on a pre-specified hardware platform. In this follow-up iteration to the NeurIPS 2019 MineRL Competition, we implement new features to expand the scale and reach of the competition. In response to the feedback of the previous participants, we introduce a second minor track focusing on solutions without access to environment interactions of any kind except during test-time. Further we aim to prompt domain agnostic submissions by implementing several novel competition mechanics including action-space randomization and desemantization of observations and actions.
Retrospective Analysis of the 2019 MineRL Competition on Sample Efficient Reinforcement Learning
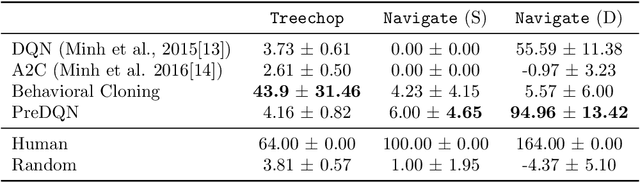
Mar 27, 2020To facilitate research in the direction of sample-efficient reinforcement learning, we held the MineRL Competition on Sample-Efficient Reinforcement Learning Using Human Priors at the Thirty-fourth Conference on Neural Information Processing Systems (NeurIPS 2019). The primary goal of this competition was to promote the development of algorithms that use human demonstrations alongside reinforcement learning to reduce the number of samples needed to solve complex, hierarchical, and sparse environments. We describe the competition and provide an overview of the top solutions, each of which uses deep reinforcement learning and/or imitation learning. We also discuss the impact of our organizational decisions on the competition as well as future directions for improvement.
On Universal Approximation by Neural Networks with Uniform Guarantees on Approximation of Infinite Dimensional Maps
Oct 03, 2019The study of universal approximation of arbitrary functions $f: \mathcal{X} \to \mathcal{Y}$ by neural networks has a rich and thorough history dating back to Kolmogorov (1957). In the case of learning finite dimensional maps, many authors have shown various forms of the universality of both fixed depth and fixed width neural networks. However, in many cases, these classical results fail to extend to the recent use of approximations of neural networks with infinitely many units for functional data analysis, dynamical systems identification, and other applications where either $\mathcal{X}$ or $\mathcal{Y}$ become infinite dimensional. Two questions naturally arise: which infinite dimensional analogues of neural networks are sufficient to approximate any map $f: \mathcal{X} \to \mathcal{Y}$, and when do the finite approximations to these analogues used in practice approximate $f$ uniformly over its infinite dimensional domain $\mathcal{X}$? In this paper, we answer the open question of universal approximation of nonlinear operators when $\mathcal{X}$ and $\mathcal{Y}$ are both infinite dimensional. We show that for a large class of different infinite analogues of neural networks, any continuous map can be approximated arbitrarily closely with some mild topological conditions on $\mathcal{X}$. Additionally, we provide the first lower-bound on the minimal number of input and output units required by a finite approximation to an infinite neural network to guarantee that it can uniformly approximate any nonlinear operator using samples from its inputs and outputs.
MineRL: A Large-Scale Dataset of Minecraft Demonstrations
Jul 29, 2019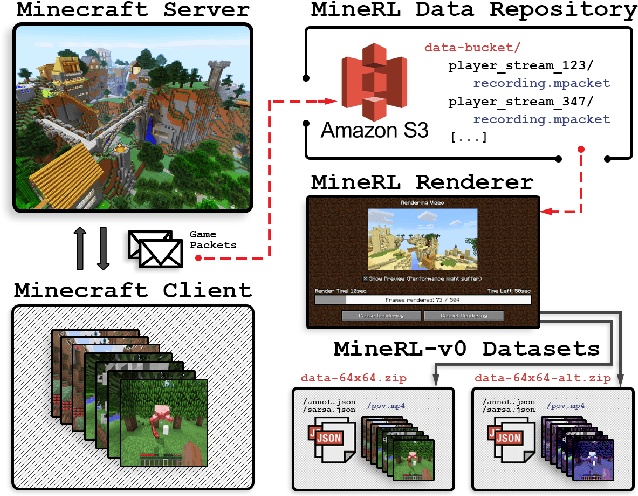
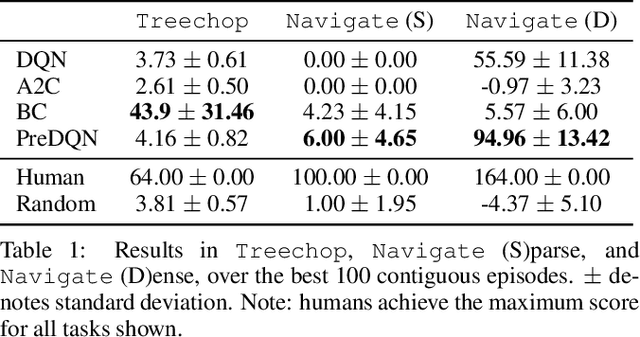
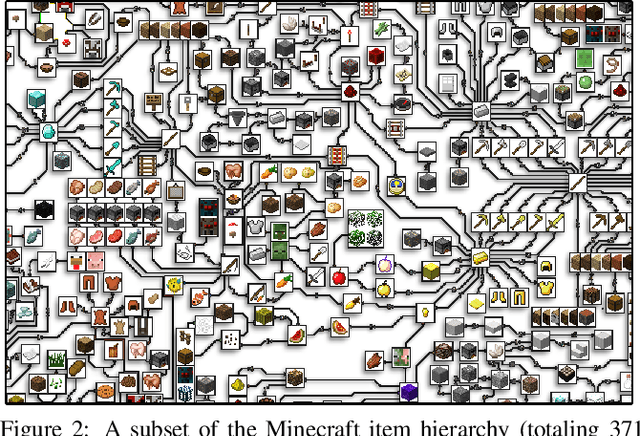

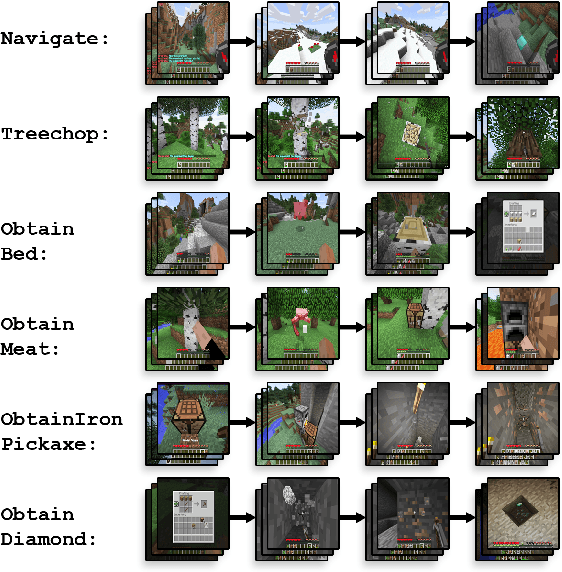
The sample inefficiency of standard deep reinforcement learning methods precludes their application to many real-world problems. Methods which leverage human demonstrations require fewer samples but have been researched less. As demonstrated in the computer vision and natural language processing communities, large-scale datasets have the capacity to facilitate research by serving as an experimental and benchmarking platform for new methods. However, existing datasets compatible with reinforcement learning simulators do not have sufficient scale, structure, and quality to enable the further development and evaluation of methods focused on using human examples. Therefore, we introduce a comprehensive, large-scale, simulator-paired dataset of human demonstrations: MineRL. The dataset consists of over 60 million automatically annotated state-action pairs across a variety of related tasks in Minecraft, a dynamic, 3D, open-world environment. We present a novel data collection scheme which allows for the ongoing introduction of new tasks and the gathering of complete state information suitable for a variety of methods. We demonstrate the hierarchality, diversity, and scale of the MineRL dataset. Further, we show the difficulty of the Minecraft domain along with the potential of MineRL in developing techniques to solve key research challenges within it.
The MineRL Competition on Sample Efficient Reinforcement Learning using Human Priors
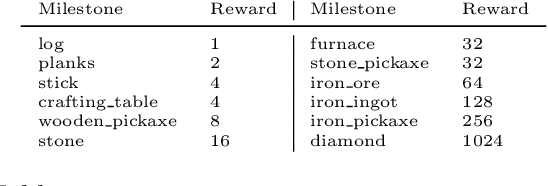
Apr 22, 2019Though deep reinforcement learning has led to breakthroughs in many difficult domains, these successes have required an ever-increasing number of samples. As state-of-the-art reinforcement learning (RL) systems require an exponentially increasing number of samples, their development is restricted to a continually shrinking segment of the AI community. Likewise, many of these systems cannot be applied to real-world problems, where environment samples are expensive. Resolution of these limitations requires new, sample-efficient methods. To facilitate research in this direction, we introduce the MineRL Competition on Sample Efficient Reinforcement Learning using Human Priors. The primary goal of the competition is to foster the development of algorithms which can efficiently leverage human demonstrations to drastically reduce the number of samples needed to solve complex, hierarchical, and sparse environments. To that end, we introduce: (1) the Minecraft ObtainDiamond task, a sequential decision making environment requiring long-term planning, hierarchical control, and efficient exploration methods; and (2) the MineRL-v0 dataset, a large-scale collection of over 60 million state-action pairs of human demonstrations that can be resimulated into embodied trajectories with arbitrary modifications to game state and visuals. Participants will compete to develop systems which solve the ObtainDiamond task with a limited number of samples from the environment simulator, Malmo. The competition is structured into two rounds in which competitors are provided several paired versions of the dataset and environment with different game textures. At the end of each round, competitors will submit containerized versions of their learning algorithms and they will then be trained/evaluated from scratch on a hold-out dataset-environment pair for a total of 4-days on a prespecified hardware platform.
On Characterizing the Capacity of Neural Networks using Algebraic Topology
Feb 13, 2018

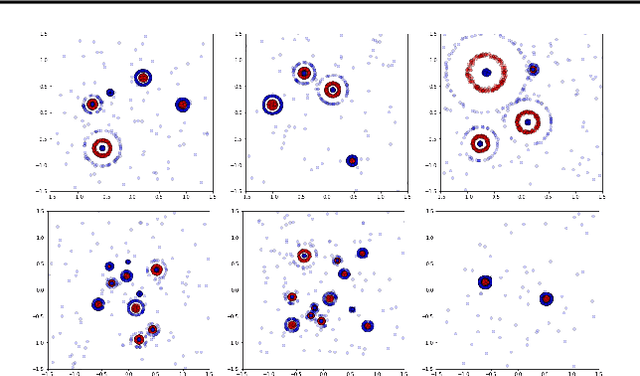
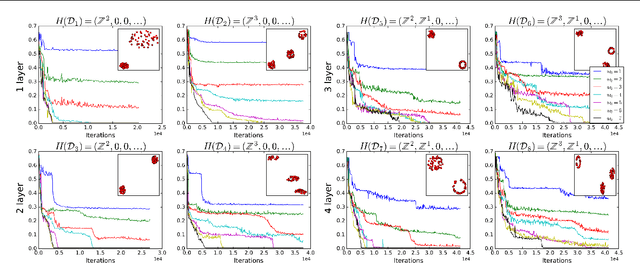
The learnability of different neural architectures can be characterized directly by computable measures of data complexity. In this paper, we reframe the problem of architecture selection as understanding how data determines the most expressive and generalizable architectures suited to that data, beyond inductive bias. After suggesting algebraic topology as a measure for data complexity, we show that the power of a network to express the topological complexity of a dataset in its decision region is a strictly limiting factor in its ability to generalize. We then provide the first empirical characterization of the topological capacity of neural networks. Our empirical analysis shows that at every level of dataset complexity, neural networks exhibit topological phase transitions. This observation allowed us to connect existing theory to empirically driven conjectures on the choice of architectures for fully-connected neural networks.
Deep Function Machines: Generalized Neural Networks for Topological Layer Expression
Nov 06, 2017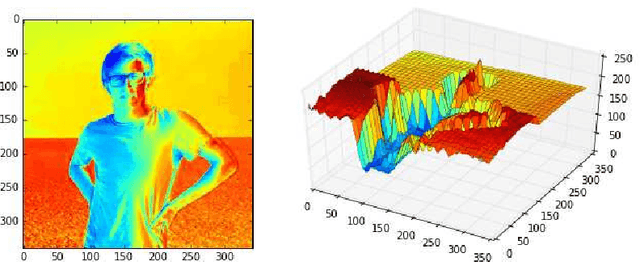
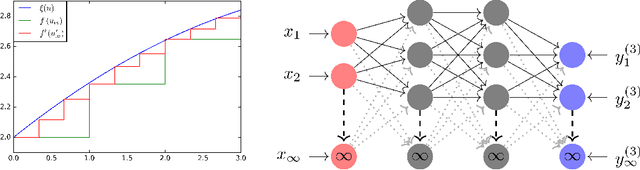
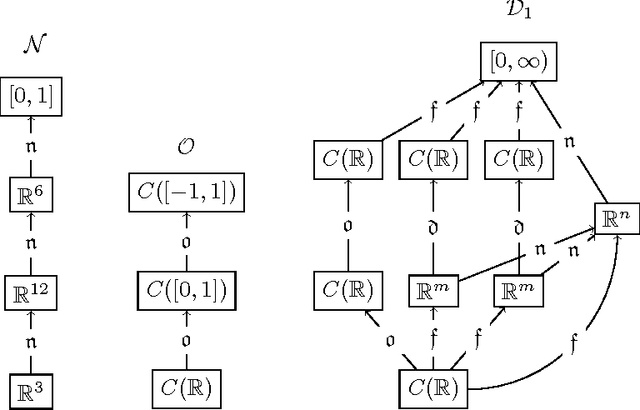
In this paper we propose a generalization of deep neural networks called deep function machines (DFMs). DFMs act on vector spaces of arbitrary (possibly infinite) dimension and we show that a family of DFMs are invariant to the dimension of input data; that is, the parameterization of the model does not directly hinge on the quality of the input (eg. high resolution images). Using this generalization we provide a new theory of universal approximation of bounded non-linear operators between function spaces. We then suggest that DFMs provide an expressive framework for designing new neural network layer types with topological considerations in mind. Finally, we introduce a novel architecture, RippLeNet, for resolution invariant computer vision, which empirically achieves state of the art invariance.