 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElastic Monte Carlo Tree Search with State Abstraction for Strategy Game Playing
May 30, 2022
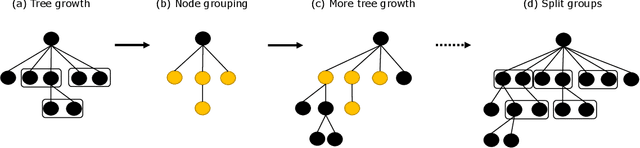
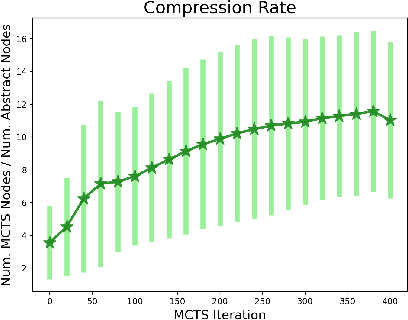
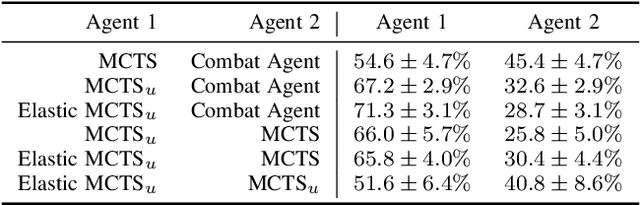
Strategy video games challenge AI agents with their combinatorial search space caused by complex game elements. State abstraction is a popular technique that reduces the state space complexity. However, current state abstraction methods for games depend on domain knowledge, making their application to new games expensive. State abstraction methods that require no domain knowledge are studied extensively in the planning domain. However, no evidence shows they scale well with the complexity of strategy games. In this paper, we propose Elastic MCTS, an algorithm that uses state abstraction to play strategy games. In Elastic MCTS, the nodes of the tree are clustered dynamically, first grouped together progressively by state abstraction, and then separated when an iteration threshold is reached. The elastic changes benefit from efficient searching brought by state abstraction but avoid the negative influence of using state abstraction for the whole search. To evaluate our method, we make use of the general strategy games platform Stratega to generate scenarios of varying complexity. Results show that Elastic MCTS outperforms MCTS baselines with a large margin, while reducing the tree size by a factor of $10$. Code can be found at: https://github.com/egg-west/Stratega
The MineRL Competition on Sample Efficient Reinforcement Learning using Human Priors
Apr 22, 2019
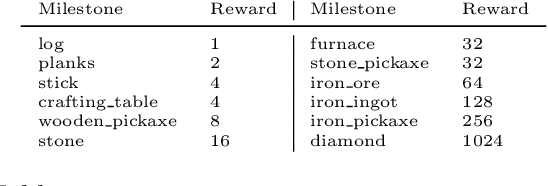
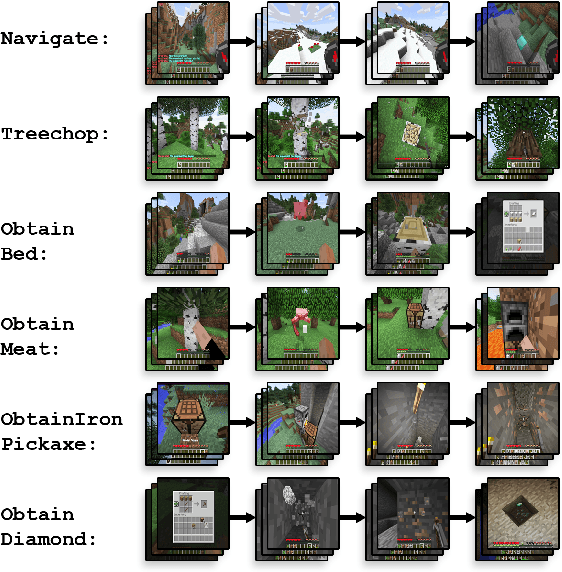
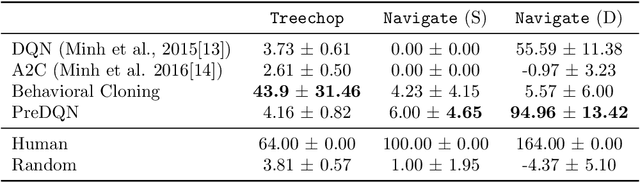
Though deep reinforcement learning has led to breakthroughs in many difficult domains, these successes have required an ever-increasing number of samples. As state-of-the-art reinforcement learning (RL) systems require an exponentially increasing number of samples, their development is restricted to a continually shrinking segment of the AI community. Likewise, many of these systems cannot be applied to real-world problems, where environment samples are expensive. Resolution of these limitations requires new, sample-efficient methods. To facilitate research in this direction, we introduce the MineRL Competition on Sample Efficient Reinforcement Learning using Human Priors. The primary goal of the competition is to foster the development of algorithms which can efficiently leverage human demonstrations to drastically reduce the number of samples needed to solve complex, hierarchical, and sparse environments. To that end, we introduce: (1) the Minecraft ObtainDiamond task, a sequential decision making environment requiring long-term planning, hierarchical control, and efficient exploration methods; and (2) the MineRL-v0 dataset, a large-scale collection of over 60 million state-action pairs of human demonstrations that can be resimulated into embodied trajectories with arbitrary modifications to game state and visuals. Participants will compete to develop systems which solve the ObtainDiamond task with a limited number of samples from the environment simulator, Malmo. The competition is structured into two rounds in which competitors are provided several paired versions of the dataset and environment with different game textures. At the end of each round, competitors will submit containerized versions of their learning algorithms and they will then be trained/evaluated from scratch on a hold-out dataset-environment pair for a total of 4-days on a prespecified hardware platform.