 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition Paper: Agent AI Towards a Holistic Intelligence
Feb 28, 2024Recent advancements in large foundation models have remarkably enhanced our understanding of sensory information in open-world environments. In leveraging the power of foundation models, it is crucial for AI research to pivot away from excessive reductionism and toward an emphasis on systems that function as cohesive wholes. Specifically, we emphasize developing Agent AI -- an embodied system that integrates large foundation models into agent actions. The emerging field of Agent AI spans a wide range of existing embodied and agent-based multimodal interactions, including robotics, gaming, and healthcare systems, etc. In this paper, we propose a novel large action model to achieve embodied intelligent behavior, the Agent Foundation Model. On top of this idea, we discuss how agent AI exhibits remarkable capabilities across a variety of domains and tasks, challenging our understanding of learning and cognition. Furthermore, we discuss the potential of Agent AI from an interdisciplinary perspective, underscoring AI cognition and consciousness within scientific discourse. We believe that those discussions serve as a basis for future research directions and encourage broader societal engagement.
An Interactive Agent Foundation Model
Feb 08, 2024



The development of artificial intelligence systems is transitioning from creating static, task-specific models to dynamic, agent-based systems capable of performing well in a wide range of applications. We propose an Interactive Agent Foundation Model that uses a novel multi-task agent training paradigm for training AI agents across a wide range of domains, datasets, and tasks. Our training paradigm unifies diverse pre-training strategies, including visual masked auto-encoders, language modeling, and next-action prediction, enabling a versatile and adaptable AI framework. We demonstrate the performance of our framework across three separate domains -- Robotics, Gaming AI, and Healthcare. Our model demonstrates its ability to generate meaningful and contextually relevant outputs in each area. The strength of our approach lies in its generality, leveraging a variety of data sources such as robotics sequences, gameplay data, large-scale video datasets, and textual information for effective multimodal and multi-task learning. Our approach provides a promising avenue for developing generalist, action-taking, multimodal systems.
The MineRL Competition on Sample Efficient Reinforcement Learning using Human Priors
Apr 22, 2019
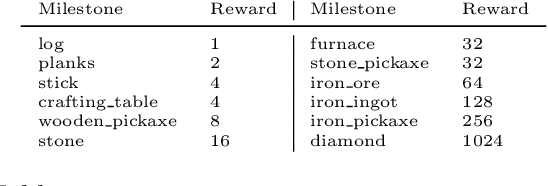
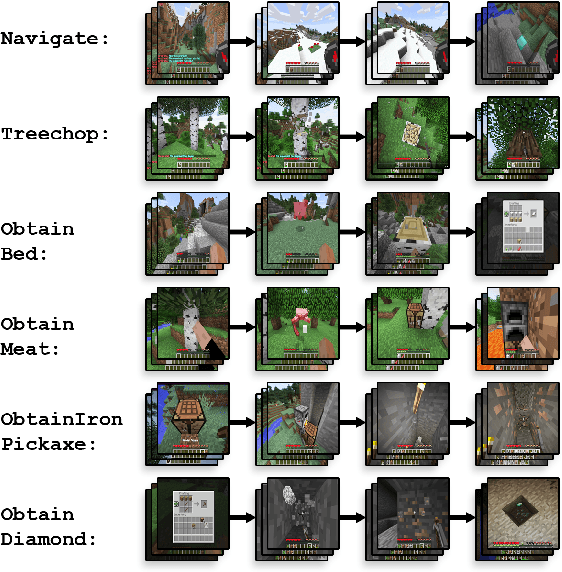
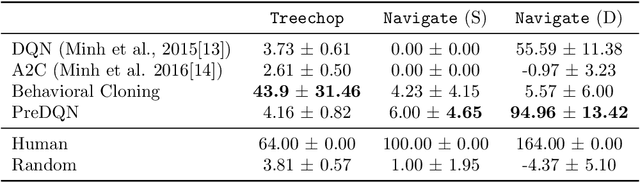
Though deep reinforcement learning has led to breakthroughs in many difficult domains, these successes have required an ever-increasing number of samples. As state-of-the-art reinforcement learning (RL) systems require an exponentially increasing number of samples, their development is restricted to a continually shrinking segment of the AI community. Likewise, many of these systems cannot be applied to real-world problems, where environment samples are expensive. Resolution of these limitations requires new, sample-efficient methods. To facilitate research in this direction, we introduce the MineRL Competition on Sample Efficient Reinforcement Learning using Human Priors. The primary goal of the competition is to foster the development of algorithms which can efficiently leverage human demonstrations to drastically reduce the number of samples needed to solve complex, hierarchical, and sparse environments. To that end, we introduce: (1) the Minecraft ObtainDiamond task, a sequential decision making environment requiring long-term planning, hierarchical control, and efficient exploration methods; and (2) the MineRL-v0 dataset, a large-scale collection of over 60 million state-action pairs of human demonstrations that can be resimulated into embodied trajectories with arbitrary modifications to game state and visuals. Participants will compete to develop systems which solve the ObtainDiamond task with a limited number of samples from the environment simulator, Malmo. The competition is structured into two rounds in which competitors are provided several paired versions of the dataset and environment with different game textures. At the end of each round, competitors will submit containerized versions of their learning algorithms and they will then be trained/evaluated from scratch on a hold-out dataset-environment pair for a total of 4-days on a prespecified hardware platform.