 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-agent or Multi-agent Systems? Why Not Both?
May 23, 2025Multi-agent systems (MAS) decompose complex tasks and delegate subtasks to different large language model (LLM) agents and tools. Prior studies have reported the superior accuracy performance of MAS across diverse domains, enabled by long-horizon context tracking and error correction through role-specific agents. However, the design and deployment of MAS incur higher complexity and runtime cost compared to single-agent systems (SAS). Meanwhile, frontier LLMs, such as OpenAI-o3 and Gemini-2.5-Pro, have rapidly advanced in long-context reasoning, memory retention, and tool usage, mitigating many limitations that originally motivated MAS designs. In this paper, we conduct an extensive empirical study comparing MAS and SAS across various popular agentic applications. We find that the benefits of MAS over SAS diminish as LLM capabilities improve, and we propose efficient mechanisms to pinpoint the error-prone agent in MAS. Furthermore, the performance discrepancy between MAS and SAS motivates our design of a hybrid agentic paradigm, request cascading between MAS and SAS, to improve both efficiency and capability. Our design improves accuracy by 1.1-12% while reducing deployment costs by up to 20% across various agentic applications.
MineRL: A Large-Scale Dataset of Minecraft Demonstrations
Jul 29, 2019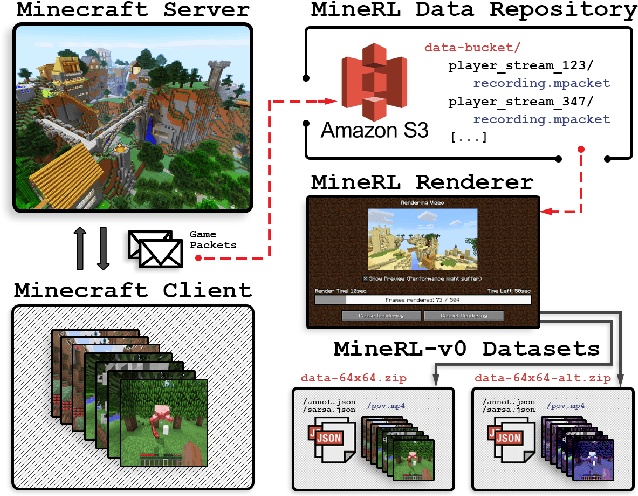
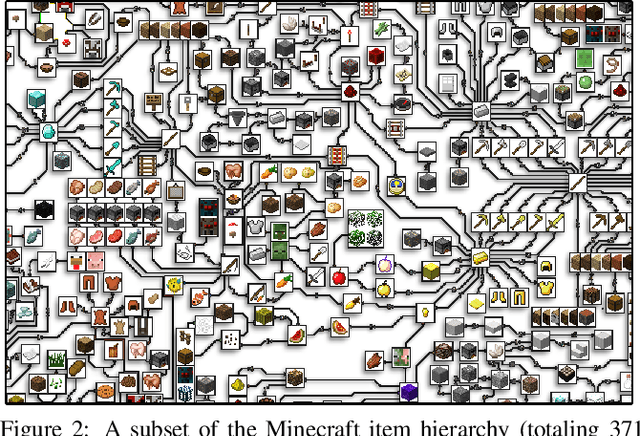

The sample inefficiency of standard deep reinforcement learning methods precludes their application to many real-world problems. Methods which leverage human demonstrations require fewer samples but have been researched less. As demonstrated in the computer vision and natural language processing communities, large-scale datasets have the capacity to facilitate research by serving as an experimental and benchmarking platform for new methods. However, existing datasets compatible with reinforcement learning simulators do not have sufficient scale, structure, and quality to enable the further development and evaluation of methods focused on using human examples. Therefore, we introduce a comprehensive, large-scale, simulator-paired dataset of human demonstrations: MineRL. The dataset consists of over 60 million automatically annotated state-action pairs across a variety of related tasks in Minecraft, a dynamic, 3D, open-world environment. We present a novel data collection scheme which allows for the ongoing introduction of new tasks and the gathering of complete state information suitable for a variety of methods. We demonstrate the hierarchality, diversity, and scale of the MineRL dataset. Further, we show the difficulty of the Minecraft domain along with the potential of MineRL in developing techniques to solve key research challenges within it.
The MineRL Competition on Sample Efficient Reinforcement Learning using Human Priors
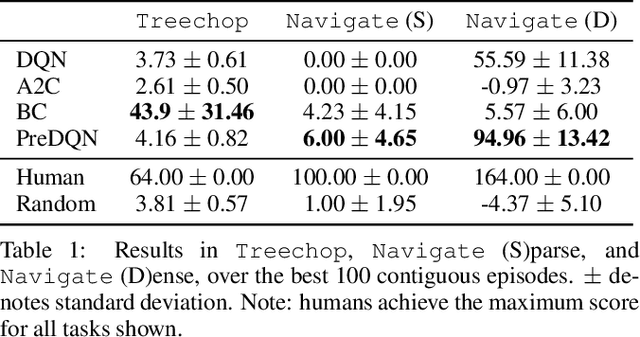
Apr 22, 2019
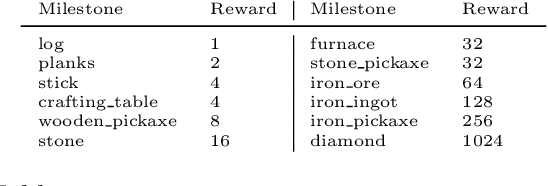
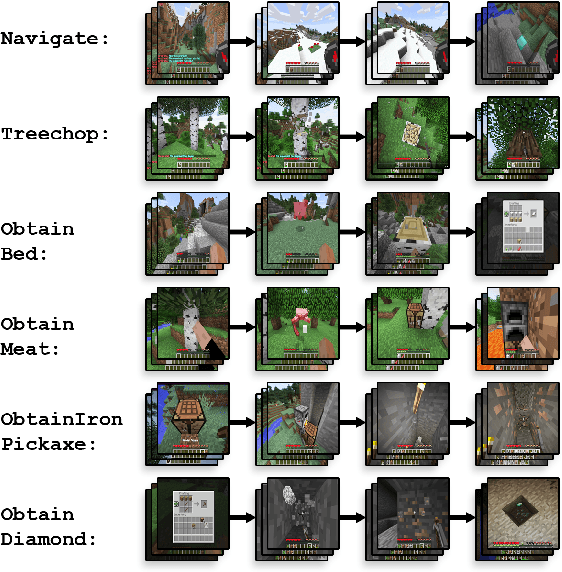
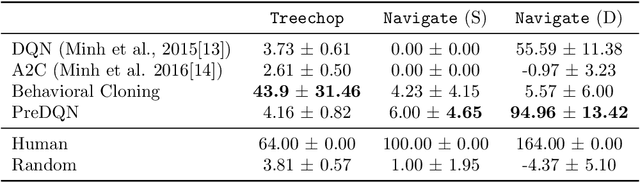
Though deep reinforcement learning has led to breakthroughs in many difficult domains, these successes have required an ever-increasing number of samples. As state-of-the-art reinforcement learning (RL) systems require an exponentially increasing number of samples, their development is restricted to a continually shrinking segment of the AI community. Likewise, many of these systems cannot be applied to real-world problems, where environment samples are expensive. Resolution of these limitations requires new, sample-efficient methods. To facilitate research in this direction, we introduce the MineRL Competition on Sample Efficient Reinforcement Learning using Human Priors. The primary goal of the competition is to foster the development of algorithms which can efficiently leverage human demonstrations to drastically reduce the number of samples needed to solve complex, hierarchical, and sparse environments. To that end, we introduce: (1) the Minecraft ObtainDiamond task, a sequential decision making environment requiring long-term planning, hierarchical control, and efficient exploration methods; and (2) the MineRL-v0 dataset, a large-scale collection of over 60 million state-action pairs of human demonstrations that can be resimulated into embodied trajectories with arbitrary modifications to game state and visuals. Participants will compete to develop systems which solve the ObtainDiamond task with a limited number of samples from the environment simulator, Malmo. The competition is structured into two rounds in which competitors are provided several paired versions of the dataset and environment with different game textures. At the end of each round, competitors will submit containerized versions of their learning algorithms and they will then be trained/evaluated from scratch on a hold-out dataset-environment pair for a total of 4-days on a prespecified hardware platform.