 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Nano Omni: Efficient and Open Multimodal Intelligence
Apr 27, 2026We introduce Nemotron 3 Nano Omni, the latest model in the Nemotron multimodal series and the first to natively support audio inputs alongside text, images, and video. Nemotron 3 Nano Omni delivers consistent accuracy improvements over its predecessor, Nemotron Nano V2 VL, across all modalities, enabled by advances in architecture, training data and recipes. In particular, Nemotron 3 delivers leading results in real-world document understanding, long audio-video comprehension, and agentic computer use. Built on the highly efficient Nemotron 3 Nano 30B-A3B backbone, Nemotron 3 Nano Omni further incorporates innovative multimodal token-reduction techniques to deliver substantially lower inference latency and higher throughput than other models of similar size. We are releasing model checkpoints in BF16, FP8, and FP4 formats, along with portions of the training data and codebase to facilitate further research and development.
Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
NVIDIA Nemotron Nano V2 VL
Nov 07, 2025We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
Robust Generative Adversarial Imitation Learning via Local Lipschitzness
Jun 30, 2021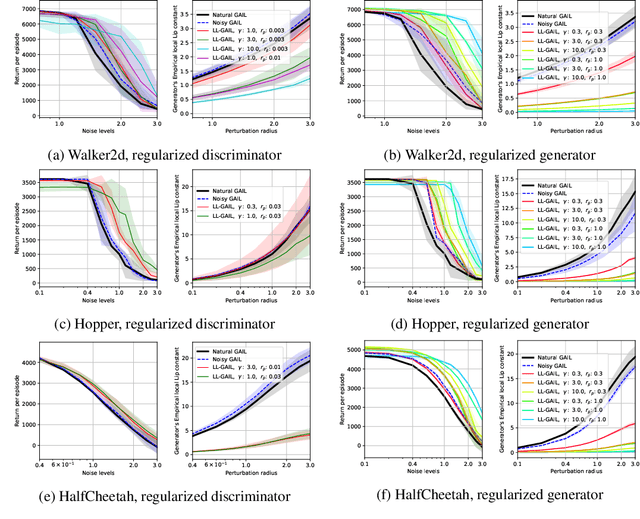
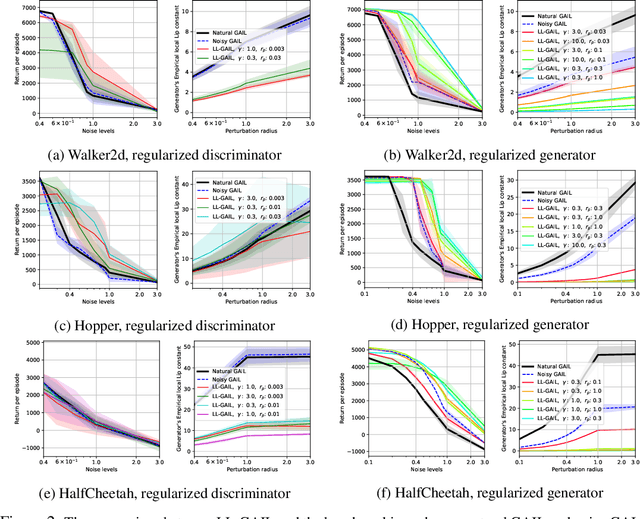
We explore methodologies to improve the robustness of generative adversarial imitation learning (GAIL) algorithms to observation noise. Towards this objective, we study the effect of local Lipschitzness of the discriminator and the generator on the robustness of policies learned by GAIL. In many robotics applications, the learned policies by GAIL typically suffer from a degraded performance at test time since the observations from the environment might be corrupted by noise. Hence, robustifying the learned policies against the observation noise is of critical importance. To this end, we propose a regularization method to induce local Lipschitzness in the generator and the discriminator of adversarial imitation learning methods. We show that the modified objective leads to learning significantly more robust policies. Moreover, we demonstrate -- both theoretically and experimentally -- that training a locally Lipschitz discriminator leads to a locally Lipschitz generator, thereby improving the robustness of the resultant policy. We perform extensive experiments on simulated robot locomotion environments from the MuJoCo suite that demonstrate the proposed method learns policies that significantly outperform the state-of-the-art generative adversarial imitation learning algorithm when applied to test scenarios with noise-corrupted observations.
Self-Supervised Online Reward Shaping in Sparse-Reward Environments
Mar 08, 2021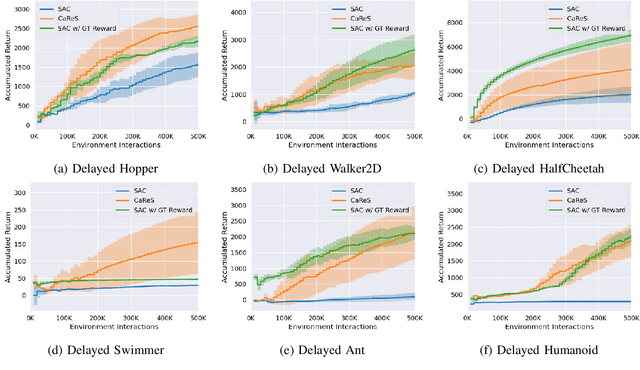
We propose a novel reinforcement learning framework that performs self-supervised online reward shaping, yielding faster, sample efficient performance in sparse reward environments. The proposed framework alternates between updating a policy and inferring a reward function. While the policy update is done with the inferred, potentially dense reward function, the original sparse reward is used to provide a self-supervisory signal for the reward update by serving as an ordering over the observed trajectories. The proposed framework is based on the theory that altering the reward function does not affect the optimal policy of the original MDP as long as we maintain certain relations between the altered and the original reward. We name the proposed framework \textit{ClAssification-based REward Shaping} (CaReS), since we learn the altered reward in a self-supervised manner using classifier based reward inference. Experimental results on several sparse-reward environments demonstrate that the proposed algorithm is not only significantly more sample efficient than the state-of-the-art baseline, but also achieves a similar sample efficiency to MDPs that use hand-designed dense reward functions.
Active Task-Inference-Guided Deep Inverse Reinforcement Learning
Jan 24, 2020


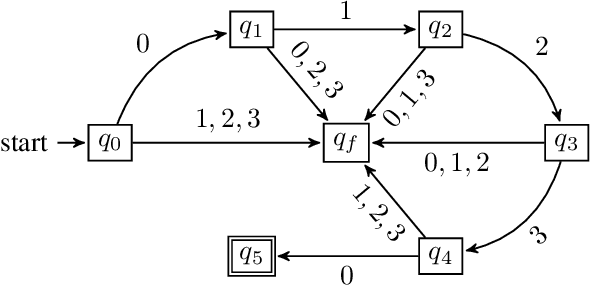
In inverse reinforcement learning (IRL), given a Markov decision process (MDP) and a set of demonstrations for completing a task, the objective is to learn a reward function to explain the demonstrations. However, it is challenging to apply IRL in tasks where a proper memory structure is the key to complete the task. To address this challenge, we develop an iterative algorithm that alternates between a task inference module that infers the high-level memory structure of the task and a reward learning module that learns a reward function with the inferred memory structure. In each iteration, the task inference module produces a series of queries to be answered by the demonstrator. Each query asks whether a sequence of high-level events leads to the completion of the task. The demonstrator then provides a demonstration executing the sequence to answer each query. After the queries are answered, the task inference module returns a hypothesis deterministic finite automaton (DFA) encoding the high-level memory structure to be used by the reward learning. The reward learning module incorporates the DFA states into the MDP states and creates a product automaton. Then the reward learning module proceeds to learn a Markovian reward function for this product automaton by performing deep maximum entropy IRL. At the end of each iteration, the algorithm computes an optimal policy with respect to the learned reward. This iterative process continues until the computed policy leads to satisfactory performance in completing the task. The experiments show that the proposed algorithm outperforms three IRL baselines in task performance.