 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Online Reward Shaping in Sparse-Reward Environments
Paper and Code
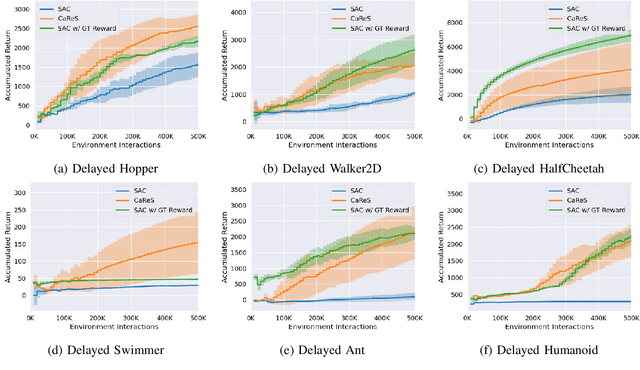
We propose a novel reinforcement learning framework that performs self-supervised online reward shaping, yielding faster, sample efficient performance in sparse reward environments. The proposed framework alternates between updating a policy and inferring a reward function. While the policy update is done with the inferred, potentially dense reward function, the original sparse reward is used to provide a self-supervisory signal for the reward update by serving as an ordering over the observed trajectories. The proposed framework is based on the theory that altering the reward function does not affect the optimal policy of the original MDP as long as we maintain certain relations between the altered and the original reward. We name the proposed framework \textit{ClAssification-based REward Shaping} (CaReS), since we learn the altered reward in a self-supervised manner using classifier based reward inference. Experimental results on several sparse-reward environments demonstrate that the proposed algorithm is not only significantly more sample efficient than the state-of-the-art baseline, but also achieves a similar sample efficiency to MDPs that use hand-designed dense reward functions.