 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurry-DPO: Enhancing Alignment using Curriculum Learning & Ranked Preferences
Paper and Code
Mar 12, 2024
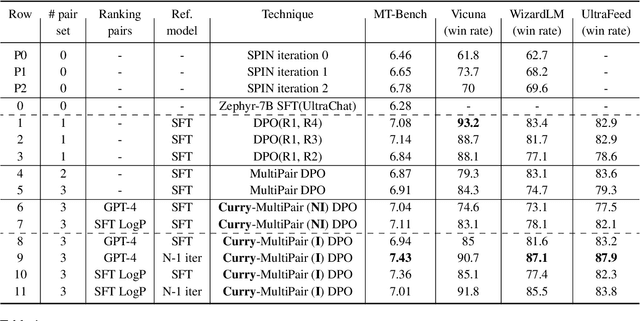
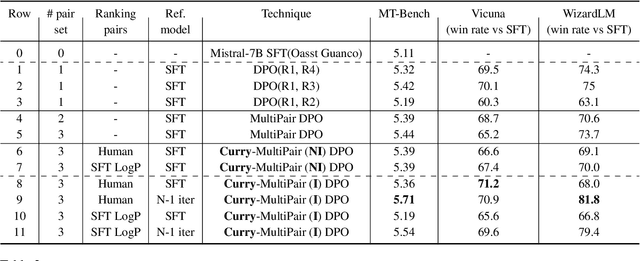

Direct Preference Optimization (DPO) is an effective technique that leverages pairwise preference data (usually one chosen and rejected response pair per user prompt) to align LLMs to human preferences. In practice, multiple responses can exist for a given prompt with varying quality relative to each other. With availability of such quality ratings for multiple responses, we propose utilizing these responses to create multiple preference pairs for a given prompt. Our work focuses on systematically using the constructed multiple preference pair in DPO training via curriculum learning methodology. In particular, we order these multiple pairs of preference data from easy to hard (emulating curriculum training) according to various criteria. We show detailed comparisons of our proposed approach to the standard single-pair DPO setting. Our method, which we call Curry-DPO consistently shows increased performance gains on MTbench, Vicuna, WizardLM, and the UltraFeedback test set, highlighting its effectiveness. More specifically, Curry-DPO achieves a score of 7.43 on MT-bench with Zephy-7B model outperforming majority of existing LLMs with similar parameter size. Curry-DPO also achieves the highest adjusted win rates on Vicuna, WizardLM, and UltraFeedback test datasets (90.7%, 87.1%, and 87.9% respectively) in our experiments, with notable gains of upto 7.5% when compared to standard DPO technique.