 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveThru: a Document Extraction Platform and Benchmark Datasets for Indonesian Local Language Archives
Nov 14, 2024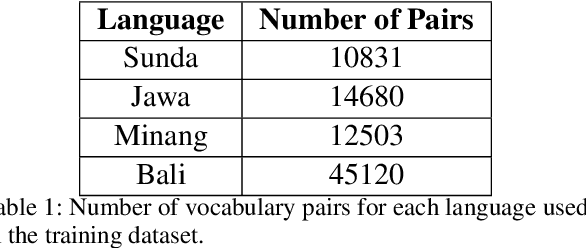
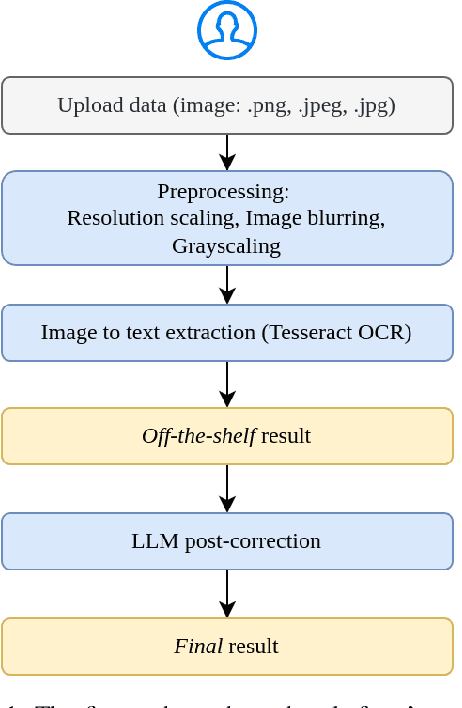
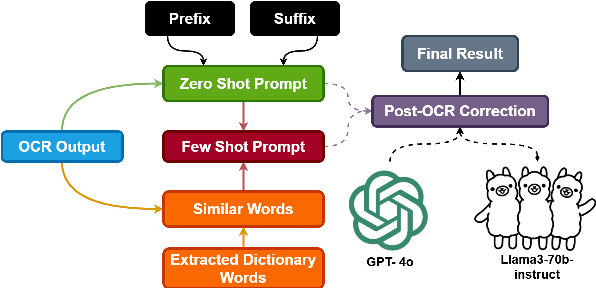
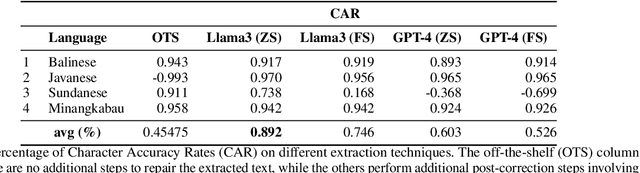
Indonesia is one of the most diverse countries linguistically. However, despite this linguistic diversity, Indonesian languages remain underrepresented in Natural Language Processing (NLP) research and technologies. In the past two years, several efforts have been conducted to construct NLP resources for Indonesian languages. However, most of these efforts have been focused on creating manual resources thus difficult to scale to more languages. Although many Indonesian languages do not have a web presence, locally there are resources that document these languages well in printed forms such as books, magazines, and newspapers. Digitizing these existing resources will enable scaling of Indonesian language resource construction to many more languages. In this paper, we propose an alternative method of creating datasets by digitizing documents, which have not previously been used to build digital language resources in Indonesia. DriveThru is a platform for extracting document content utilizing Optical Character Recognition (OCR) techniques in its system to provide language resource building with less manual effort and cost. This paper also studies the utility of current state-of-the-art LLM for post-OCR correction to show the capability of increasing the character accuracy rate (CAR) and word accuracy rate (WAR) compared to off-the-shelf OCR.