 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndonesian-English Code-Switching Speech Synthesizer Utilizing Multilingual STEN-TTS and Bert LID
Dec 26, 2024Multilingual text-to-speech systems convert text into speech across multiple languages. In many cases, text sentences may contain segments in different languages, a phenomenon known as code-switching. This is particularly common in Indonesia, especially between Indonesian and English. Despite its significance, no research has yet developed a multilingual TTS system capable of handling code-switching between these two languages. This study addresses Indonesian-English code-switching in STEN-TTS. Key modifications include adding a language identification component to the text-to-phoneme conversion using finetuned BERT for per-word language identification, as well as removing language embedding from the base model. Experimental results demonstrate that the code-switching model achieves superior naturalness and improved speech intelligibility compared to the Indonesian and English baseline STEN-TTS models.
Continual Learning in Machine Speech Chain Using Gradient Episodic Memory
Nov 27, 2024



Continual learning for automatic speech recognition (ASR) systems poses a challenge, especially with the need to avoid catastrophic forgetting while maintaining performance on previously learned tasks. This paper introduces a novel approach leveraging the machine speech chain framework to enable continual learning in ASR using gradient episodic memory (GEM). By incorporating a text-to-speech (TTS) component within the machine speech chain, we support the replay mechanism essential for GEM, allowing the ASR model to learn new tasks sequentially without significant performance degradation on earlier tasks. Our experiments, conducted on the LJ Speech dataset, demonstrate that our method outperforms traditional fine-tuning and multitask learning approaches, achieving a substantial error rate reduction while maintaining high performance across varying noise conditions. We showed the potential of our semi-supervised machine speech chain approach for effective and efficient continual learning in speech recognition.
What Did I Just Hear? Detecting Pornographic Sounds in Adult Videos Using Neural Networks
Sep 08, 2022

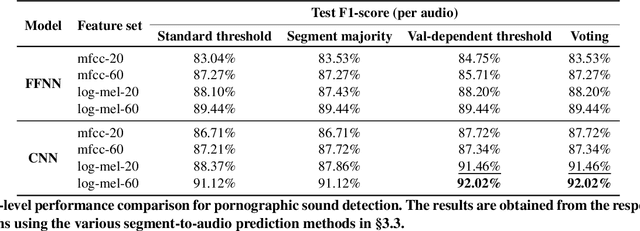
Audio-based pornographic detection enables efficient adult content filtering without sacrificing performance by exploiting distinct spectral characteristics. To improve it, we explore pornographic sound modeling based on different neural architectures and acoustic features. We find that CNN trained on log mel spectrogram achieves the best performance on Pornography-800 dataset. Our experiment results also show that log mel spectrogram allows better representations for the models to recognize pornographic sounds. Finally, to classify whole audio waveforms rather than segments, we employ voting segment-to-audio technique that yields the best audio-level detection results.