 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Hallucinated Translations in Large Language Models with Hallucination-focused Preference Optimization
Jan 28, 2025



Machine Translation (MT) is undergoing a paradigm shift, with systems based on fine-tuned large language models (LLM) becoming increasingly competitive with traditional encoder-decoder models trained specifically for translation tasks. However, LLM-based systems are at a higher risk of generating hallucinations, which can severely undermine user's trust and safety. Most prior research on hallucination mitigation focuses on traditional MT models, with solutions that involve post-hoc mitigation - detecting hallucinated translations and re-translating them. While effective, this approach introduces additional complexity in deploying extra tools in production and also increases latency. To address these limitations, we propose a method that intrinsically learns to mitigate hallucinations during the model training phase. Specifically, we introduce a data creation framework to generate hallucination focused preference datasets. Fine-tuning LLMs on these preference datasets reduces the hallucination rate by an average of 96% across five language pairs, while preserving overall translation quality. In a zero-shot setting our approach reduces hallucinations by 89% on an average across three unseen target languages.
* NAACL 2025 Main Conference Long paper (9 pages)
Automatic Post-Editing for Machine Translation
Oct 18, 2019
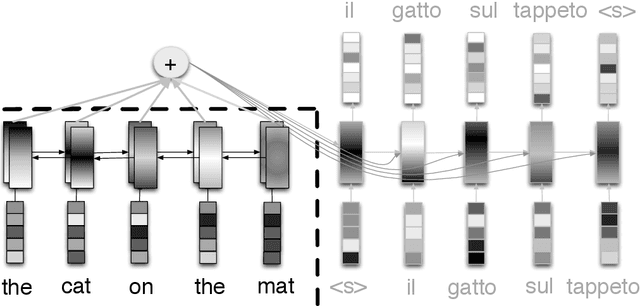
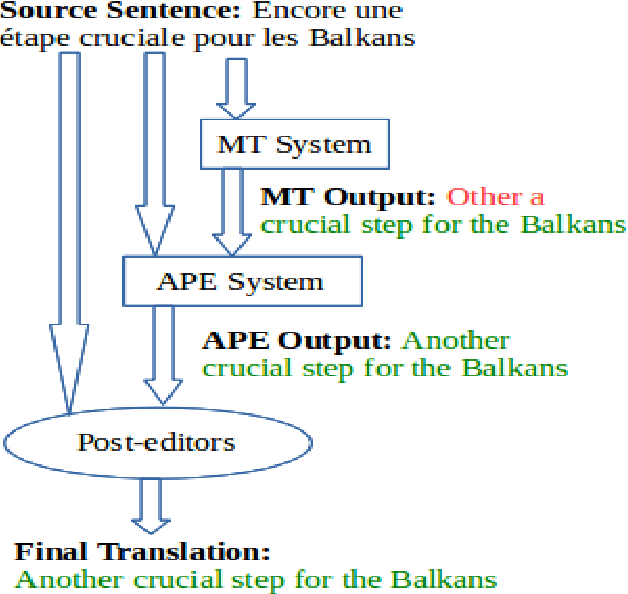
Automatic Post-Editing (APE) aims to correct systematic errors in a machine translated text. This is primarily useful when the machine translation (MT) system is not accessible for improvement, leaving APE as a viable option to improve translation quality as a downstream task - which is the focus of this thesis. This field has received less attention compared to MT due to several reasons, which include: the limited availability of data to perform a sound research, contrasting views reported by different researchers about the effectiveness of APE, and limited attention from the industry to use APE in current production pipelines. In this thesis, we perform a thorough investigation of APE as a downstream task in order to: i) understand its potential to improve translation quality; ii) advance the core technology - starting from classical methods to recent deep-learning based solutions; iii) cope with limited and sparse data; iv) better leverage multiple input sources; v) mitigate the task-specific problem of over-correction; vi) enhance neural decoding to leverage external knowledge; and vii) establish an online learning framework to handle data diversity in real-time. All the above contributions are discussed across several chapters, and most of them are evaluated in the APE shared task organized each year at the Conference on Machine Translation. Our efforts in improving the technology resulted in the best system at the 2017 APE shared task, and our work on online learning received a distinguished paper award at the Italian Conference on Computational Linguistics. Overall, outcomes and findings of our work have boost interest among researchers and attracted industries to examine this technology to solve real-word problems.
Selecting Machine-Translated Data for Quick Bootstrapping of a Natural Language Understanding System
May 23, 2018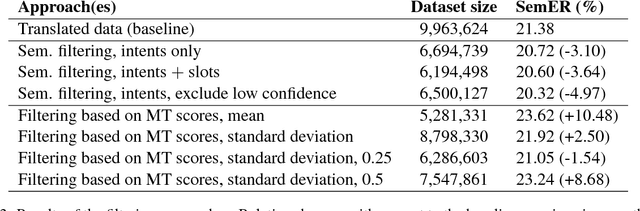

This paper investigates the use of Machine Translation (MT) to bootstrap a Natural Language Understanding (NLU) system for a new language for the use case of a large-scale voice-controlled device. The goal is to decrease the cost and time needed to get an annotated corpus for the new language, while still having a large enough coverage of user requests. Different methods of filtering MT data in order to keep utterances that improve NLU performance and language-specific post-processing methods are investigated. These methods are tested in a large-scale NLU task with translating around 10 millions training utterances from English to German. The results show a large improvement for using MT data over a grammar-based and over an in-house data collection baseline, while reducing the manual effort greatly. Both filtering and post-processing approaches improve results further.
eSCAPE: a Large-scale Synthetic Corpus for Automatic Post-Editing
Mar 20, 2018
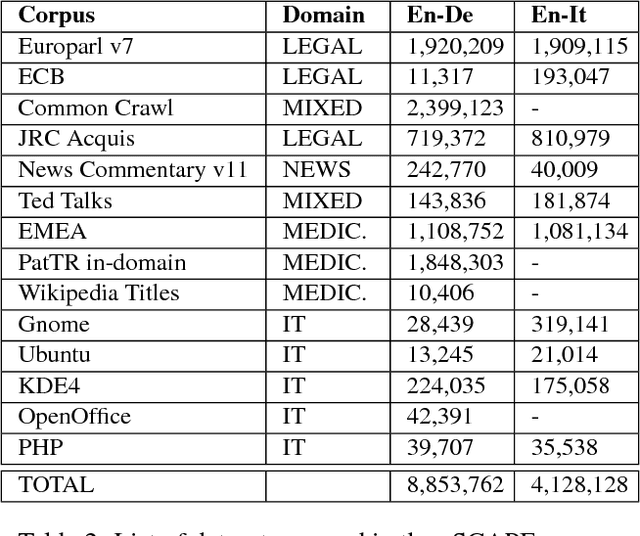
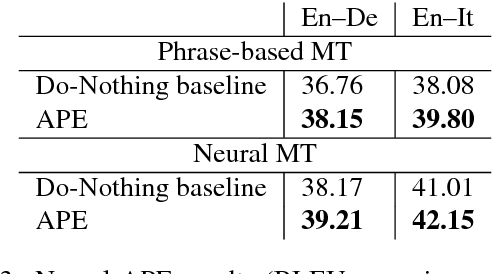
Training models for the automatic correction of machine-translated text usually relies on data consisting of (source, MT, human post- edit) triplets providing, for each source sentence, examples of translation errors with the corresponding corrections made by a human post-editor. Ideally, a large amount of data of this kind should allow the model to learn reliable correction patterns and effectively apply them at test stage on unseen (source, MT) pairs. In practice, however, their limited availability calls for solutions that also integrate in the training process other sources of knowledge. Along this direction, state-of-the-art results have been recently achieved by systems that, in addition to a limited amount of available training data, exploit artificial corpora that approximate elements of the "gold" training instances with automatic translations. Following this idea, we present eSCAPE, the largest freely-available Synthetic Corpus for Automatic Post-Editing released so far. eSCAPE consists of millions of entries in which the MT element of the training triplets has been obtained by translating the source side of publicly-available parallel corpora, and using the target side as an artificial human post-edit. Translations are obtained both with phrase-based and neural models. For each MT paradigm, eSCAPE contains 7.2 million triplets for English-German and 3.3 millions for English-Italian, resulting in a total of 14,4 and 6,6 million instances respectively. The usefulness of eSCAPE is proved through experiments in a general-domain scenario, the most challenging one for automatic post-editing. For both language directions, the models trained on our artificial data always improve MT quality with statistically significant gains. The current version of eSCAPE can be freely downloaded from: http://hltshare.fbk.eu/QT21/eSCAPE.html.