 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo What Degree Can Language Borders Be Blurred In BERT-based Multilingual Spoken Language Understanding?
Nov 10, 2020
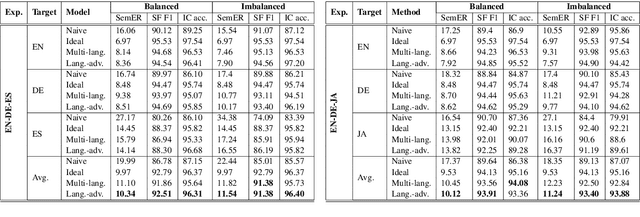
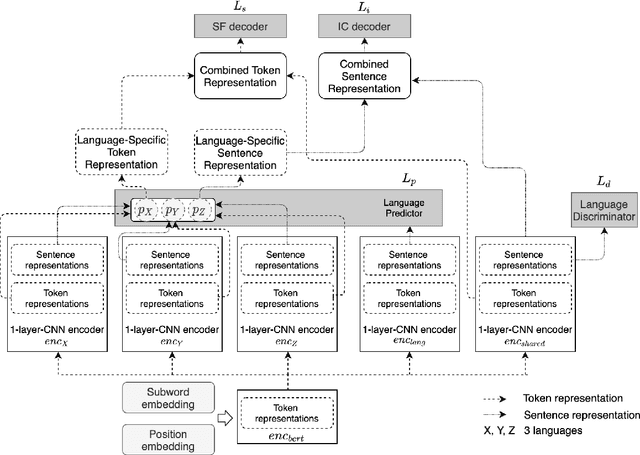
This paper addresses the question as to what degree a BERT-based multilingual Spoken Language Understanding (SLU) model can transfer knowledge across languages. Through experiments we will show that, although it works substantially well even on distant language groups, there is still a gap to the ideal multilingual performance. In addition, we propose a novel BERT-based adversarial model architecture to learn language-shared and language-specific representations for multilingual SLU. Our experimental results prove that the proposed model is capable of narrowing the gap to the ideal multilingual performance.
Data balancing for boosting performance of low-frequency classes in Spoken Language Understanding
Aug 06, 2020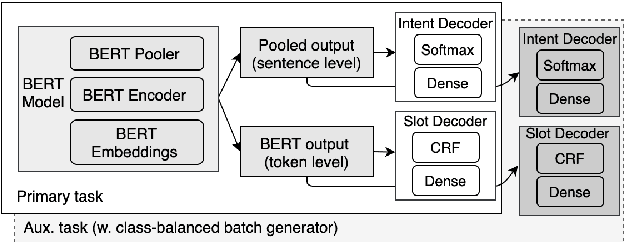
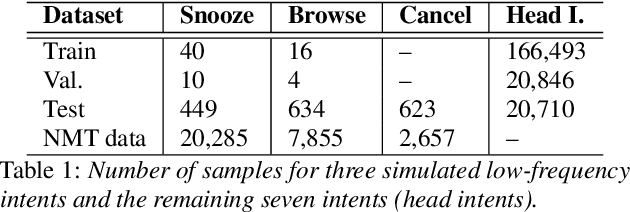
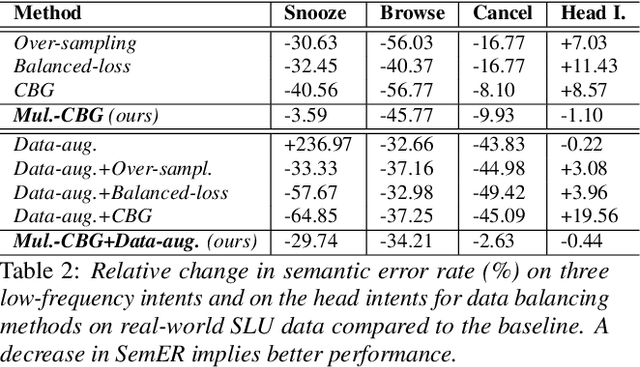
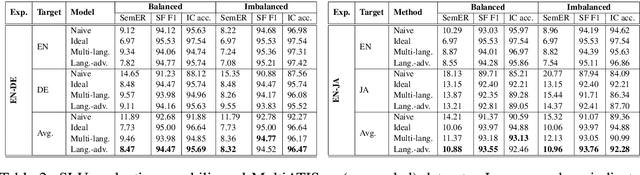
Despite the fact that data imbalance is becoming more and more common in real-world Spoken Language Understanding (SLU) applications, it has not been studied extensively in the literature. To the best of our knowledge, this paper presents the first systematic study on handling data imbalance for SLU. In particular, we discuss the application of existing data balancing techniques for SLU and propose a multi-task SLU model for intent classification and slot filling. Aiming to avoid over-fitting, in our model methods for data balancing are leveraged indirectly via an auxiliary task which makes use of a class-balanced batch generator and (possibly) synthetic data. Our results on a real-world dataset indicate that i) our proposed model can boost performance on low frequency intents significantly while avoiding a potential performance decrease on the head intents, ii) synthetic data are beneficial for bootstrapping new intents when realistic data are not available, but iii) once a certain amount of realistic data becomes available, using synthetic data in the auxiliary task only yields better performance than adding them to the primary task training data, and iv) in a joint training scenario, balancing the intent distribution individually improves not only intent classification but also slot filling performance.
Cross-lingual transfer learning for spoken language understanding
Apr 03, 2019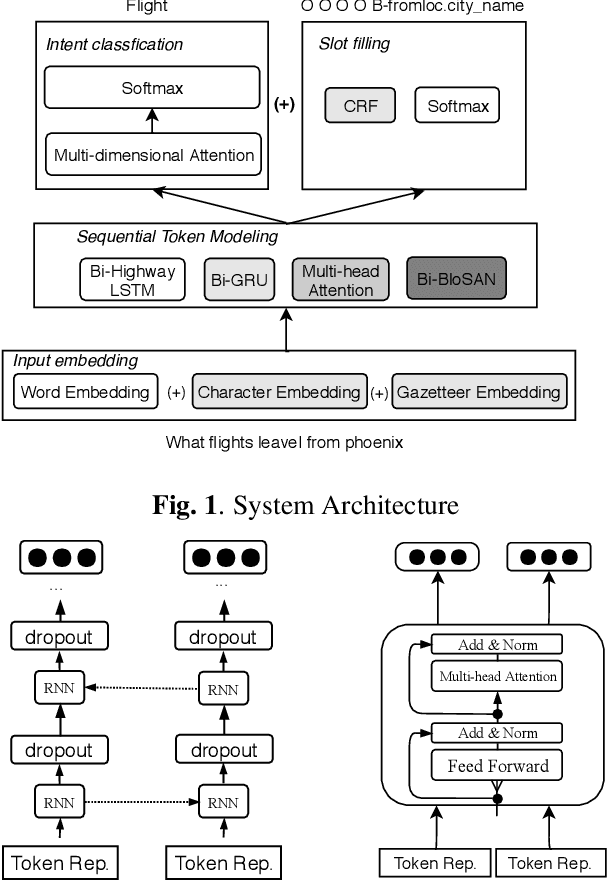
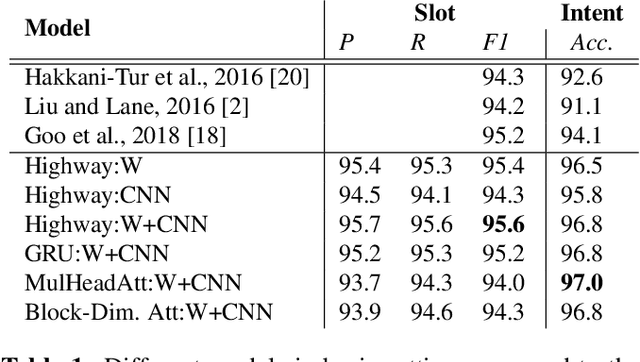
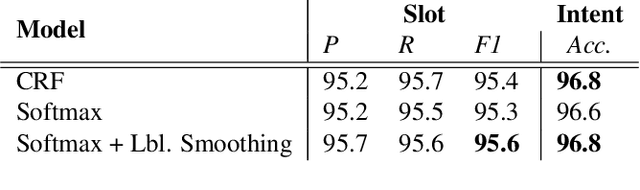
Typically, spoken language understanding (SLU) models are trained on annotated data which are costly to gather. Aiming to reduce data needs for bootstrapping a SLU system for a new language, we present a simple but effective weight transfer approach using data from another language. The approach is evaluated with our promising multi-task SLU framework developed towards different languages. We evaluate our approach on the ATIS and a real-world SLU dataset, showing that i) our monolingual models outperform the state-of-the-art, ii) we can reduce data amounts needed for bootstrapping a SLU system for a new language greatly, and iii) while multitask training improves over separate training, different weight transfer settings may work best for different SLU modules.
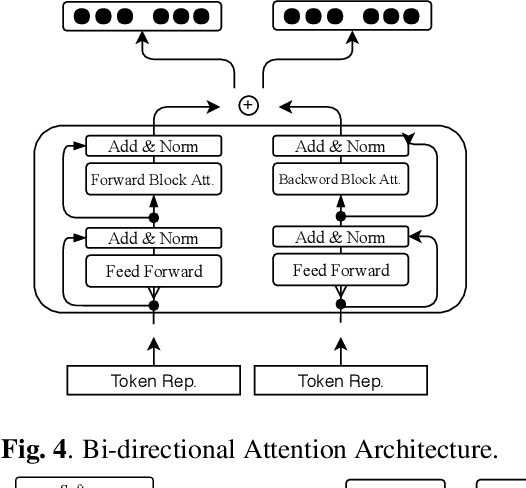
Neural Named Entity Recognition from Subword Units
Aug 27, 2018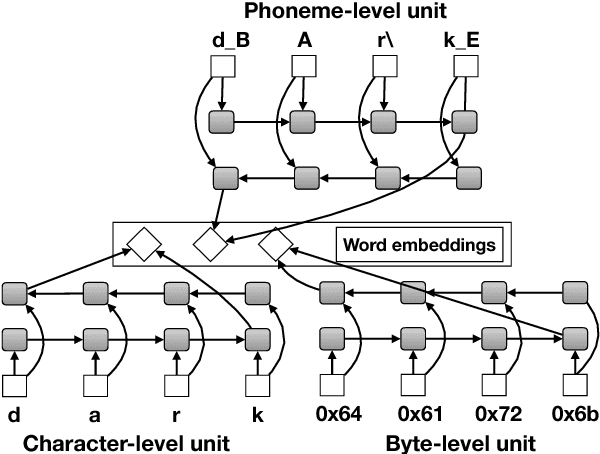

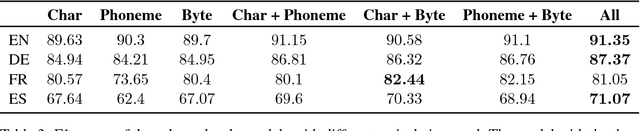
Named entity recognition (NER) is a vital task in language technology. Existing neural models for NER rely mostly on dedicated word-level representations, which suffer from two main shortcomings: 1) the vocabulary size is large, yielding large memory requirements and training time, and 2) they cannot learn morphological representations. We adopt a neural solution based on bidirectional LSTMs and conditional random fields, where we rely on subword units, namely characters, phonemes, and bytes, to remedy the above shortcomings. We conducted experiments on a large dataset covering four languages with up to 5.5M utterances per language. Our experiments show that 1) with increasing training data, performance of models trained solely on subword units becomes closer to that of models with dedicated word-level embeddings (91.35 vs 93.92 F1 for English), while using a much smaller vocabulary size (332 vs 74K), 2) subword units enhance models with dedicated word-level embeddings, and 3) combining different subword units improves performance.
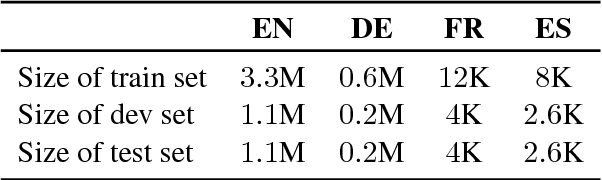
Selecting Machine-Translated Data for Quick Bootstrapping of a Natural Language Understanding System
May 23, 2018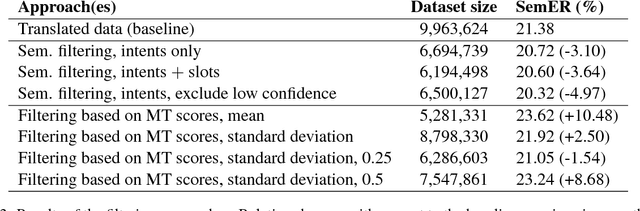

This paper investigates the use of Machine Translation (MT) to bootstrap a Natural Language Understanding (NLU) system for a new language for the use case of a large-scale voice-controlled device. The goal is to decrease the cost and time needed to get an annotated corpus for the new language, while still having a large enough coverage of user requests. Different methods of filtering MT data in order to keep utterances that improve NLU performance and language-specific post-processing methods are investigated. These methods are tested in a large-scale NLU task with translating around 10 millions training utterances from English to German. The results show a large improvement for using MT data over a grammar-based and over an in-house data collection baseline, while reducing the manual effort greatly. Both filtering and post-processing approaches improve results further.