 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCALICO: Conversational Agent Localization via Synthetic Data Generation
Dec 06, 2024



We present CALICO, a method to fine-tune Large Language Models (LLMs) to localize conversational agent training data from one language to another. For slots (named entities), CALICO supports three operations: verbatim copy, literal translation, and localization, i.e. generating slot values more appropriate in the target language, such as city and airport names located in countries where the language is spoken. Furthermore, we design an iterative filtering mechanism to discard noisy generated samples, which we show boosts the performance of the downstream conversational agent. To prove the effectiveness of CALICO, we build and release a new human-localized (HL) version of the MultiATIS++ travel information test set in 8 languages. Compared to the original human-translated (HT) version of the test set, we show that our new HL version is more challenging. We also show that CALICO out-performs state-of-the-art LINGUIST (which relies on literal slot translation out of context) both on the HT case, where CALICO generates more accurate slot translations, and on the HL case, where CALICO generates localized slots which are closer to the HL test set.
AlexaTM 20B: Few-Shot Learning Using a Large-Scale Multilingual Seq2Seq Model
Aug 03, 2022


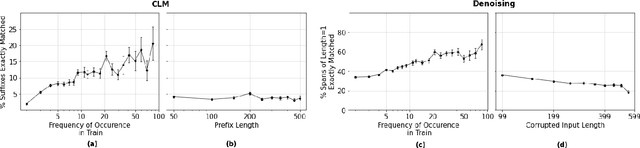
In this work, we demonstrate that multilingual large-scale sequence-to-sequence (seq2seq) models, pre-trained on a mixture of denoising and Causal Language Modeling (CLM) tasks, are more efficient few-shot learners than decoder-only models on various tasks. In particular, we train a 20 billion parameter multilingual seq2seq model called Alexa Teacher Model (AlexaTM 20B) and show that it achieves state-of-the-art (SOTA) performance on 1-shot summarization tasks, outperforming a much larger 540B PaLM decoder model. AlexaTM 20B also achieves SOTA in 1-shot machine translation, especially for low-resource languages, across almost all language pairs supported by the model (Arabic, English, French, German, Hindi, Italian, Japanese, Marathi, Portuguese, Spanish, Tamil, and Telugu) on Flores-101 dataset. We also show in zero-shot setting, AlexaTM 20B outperforms GPT3 (175B) on SuperGLUE and SQuADv2 datasets and provides SOTA performance on multilingual tasks such as XNLI, XCOPA, Paws-X, and XWinograd. Overall, our results present a compelling case for seq2seq models as a powerful alternative to decoder-only models for Large-scale Language Model (LLM) training.
Alexa Teacher Model: Pretraining and Distilling Multi-Billion-Parameter Encoders for Natural Language Understanding Systems
Jun 15, 2022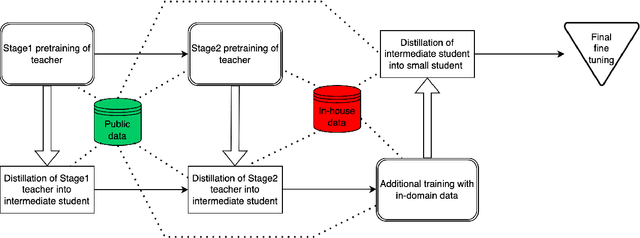
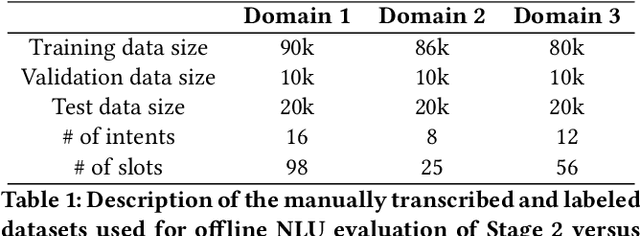
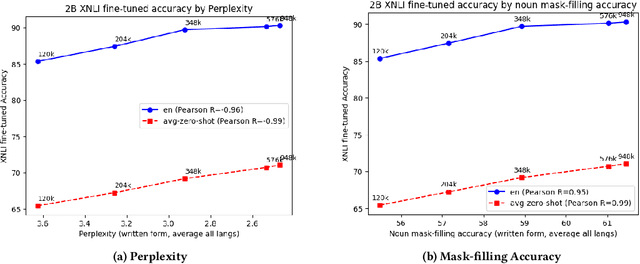
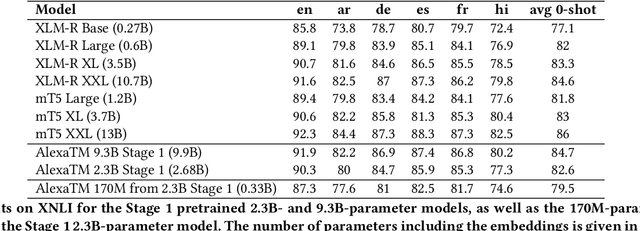
We present results from a large-scale experiment on pretraining encoders with non-embedding parameter counts ranging from 700M to 9.3B, their subsequent distillation into smaller models ranging from 17M-170M parameters, and their application to the Natural Language Understanding (NLU) component of a virtual assistant system. Though we train using 70% spoken-form data, our teacher models perform comparably to XLM-R and mT5 when evaluated on the written-form Cross-lingual Natural Language Inference (XNLI) corpus. We perform a second stage of pretraining on our teacher models using in-domain data from our system, improving error rates by 3.86% relative for intent classification and 7.01% relative for slot filling. We find that even a 170M-parameter model distilled from our Stage 2 teacher model has 2.88% better intent classification and 7.69% better slot filling error rates when compared to the 2.3B-parameter teacher trained only on public data (Stage 1), emphasizing the importance of in-domain data for pretraining. When evaluated offline using labeled NLU data, our 17M-parameter Stage 2 distilled model outperforms both XLM-R Base (85M params) and DistillBERT (42M params) by 4.23% to 6.14%, respectively. Finally, we present results from a full virtual assistant experimentation platform, where we find that models trained using our pretraining and distillation pipeline outperform models distilled from 85M-parameter teachers by 3.74%-4.91% on an automatic measurement of full-system user dissatisfaction.
* KDD 2022
Data balancing for boosting performance of low-frequency classes in Spoken Language Understanding
Aug 06, 2020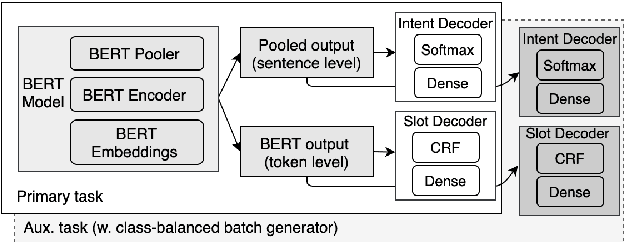
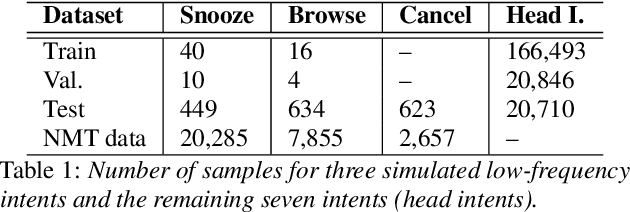
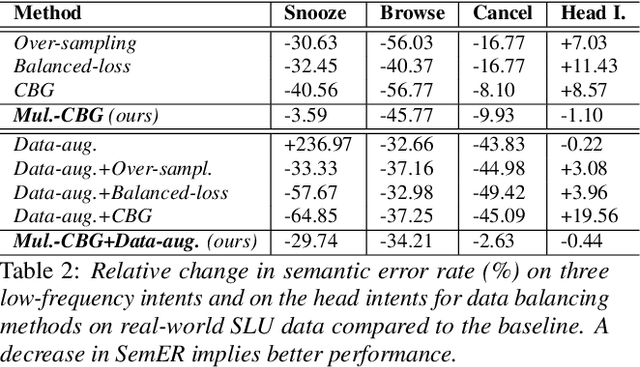
Despite the fact that data imbalance is becoming more and more common in real-world Spoken Language Understanding (SLU) applications, it has not been studied extensively in the literature. To the best of our knowledge, this paper presents the first systematic study on handling data imbalance for SLU. In particular, we discuss the application of existing data balancing techniques for SLU and propose a multi-task SLU model for intent classification and slot filling. Aiming to avoid over-fitting, in our model methods for data balancing are leveraged indirectly via an auxiliary task which makes use of a class-balanced batch generator and (possibly) synthetic data. Our results on a real-world dataset indicate that i) our proposed model can boost performance on low frequency intents significantly while avoiding a potential performance decrease on the head intents, ii) synthetic data are beneficial for bootstrapping new intents when realistic data are not available, but iii) once a certain amount of realistic data becomes available, using synthetic data in the auxiliary task only yields better performance than adding them to the primary task training data, and iv) in a joint training scenario, balancing the intent distribution individually improves not only intent classification but also slot filling performance.