 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALLaM: Large Language Models for Arabic and English
Jul 22, 2024



We present ALLaM: Arabic Large Language Model, a series of large language models to support the ecosystem of Arabic Language Technologies (ALT). ALLaM is carefully trained considering the values of language alignment and knowledge transfer at scale. Our autoregressive decoder-only architecture models demonstrate how second-language acquisition via vocabulary expansion and pretraining on a mixture of Arabic and English text can steer a model towards a new language (Arabic) without any catastrophic forgetting in the original language (English). Furthermore, we highlight the effectiveness of using parallel/translated data to aid the process of knowledge alignment between languages. Finally, we show that extensive alignment with human preferences can significantly enhance the performance of a language model compared to models of a larger scale with lower quality alignment. ALLaM achieves state-of-the-art performance in various Arabic benchmarks, including MMLU Arabic, ACVA, and Arabic Exams. Our aligned models improve both in Arabic and English from their base aligned models.
Look before you Hop: Conversational Question Answering over Knowledge Graphs Using Judicious Context Expansion
Nov 05, 2019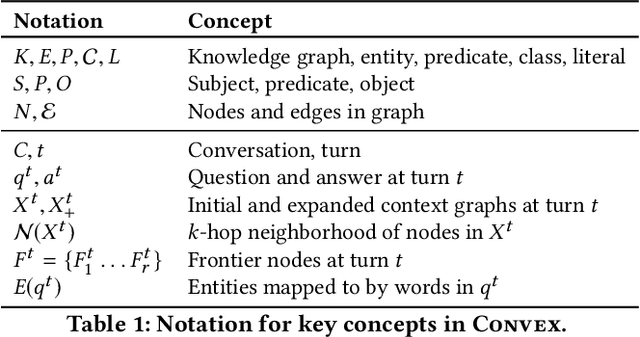


Fact-centric information needs are rarely one-shot; users typically ask follow-up questions to explore a topic. In such a conversational setting, the user's inputs are often incomplete, with entities or predicates left out, and ungrammatical phrases. This poses a huge challenge to question answering (QA) systems that typically rely on cues in full-fledged interrogative sentences. As a solution, we develop CONVEX: an unsupervised method that can answer incomplete questions over a knowledge graph (KG) by maintaining conversation context using entities and predicates seen so far and automatically inferring missing or ambiguous pieces for follow-up questions. The core of our method is a graph exploration algorithm that judiciously expands a frontier to find candidate answers for the current question. To evaluate CONVEX, we release ConvQuestions, a crowdsourced benchmark with 11,200 distinct conversations from five different domains. We show that CONVEX: (i) adds conversational support to any stand-alone QA system, and (ii) outperforms state-of-the-art baselines and question completion strategies.
* CIKM 2019 Long Paper, 10 pages
TEQUILA: Temporal Question Answering over Knowledge Bases
Aug 15, 2019


Question answering over knowledge bases (KB-QA) poses challenges in handling complex questions that need to be decomposed into sub-questions. An important case, addressed here, is that of temporal questions, where cues for temporal relations need to be discovered and handled. We present TEQUILA, an enabler method for temporal QA that can run on top of any KB-QA engine. TEQUILA has four stages. It detects if a question has temporal intent. It decomposes and rewrites the question into non-temporal sub-questions and temporal constraints. Answers to sub-questions are then retrieved from the underlying KB-QA engine. Finally, TEQUILA uses constraint reasoning on temporal intervals to compute final answers to the full question. Comparisons against state-of-the-art baselines show the viability of our method.
ComQA: A Community-sourced Dataset for Complex Factoid Question Answering with Paraphrase Clusters
Sep 25, 2018
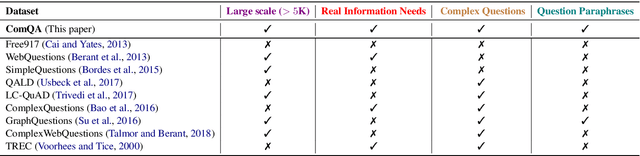


To bridge the gap between the capabilities of the state-of-the-art in factoid question answering (QA) and what real users ask, we need large datasets of real user questions that capture the various question phenomena users are interested in, and the diverse ways in which these questions are formulated. We introduce ComQA, a large dataset of real user questions that exhibit different challenging aspects such as temporal reasoning, compositionality, etc. ComQA questions come from the WikiAnswers community QA platform. Through a large crowdsourcing effort, we clean the question dataset, group questions into paraphrase clusters, and annotate clusters with their answers. ComQA contains 11,214 questions grouped into 4,834 paraphrase clusters. We detail the process of constructing ComQA, including the measures taken to ensure its high quality while making effective use of crowdsourcing. We also present an extensive analysis of the dataset and the results achieved by state-of-the-art systems on ComQA, demonstrating that our dataset can be a driver of future research on QA.
Neural Named Entity Recognition from Subword Units
Aug 27, 2018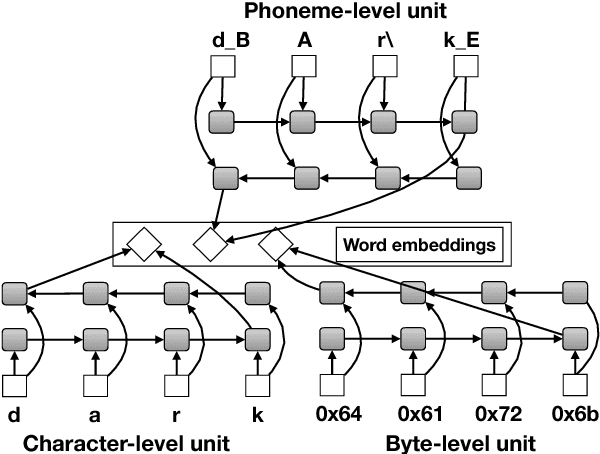
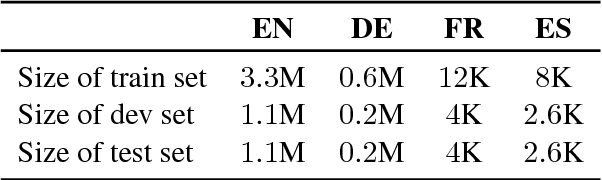

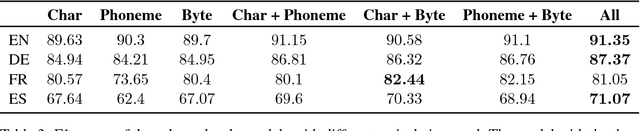
Named entity recognition (NER) is a vital task in language technology. Existing neural models for NER rely mostly on dedicated word-level representations, which suffer from two main shortcomings: 1) the vocabulary size is large, yielding large memory requirements and training time, and 2) they cannot learn morphological representations. We adopt a neural solution based on bidirectional LSTMs and conditional random fields, where we rely on subword units, namely characters, phonemes, and bytes, to remedy the above shortcomings. We conducted experiments on a large dataset covering four languages with up to 5.5M utterances per language. Our experiments show that 1) with increasing training data, performance of models trained solely on subword units becomes closer to that of models with dedicated word-level embeddings (91.35 vs 93.92 F1 for English), while using a much smaller vocabulary size (332 vs 74K), 2) subword units enhance models with dedicated word-level embeddings, and 3) combining different subword units improves performance.