 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComQA: A Community-sourced Dataset for Complex Factoid Question Answering with Paraphrase Clusters
Paper and Code
Sep 25, 2018
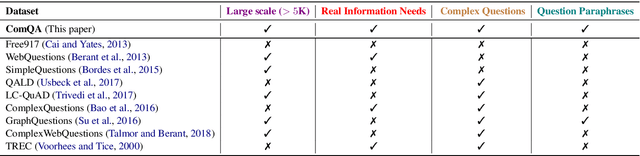


To bridge the gap between the capabilities of the state-of-the-art in factoid question answering (QA) and what real users ask, we need large datasets of real user questions that capture the various question phenomena users are interested in, and the diverse ways in which these questions are formulated. We introduce ComQA, a large dataset of real user questions that exhibit different challenging aspects such as temporal reasoning, compositionality, etc. ComQA questions come from the WikiAnswers community QA platform. Through a large crowdsourcing effort, we clean the question dataset, group questions into paraphrase clusters, and annotate clusters with their answers. ComQA contains 11,214 questions grouped into 4,834 paraphrase clusters. We detail the process of constructing ComQA, including the measures taken to ensure its high quality while making effective use of crowdsourcing. We also present an extensive analysis of the dataset and the results achieved by state-of-the-art systems on ComQA, demonstrating that our dataset can be a driver of future research on QA.