 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual transfer learning for spoken language understanding
Paper and Code
Apr 03, 2019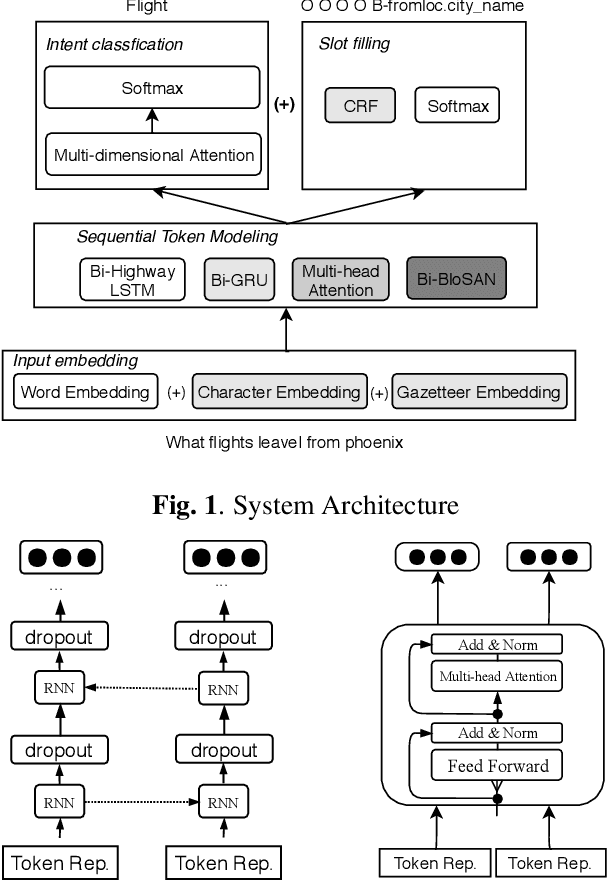
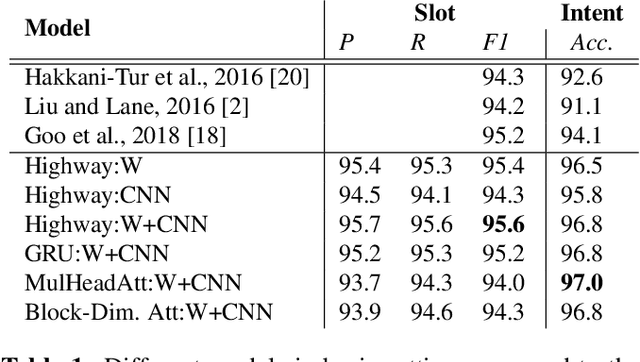
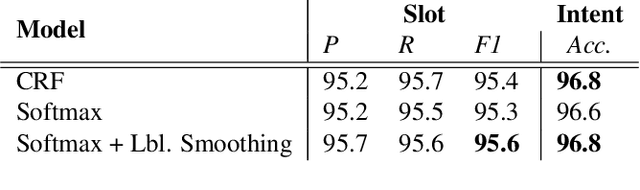
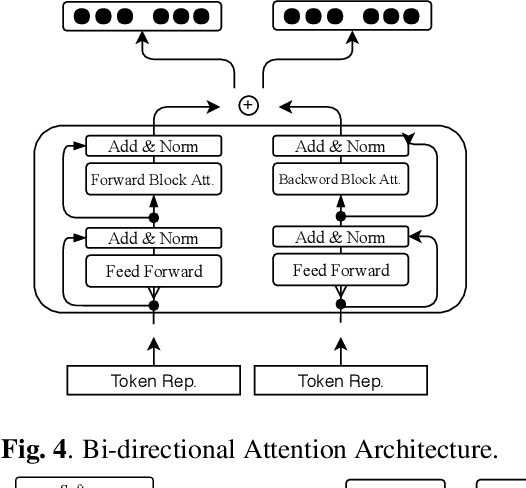
Typically, spoken language understanding (SLU) models are trained on annotated data which are costly to gather. Aiming to reduce data needs for bootstrapping a SLU system for a new language, we present a simple but effective weight transfer approach using data from another language. The approach is evaluated with our promising multi-task SLU framework developed towards different languages. We evaluate our approach on the ATIS and a real-world SLU dataset, showing that i) our monolingual models outperform the state-of-the-art, ii) we can reduce data amounts needed for bootstrapping a SLU system for a new language greatly, and iii) while multitask training improves over separate training, different weight transfer settings may work best for different SLU modules.