 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Post-Editing for Machine Translation
Paper and Code

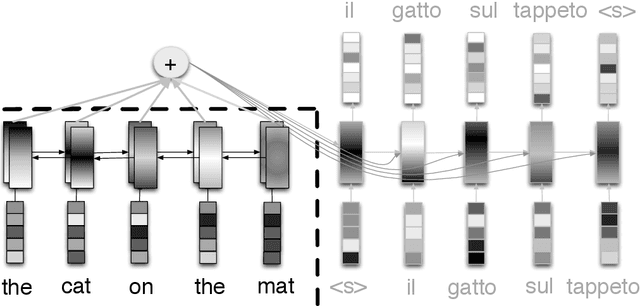
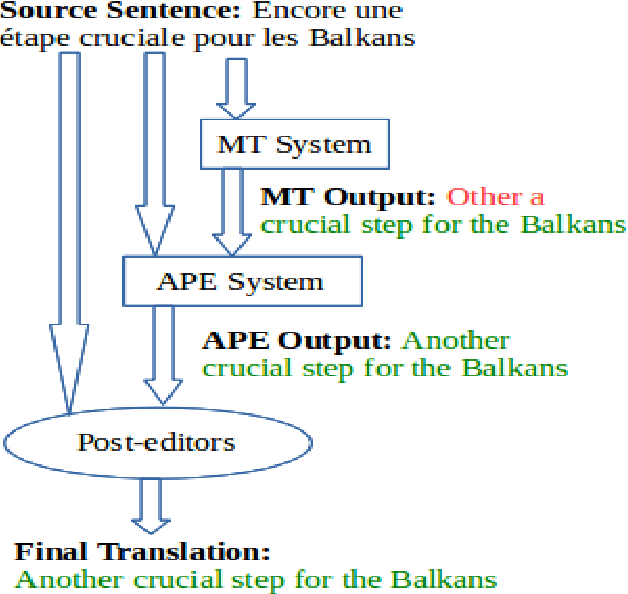
Automatic Post-Editing (APE) aims to correct systematic errors in a machine translated text. This is primarily useful when the machine translation (MT) system is not accessible for improvement, leaving APE as a viable option to improve translation quality as a downstream task - which is the focus of this thesis. This field has received less attention compared to MT due to several reasons, which include: the limited availability of data to perform a sound research, contrasting views reported by different researchers about the effectiveness of APE, and limited attention from the industry to use APE in current production pipelines. In this thesis, we perform a thorough investigation of APE as a downstream task in order to: i) understand its potential to improve translation quality; ii) advance the core technology - starting from classical methods to recent deep-learning based solutions; iii) cope with limited and sparse data; iv) better leverage multiple input sources; v) mitigate the task-specific problem of over-correction; vi) enhance neural decoding to leverage external knowledge; and vii) establish an online learning framework to handle data diversity in real-time. All the above contributions are discussed across several chapters, and most of them are evaluated in the APE shared task organized each year at the Conference on Machine Translation. Our efforts in improving the technology resulted in the best system at the 2017 APE shared task, and our work on online learning received a distinguished paper award at the Italian Conference on Computational Linguistics. Overall, outcomes and findings of our work have boost interest among researchers and attracted industries to examine this technology to solve real-word problems.