 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Tolerance of Neural Machine Translation Systems Against Speech Recognition Errors
Apr 24, 2019
Machine translation systems are conventionally trained on textual resources that do not model phenomena that occur in spoken language. While the evaluation of neural machine translation systems on textual inputs is actively researched in the literature , little has been discovered about the complexities of translating spoken language data with neural models. We introduce and motivate interesting problems one faces when considering the translation of automatic speech recognition (ASR) outputs on neural machine translation (NMT) systems. We test the robustness of sentence encoding approaches for NMT encoder-decoder modeling, focusing on word-based over byte-pair encoding. We compare the translation of utterances containing ASR errors in state-of-the-art NMT encoder-decoder systems against a strong phrase-based machine translation baseline in order to better understand which phenomena present in ASR outputs are better represented under the NMT framework than approaches that represent translation as a linear model.
eSCAPE: a Large-scale Synthetic Corpus for Automatic Post-Editing
Mar 20, 2018
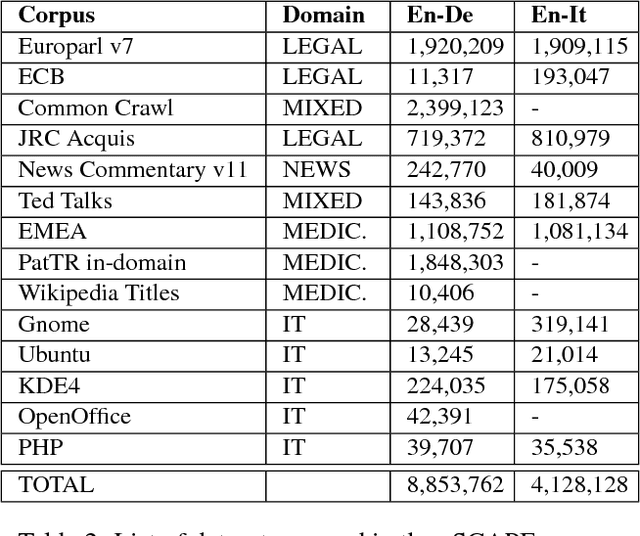
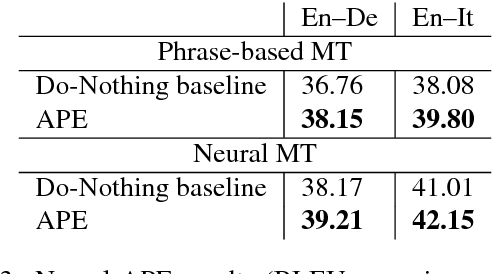
Training models for the automatic correction of machine-translated text usually relies on data consisting of (source, MT, human post- edit) triplets providing, for each source sentence, examples of translation errors with the corresponding corrections made by a human post-editor. Ideally, a large amount of data of this kind should allow the model to learn reliable correction patterns and effectively apply them at test stage on unseen (source, MT) pairs. In practice, however, their limited availability calls for solutions that also integrate in the training process other sources of knowledge. Along this direction, state-of-the-art results have been recently achieved by systems that, in addition to a limited amount of available training data, exploit artificial corpora that approximate elements of the "gold" training instances with automatic translations. Following this idea, we present eSCAPE, the largest freely-available Synthetic Corpus for Automatic Post-Editing released so far. eSCAPE consists of millions of entries in which the MT element of the training triplets has been obtained by translating the source side of publicly-available parallel corpora, and using the target side as an artificial human post-edit. Translations are obtained both with phrase-based and neural models. For each MT paradigm, eSCAPE contains 7.2 million triplets for English-German and 3.3 millions for English-Italian, resulting in a total of 14,4 and 6,6 million instances respectively. The usefulness of eSCAPE is proved through experiments in a general-domain scenario, the most challenging one for automatic post-editing. For both language directions, the models trained on our artificial data always improve MT quality with statistically significant gains. The current version of eSCAPE can be freely downloaded from: http://hltshare.fbk.eu/QT21/eSCAPE.html.