 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustera: A Live Conversation Redaction System
Mar 16, 2023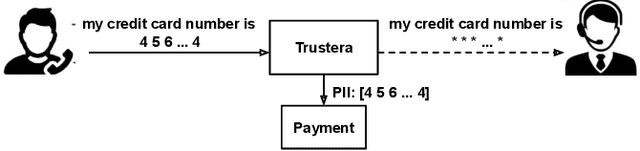
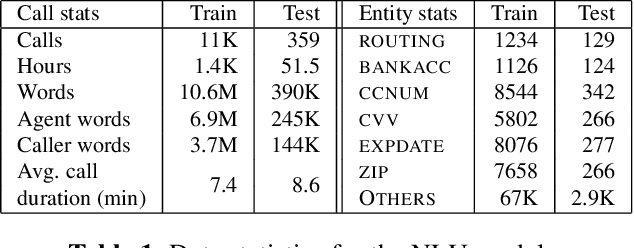

Trustera, the first functional system that redacts personally identifiable information (PII) in real-time spoken conversations to remove agents' need to hear sensitive information while preserving the naturalness of live customer-agent conversations. As opposed to post-call redaction, audio masking starts as soon as the customer begins speaking to a PII entity. This significantly reduces the risk of PII being intercepted or stored in insecure data storage. Trustera's architecture consists of a pipeline of automatic speech recognition, natural language understanding, and a live audio redactor module. The system's goal is three-fold: redact entities that are PII, mask the audio that goes to the agent, and at the same time capture the entity, so that the captured PII can be used for a payment transaction or caller identification. Trustera is currently being used by thousands of agents to secure customers' sensitive information.
Phonetically-Oriented Word Error Alignment for Speech Recognition Error Analysis in Speech Translation
Apr 24, 2019
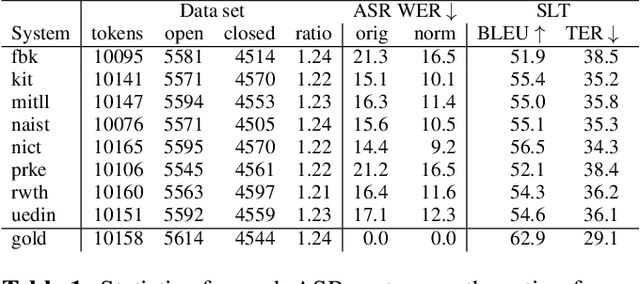
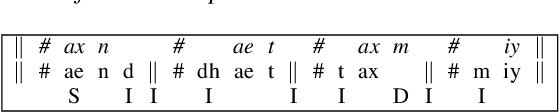
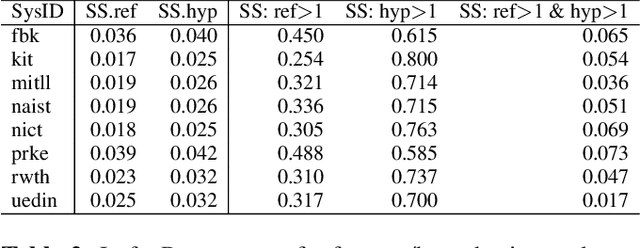
We propose a variation to the commonly used Word Error Rate (WER) metric for speech recognition evaluation which incorporates the alignment of phonemes, in the absence of time boundary information. After computing the Levenshtein alignment on words in the reference and hypothesis transcripts, spans of adjacent errors are converted into phonemes with word and syllable boundaries and a phonetic Levenshtein alignment is performed. The aligned phonemes are recombined into aligned words that adjust the word alignment labels in each error region. We demonstrate that our Phonetically-Oriented Word Error Rate (POWER) yields similar scores to WER with the added advantages of better word alignments and the ability to capture one-to-many word alignments corresponding to homophonic errors in speech recognition hypotheses. These improved alignments allow us to better trace the impact of Levenshtein error types on downstream tasks such as speech translation.
Assessing the Tolerance of Neural Machine Translation Systems Against Speech Recognition Errors
Apr 24, 2019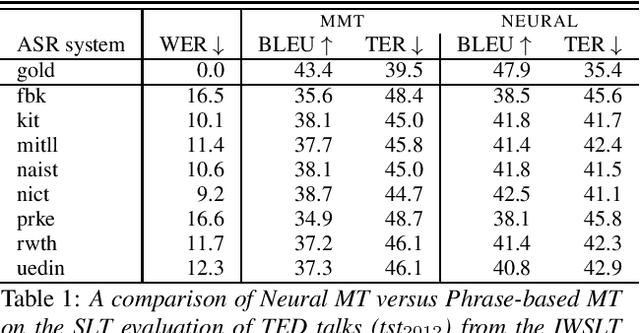
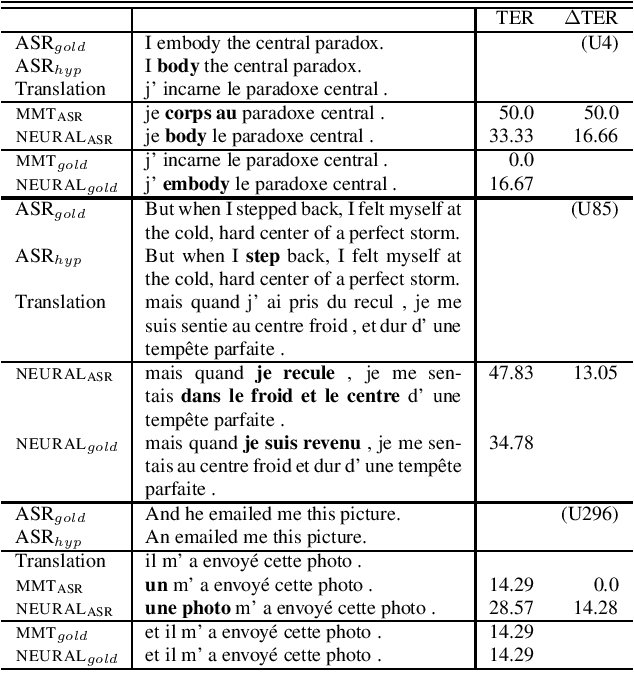
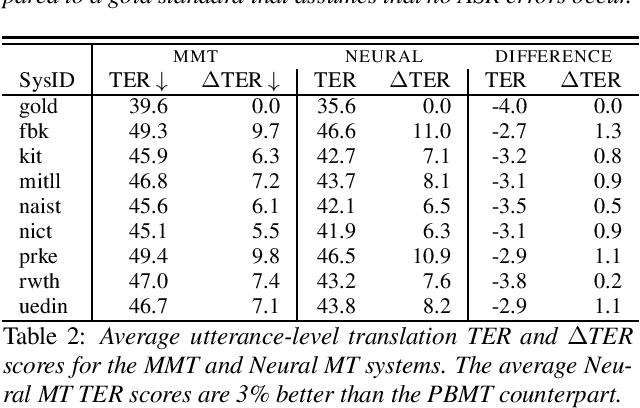
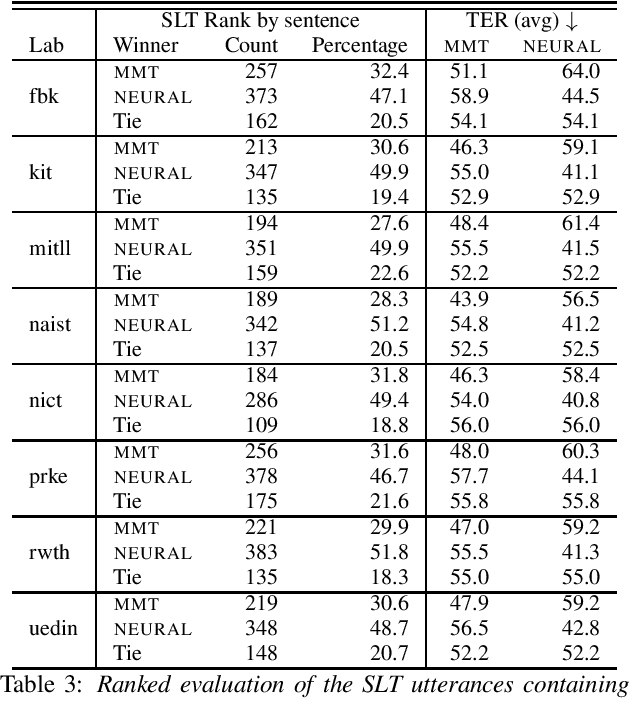
Machine translation systems are conventionally trained on textual resources that do not model phenomena that occur in spoken language. While the evaluation of neural machine translation systems on textual inputs is actively researched in the literature , little has been discovered about the complexities of translating spoken language data with neural models. We introduce and motivate interesting problems one faces when considering the translation of automatic speech recognition (ASR) outputs on neural machine translation (NMT) systems. We test the robustness of sentence encoding approaches for NMT encoder-decoder modeling, focusing on word-based over byte-pair encoding. We compare the translation of utterances containing ASR errors in state-of-the-art NMT encoder-decoder systems against a strong phrase-based machine translation baseline in order to better understand which phenomena present in ASR outputs are better represented under the NMT framework than approaches that represent translation as a linear model.
Bootstrapping Multilingual Intent Models via Machine Translation for Dialog Automation
May 11, 2018
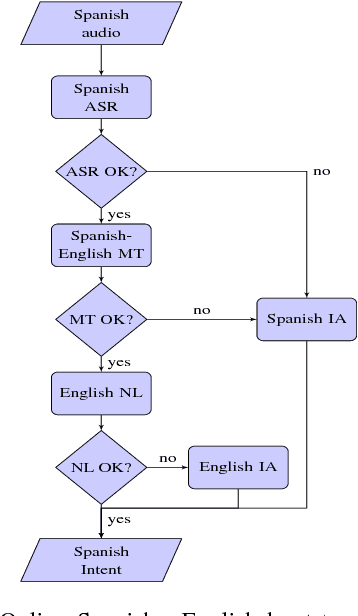
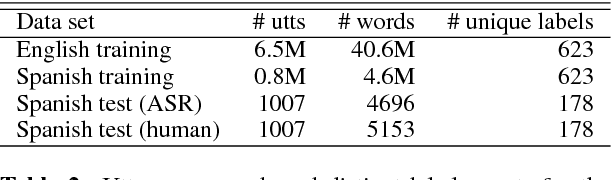
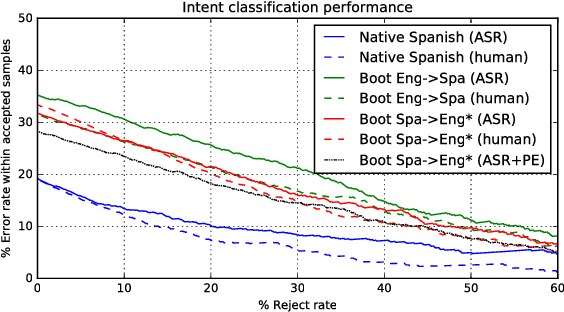
With the resurgence of chat-based dialog systems in consumer and enterprise applications, there has been much success in developing data-driven and rule-based natural language models to understand human intent. Since these models require large amounts of data and in-domain knowledge, expanding an equivalent service into new markets is disrupted by language barriers that inhibit dialog automation. This paper presents a user study to evaluate the utility of out-of-the-box machine translation technology to (1) rapidly bootstrap multilingual spoken dialog systems and (2) enable existing human analysts to understand foreign language utterances. We additionally evaluate the utility of machine translation in human assisted environments, where a portion of the traffic is processed by analysts. In English->Spanish experiments, we observe a high potential for dialog automation, as well as the potential for human analysts to process foreign language utterances with high accuracy.