 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Language Models to Explain Their Own Computations
Nov 11, 2025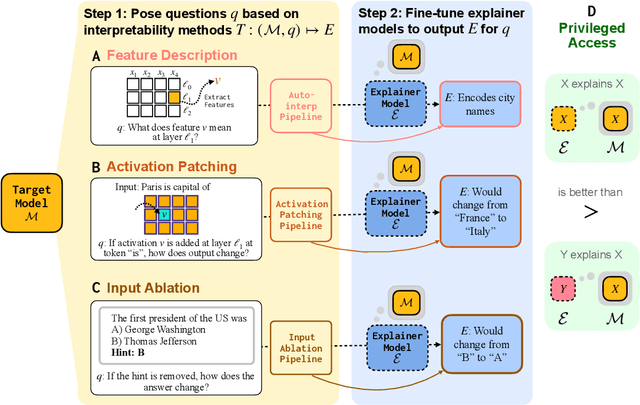
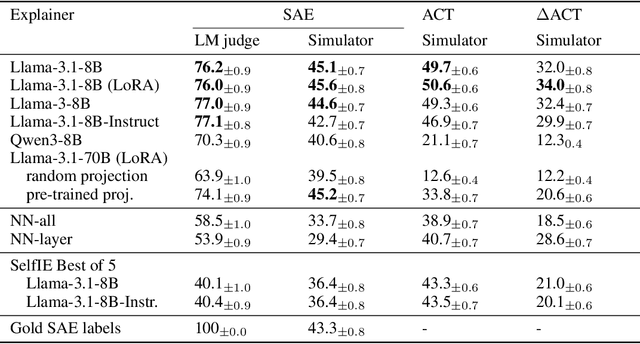
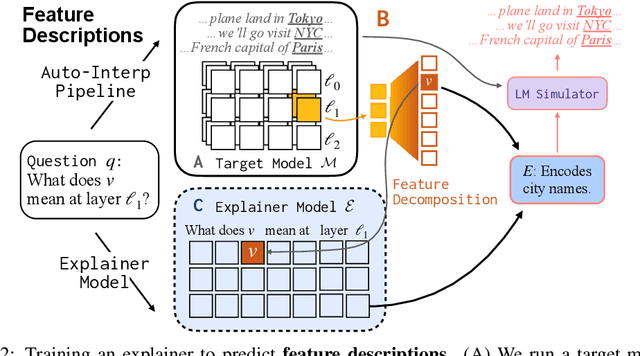
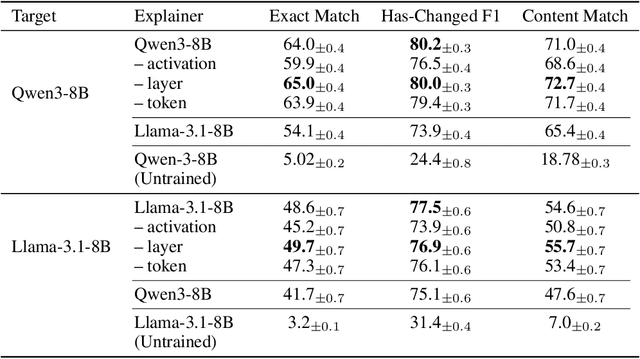
Can language models (LMs) learn to faithfully describe their internal computations? Are they better able to describe themselves than other models? We study the extent to which LMs' privileged access to their own internals can be leveraged to produce new techniques for explaining their behavior. Using existing interpretability techniques as a source of ground truth, we fine-tune LMs to generate natural language descriptions of (1) the information encoded by LM features, (2) the causal structure of LMs' internal activations, and (3) the influence of specific input tokens on LM outputs. When trained with only tens of thousands of example explanations, explainer models exhibit non-trivial generalization to new queries. This generalization appears partly attributable to explainer models' privileged access to their own internals: using a model to explain its own computations generally works better than using a *different* model to explain its computations (even if the other model is significantly more capable). Our results suggest not only that LMs can learn to reliably explain their internal computations, but that such explanations offer a scalable complement to existing interpretability methods.
QuestBench: Can LLMs ask the right question to acquire information in reasoning tasks?
Mar 28, 2025Recently, a large amount of work has focused on improving large language models' (LLMs') performance on reasoning benchmarks such as math and logic. However, past work has largely assumed that tasks are well-defined. In the real world, queries to LLMs are often underspecified, only solvable through acquiring missing information. We formalize this as a constraint satisfaction problem (CSP) with missing variable assignments. Using a special case of this formalism where only one necessary variable assignment is missing, we can rigorously evaluate an LLM's ability to identify the minimal necessary question to ask and quantify axes of difficulty levels for each problem. We present QuestBench, a set of underspecified reasoning tasks solvable by asking at most one question, which includes: (1) Logic-Q: Logical reasoning tasks with one missing proposition, (2) Planning-Q: PDDL planning problems with initial states that are partially-observed, (3) GSM-Q: Human-annotated grade school math problems with one missing variable assignment, and (4) GSME-Q: a version of GSM-Q where word problems are translated into equations by human annotators. The LLM is tasked with selecting the correct clarification question(s) from a list of options. While state-of-the-art models excel at GSM-Q and GSME-Q, their accuracy is only 40-50% on Logic-Q and Planning-Q. Analysis demonstrates that the ability to solve well-specified reasoning problems may not be sufficient for success on our benchmark: models have difficulty identifying the right question to ask, even when they can solve the fully specified version of the problem. Furthermore, in the Planning-Q domain, LLMs tend not to hedge, even when explicitly presented with the option to predict ``not sure.'' This highlights the need for deeper investigation into models' information acquisition capabilities.
(How) Do Language Models Track State?
Mar 04, 2025Transformer language models (LMs) exhibit behaviors -- from storytelling to code generation -- that appear to require tracking the unobserved state of an evolving world. How do they do so? We study state tracking in LMs trained or fine-tuned to compose permutations (i.e., to compute the order of a set of objects after a sequence of swaps). Despite the simple algebraic structure of this problem, many other tasks (e.g., simulation of finite automata and evaluation of boolean expressions) can be reduced to permutation composition, making it a natural model for state tracking in general. We show that LMs consistently learn one of two state tracking mechanisms for this task. The first closely resembles the "associative scan" construction used in recent theoretical work by Liu et al. (2023) and Merrill et al. (2024). The second uses an easy-to-compute feature (permutation parity) to partially prune the space of outputs, then refines this with an associative scan. The two mechanisms exhibit markedly different robustness properties, and we show how to steer LMs toward one or the other with intermediate training tasks that encourage or suppress the heuristics. Our results demonstrate that transformer LMs, whether pretrained or fine-tuned, can learn to implement efficient and interpretable state tracking mechanisms, and the emergence of these mechanisms can be predicted and controlled.
Adaptive Language-Guided Abstraction from Contrastive Explanations
Sep 12, 2024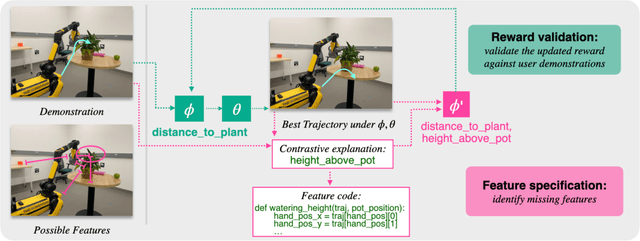
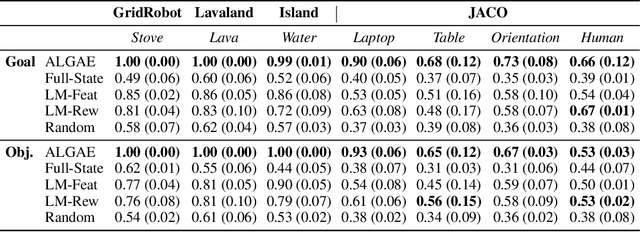

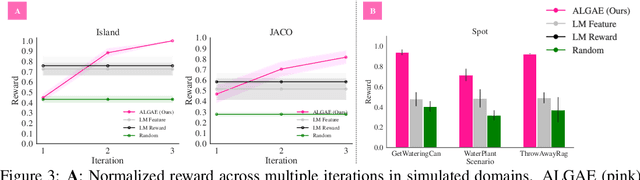
Many approaches to robot learning begin by inferring a reward function from a set of human demonstrations. To learn a good reward, it is necessary to determine which features of the environment are relevant before determining how these features should be used to compute reward. End-to-end methods for joint feature and reward learning (e.g., using deep networks or program synthesis techniques) often yield brittle reward functions that are sensitive to spurious state features. By contrast, humans can often generalizably learn from a small number of demonstrations by incorporating strong priors about what features of a demonstration are likely meaningful for a task of interest. How do we build robots that leverage this kind of background knowledge when learning from new demonstrations? This paper describes a method named ALGAE (Adaptive Language-Guided Abstraction from [Contrastive] Explanations) which alternates between using language models to iteratively identify human-meaningful features needed to explain demonstrated behavior, then standard inverse reinforcement learning techniques to assign weights to these features. Experiments across a variety of both simulated and real-world robot environments show that ALGAE learns generalizable reward functions defined on interpretable features using only small numbers of demonstrations. Importantly, ALGAE can recognize when features are missing, then extract and define those features without any human input -- making it possible to quickly and efficiently acquire rich representations of user behavior.
Language Modeling with Editable External Knowledge
Jun 17, 2024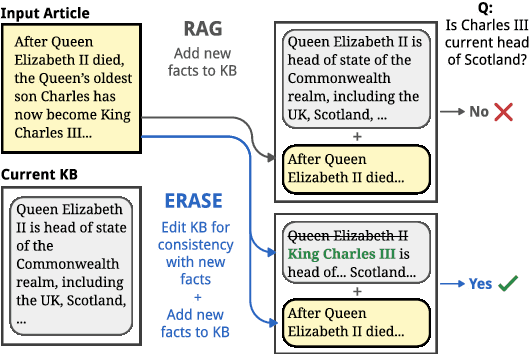
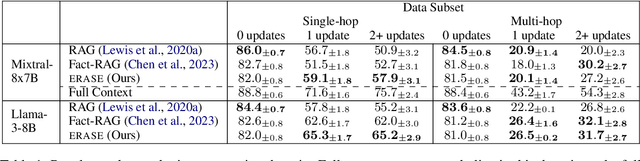
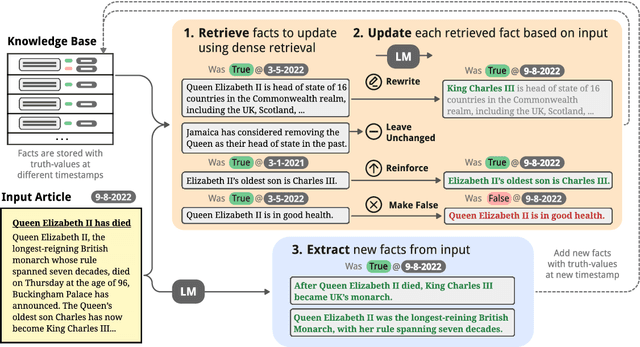
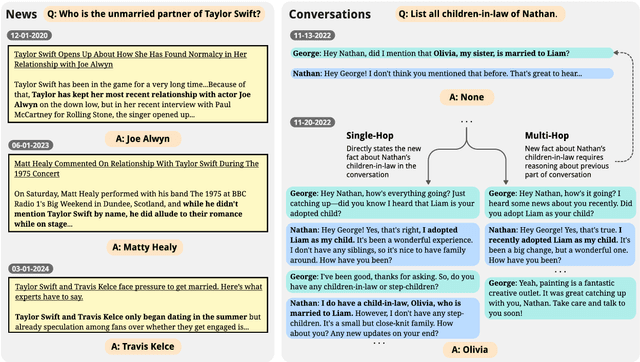
When the world changes, so does the text that humans write about it. How do we build language models that can be easily updated to reflect these changes? One popular approach is retrieval-augmented generation, in which new documents are inserted into a knowledge base and retrieved during prediction for downstream tasks. Most prior work on these systems have focused on improving behavior during prediction through better retrieval or reasoning. This paper introduces ERASE, which instead improves model behavior when new documents are acquired, by incrementally deleting or rewriting other entries in the knowledge base each time a document is added. In two new benchmark datasets evaluating models' ability to answer questions about a stream of news articles or conversations, ERASE improves accuracy relative to conventional retrieval-augmented generation by 7-13% (Mixtral-8x7B) and 6-10% (Llama-3-8B) absolute. Code and data are available at https://github.com/belindal/ERASE
Bayesian Preference Elicitation with Language Models
Mar 08, 2024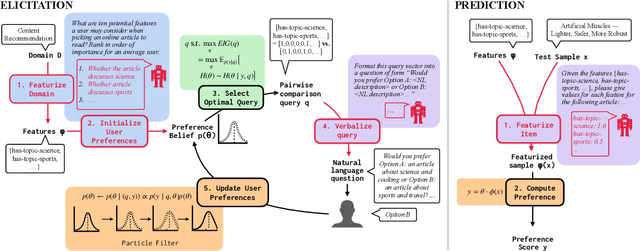
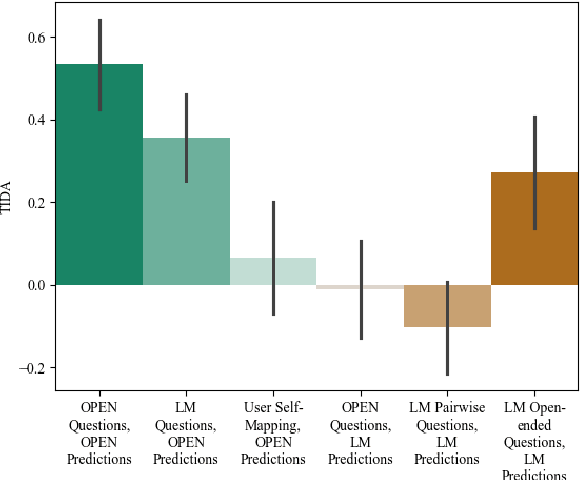
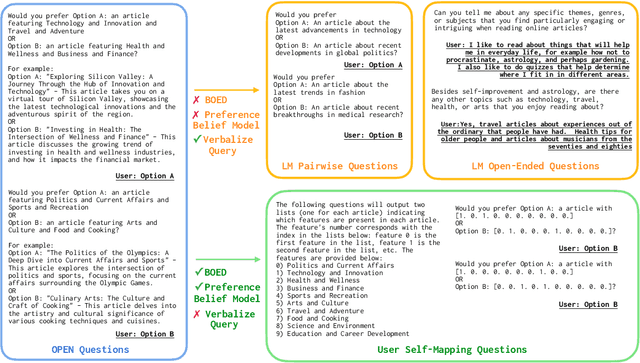

Aligning AI systems to users' interests requires understanding and incorporating humans' complex values and preferences. Recently, language models (LMs) have been used to gather information about the preferences of human users. This preference data can be used to fine-tune or guide other LMs and/or AI systems. However, LMs have been shown to struggle with crucial aspects of preference learning: quantifying uncertainty, modeling human mental states, and asking informative questions. These challenges have been addressed in other areas of machine learning, such as Bayesian Optimal Experimental Design (BOED), which focus on designing informative queries within a well-defined feature space. But these methods, in turn, are difficult to scale and apply to real-world problems where simply identifying the relevant features can be difficult. We introduce OPEN (Optimal Preference Elicitation with Natural language) a framework that uses BOED to guide the choice of informative questions and an LM to extract features and translate abstract BOED queries into natural language questions. By combining the flexibility of LMs with the rigor of BOED, OPEN can optimize the informativity of queries while remaining adaptable to real-world domains. In user studies, we find that OPEN outperforms existing LM- and BOED-based methods for preference elicitation.
Learning with Language-Guided State Abstractions
Mar 06, 2024We describe a framework for using natural language to design state abstractions for imitation learning. Generalizable policy learning in high-dimensional observation spaces is facilitated by well-designed state representations, which can surface important features of an environment and hide irrelevant ones. These state representations are typically manually specified, or derived from other labor-intensive labeling procedures. Our method, LGA (language-guided abstraction), uses a combination of natural language supervision and background knowledge from language models (LMs) to automatically build state representations tailored to unseen tasks. In LGA, a user first provides a (possibly incomplete) description of a target task in natural language; next, a pre-trained LM translates this task description into a state abstraction function that masks out irrelevant features; finally, an imitation policy is trained using a small number of demonstrations and LGA-generated abstract states. Experiments on simulated robotic tasks show that LGA yields state abstractions similar to those designed by humans, but in a fraction of the time, and that these abstractions improve generalization and robustness in the presence of spurious correlations and ambiguous specifications. We illustrate the utility of the learned abstractions on mobile manipulation tasks with a Spot robot.
Preference-Conditioned Language-Guided Abstraction
Feb 05, 2024



Learning from demonstrations is a common way for users to teach robots, but it is prone to spurious feature correlations. Recent work constructs state abstractions, i.e. visual representations containing task-relevant features, from language as a way to perform more generalizable learning. However, these abstractions also depend on a user's preference for what matters in a task, which may be hard to describe or infeasible to exhaustively specify using language alone. How do we construct abstractions to capture these latent preferences? We observe that how humans behave reveals how they see the world. Our key insight is that changes in human behavior inform us that there are differences in preferences for how humans see the world, i.e. their state abstractions. In this work, we propose using language models (LMs) to query for those preferences directly given knowledge that a change in behavior has occurred. In our framework, we use the LM in two ways: first, given a text description of the task and knowledge of behavioral change between states, we query the LM for possible hidden preferences; second, given the most likely preference, we query the LM to construct the state abstraction. In this framework, the LM is also able to ask the human directly when uncertain about its own estimate. We demonstrate our framework's ability to construct effective preference-conditioned abstractions in simulated experiments, a user study, as well as on a real Spot robot performing mobile manipulation tasks.
Eliciting Human Preferences with Language Models
Oct 17, 2023Language models (LMs) can be directed to perform target tasks by using labeled examples or natural language prompts. But selecting examples or writing prompts for can be challenging--especially in tasks that involve unusual edge cases, demand precise articulation of nebulous preferences, or require an accurate mental model of LM behavior. We propose to use *LMs themselves* to guide the task specification process. In this paper, we introduce **Generative Active Task Elicitation (GATE)**: a learning framework in which models elicit and infer intended behavior through free-form, language-based interaction with users. We study GATE in three domains: email validation, content recommendation, and moral reasoning. In preregistered experiments, we show that LMs prompted to perform GATE (e.g., by generating open-ended questions or synthesizing informative edge cases) elicit responses that are often more informative than user-written prompts or labels. Users report that interactive task elicitation requires less effort than prompting or example labeling and surfaces novel considerations not initially anticipated by users. Our findings suggest that LM-driven elicitation can be a powerful tool for aligning models to complex human preferences and values.
Toward Interactive Dictation
Jul 08, 2023



Voice dictation is an increasingly important text input modality. Existing systems that allow both dictation and editing-by-voice restrict their command language to flat templates invoked by trigger words. In this work, we study the feasibility of allowing users to interrupt their dictation with spoken editing commands in open-ended natural language. We introduce a new task and dataset, TERTiUS, to experiment with such systems. To support this flexibility in real-time, a system must incrementally segment and classify spans of speech as either dictation or command, and interpret the spans that are commands. We experiment with using large pre-trained language models to predict the edited text, or alternatively, to predict a small text-editing program. Experiments show a natural trade-off between model accuracy and latency: a smaller model achieves 30% end-state accuracy with 1.3 seconds of latency, while a larger model achieves 55% end-state accuracy with 7 seconds of latency.