 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMICE for CATs: Model-Internal Confidence Estimation for Calibrating Agents with Tools
Apr 28, 2025



Tool-using agents that act in the world need to be both useful and safe. Well-calibrated model confidences can be used to weigh the risk versus reward of potential actions, but prior work shows that many models are poorly calibrated. Inspired by interpretability literature exploring the internals of models, we propose a novel class of model-internal confidence estimators (MICE) to better assess confidence when calling tools. MICE first decodes from each intermediate layer of the language model using logitLens and then computes similarity scores between each layer's generation and the final output. These features are fed into a learned probabilistic classifier to assess confidence in the decoded output. On the simulated trial and error (STE) tool-calling dataset using Llama3 models, we find that MICE beats or matches the baselines on smoothed expected calibration error. Using MICE confidences to determine whether to call a tool significantly improves over strong baselines on a new metric, expected tool-calling utility. Further experiments show that MICE is sample-efficient, can generalize zero-shot to unseen APIs, and results in higher tool-calling utility in scenarios with varying risk levels. Our code is open source, available at https://github.com/microsoft/mice_for_cats.
Toward Interactive Dictation
Jul 08, 2023



Voice dictation is an increasingly important text input modality. Existing systems that allow both dictation and editing-by-voice restrict their command language to flat templates invoked by trigger words. In this work, we study the feasibility of allowing users to interrupt their dictation with spoken editing commands in open-ended natural language. We introduce a new task and dataset, TERTiUS, to experiment with such systems. To support this flexibility in real-time, a system must incrementally segment and classify spans of speech as either dictation or command, and interpret the spans that are commands. We experiment with using large pre-trained language models to predict the edited text, or alternatively, to predict a small text-editing program. Experiments show a natural trade-off between model accuracy and latency: a smaller model achieves 30% end-state accuracy with 1.3 seconds of latency, while a larger model achieves 55% end-state accuracy with 7 seconds of latency.
BenchCLAMP: A Benchmark for Evaluating Language Models on Semantic Parsing
Jun 21, 2022
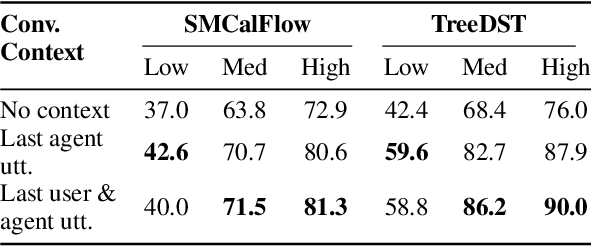
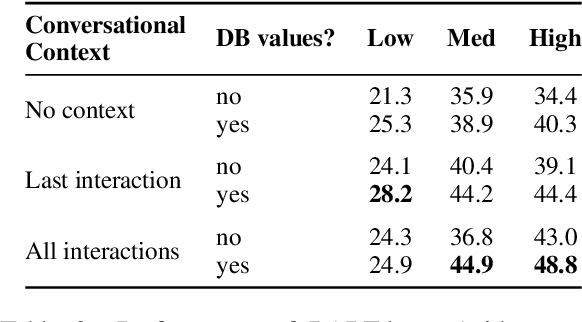

We introduce BenchCLAMP, a Benchmark to evaluate Constrained LAnguage Model Parsing, which produces semantic outputs based on the analysis of input text through constrained decoding of a prompted or fine-tuned language model. Developers of pretrained language models currently benchmark on classification, span extraction and free-text generation tasks. Semantic parsing is neglected in language model evaluation because of the complexity of handling task-specific architectures and representations. Recent work has shown that generation from a prompted or fine-tuned language model can perform well at semantic parsing when the output is constrained to be a valid semantic representation. BenchCLAMP includes context-free grammars for six semantic parsing datasets with varied output meaning representations, as well as a constrained decoding interface to generate outputs covered by these grammars. We provide low, medium, and high resource splits for each dataset, allowing accurate comparison of various language models under different data regimes. Our benchmark supports both prompt-based learning as well as fine-tuning, and provides an easy-to-use toolkit for language model developers to evaluate on semantic parsing.
When More Data Hurts: A Troubling Quirk in Developing Broad-Coverage Natural Language Understanding Systems
May 24, 2022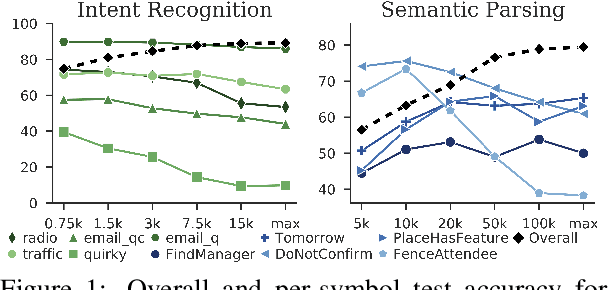


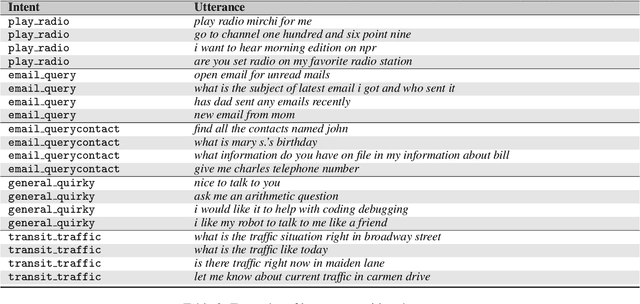
In natural language understanding (NLU) production systems, users' evolving needs necessitate the addition of new features over time, indexed by new symbols added to the meaning representation space. This requires additional training data and results in ever-growing datasets. We present the first systematic investigation into this incremental symbol learning scenario. Our analyses reveal a troubling quirk in building (broad-coverage) NLU systems: as the training dataset grows, more data is needed to learn new symbols, forming a vicious cycle. We show that this trend holds for multiple mainstream models on two common NLU tasks: intent recognition and semantic parsing. Rejecting class imbalance as the sole culprit, we reveal that the trend is closely associated with an effect we call source signal dilution, where strong lexical cues for the new symbol become diluted as the training dataset grows. Selectively dropping training examples to prevent dilution often reverses the trend, showing the over-reliance of mainstream neural NLU models on simple lexical cues and their lack of contextual understanding.
Constrained Language Models Yield Few-Shot Semantic Parsers
Apr 18, 2021

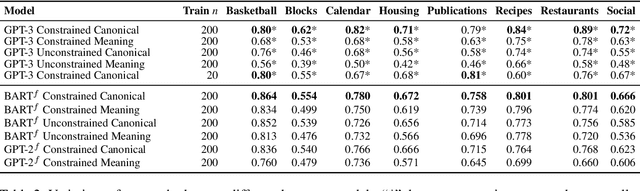

We explore the use of large pretrained language models as few-shot semantic parsers. The goal in semantic parsing is to generate a structured meaning representation given a natural language input. However, language models are trained to generate natural language. To bridge the gap, we use language models to paraphrase inputs into a controlled sublanguage resembling English that can be automatically mapped to a target meaning representation. With a small amount of data and very little code to convert into English-like representations, we provide a blueprint for rapidly bootstrapping semantic parsers and demonstrate good performance on multiple tasks.
Task-Oriented Dialogue as Dataflow Synthesis
Oct 02, 2020We describe an approach to task-oriented dialogue in which dialogue state is represented as a dataflow graph. A dialogue agent maps each user utterance to a program that extends this graph. Programs include metacomputation operators for reference and revision that reuse dataflow fragments from previous turns. Our graph-based state enables the expression and manipulation of complex user intents, and explicit metacomputation makes these intents easier for learned models to predict. We introduce a new dataset, SMCalFlow, featuring complex dialogues about events, weather, places, and people. Experiments show that dataflow graphs and metacomputation substantially improve representability and predictability in these natural dialogues. Additional experiments on the MultiWOZ dataset show that our dataflow representation enables an otherwise off-the-shelf sequence-to-sequence model to match the best existing task-specific state tracking model. The SMCalFlow dataset and code for replicating experiments are available at https://www.microsoft.com/en-us/research/project/dataflow-based-dialogue-semantic-machines.
Syntactic Scaffolds for Semantic Structures
Aug 30, 2018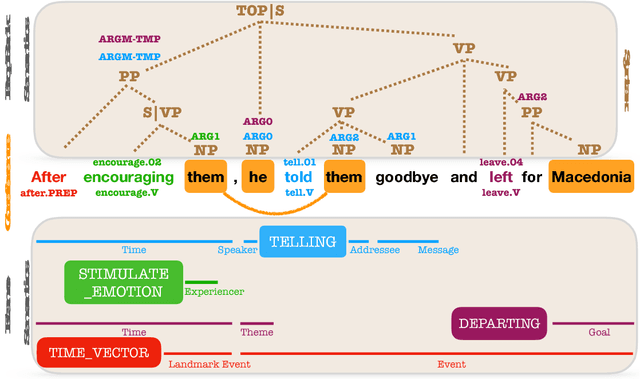
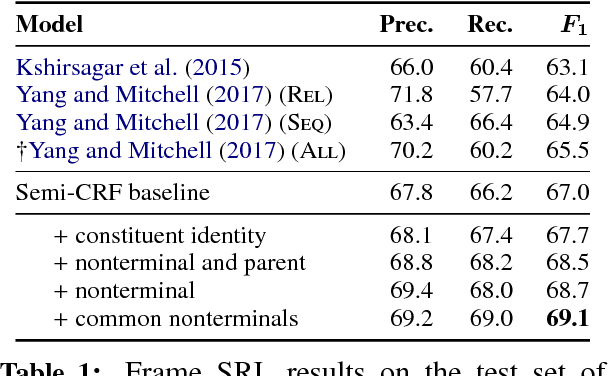
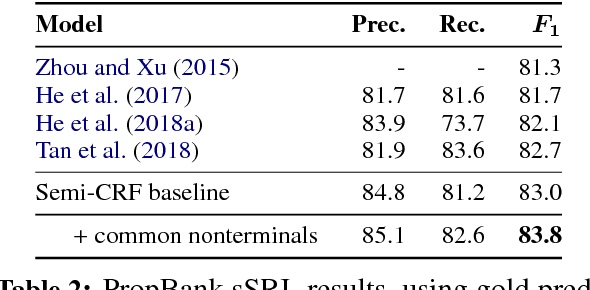
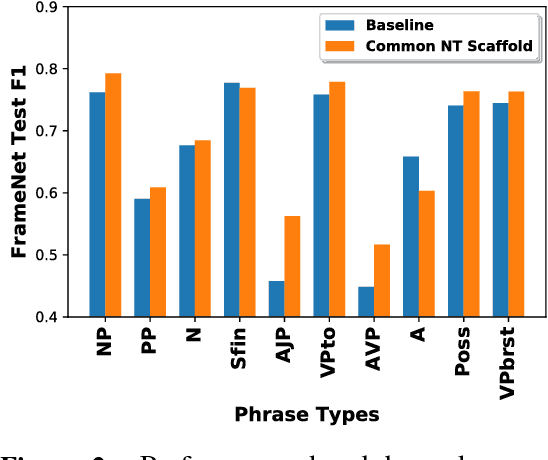
We introduce the syntactic scaffold, an approach to incorporating syntactic information into semantic tasks. Syntactic scaffolds avoid expensive syntactic processing at runtime, only making use of a treebank during training, through a multitask objective. We improve over strong baselines on PropBank semantics, frame semantics, and coreference resolution, achieving competitive performance on all three tasks.
Rational Recurrences
Aug 28, 2018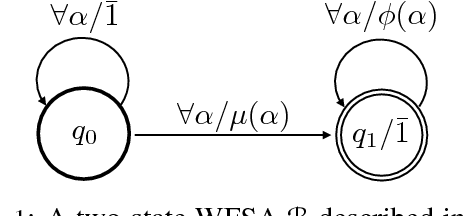

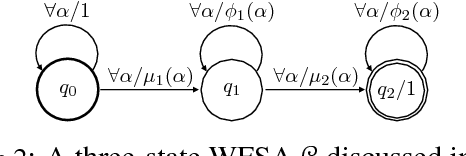

Despite the tremendous empirical success of neural models in natural language processing, many of them lack the strong intuitions that accompany classical machine learning approaches. Recently, connections have been shown between convolutional neural networks (CNNs) and weighted finite state automata (WFSAs), leading to new interpretations and insights. In this work, we show that some recurrent neural networks also share this connection to WFSAs. We characterize this connection formally, defining rational recurrences to be recurrent hidden state update functions that can be written as the Forward calculation of a finite set of WFSAs. We show that several recent neural models use rational recurrences. Our analysis provides a fresh view of these models and facilitates devising new neural architectures that draw inspiration from WFSAs. We present one such model, which performs better than two recent baselines on language modeling and text classification. Our results demonstrate that transferring intuitions from classical models like WFSAs can be an effective approach to designing and understanding neural models.
Toward Abstractive Summarization Using Semantic Representations
May 25, 2018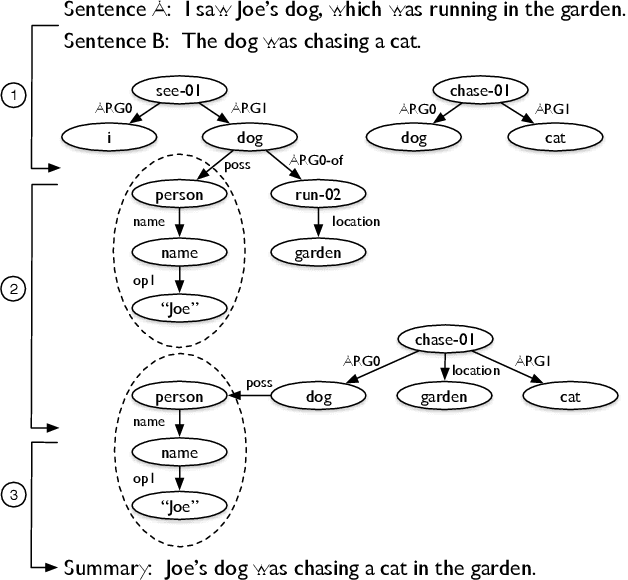
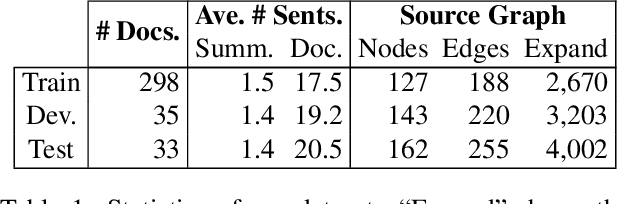
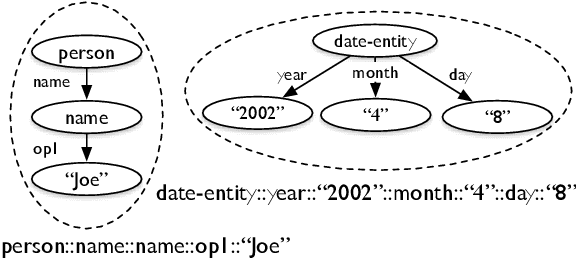
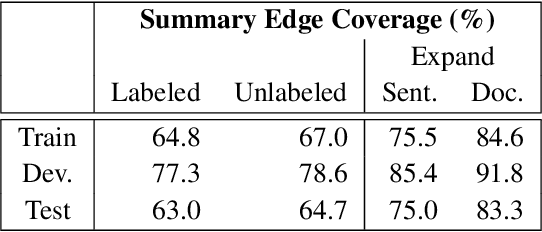
We present a novel abstractive summarization framework that draws on the recent development of a treebank for the Abstract Meaning Representation (AMR). In this framework, the source text is parsed to a set of AMR graphs, the graphs are transformed into a summary graph, and then text is generated from the summary graph. We focus on the graph-to-graph transformation that reduces the source semantic graph into a summary graph, making use of an existing AMR parser and assuming the eventual availability of an AMR-to-text generator. The framework is data-driven, trainable, and not specifically designed for a particular domain. Experiments on gold-standard AMR annotations and system parses show promising results. Code is available at: https://github.com/summarization
SoPa: Bridging CNNs, RNNs, and Weighted Finite-State Machines
May 15, 2018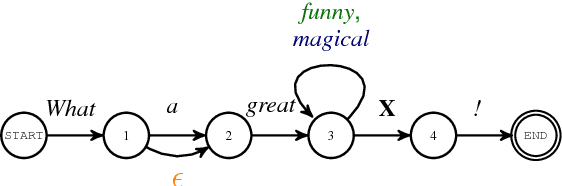

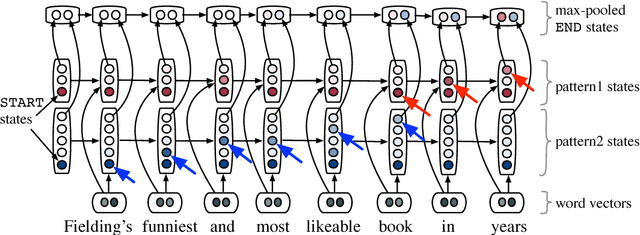
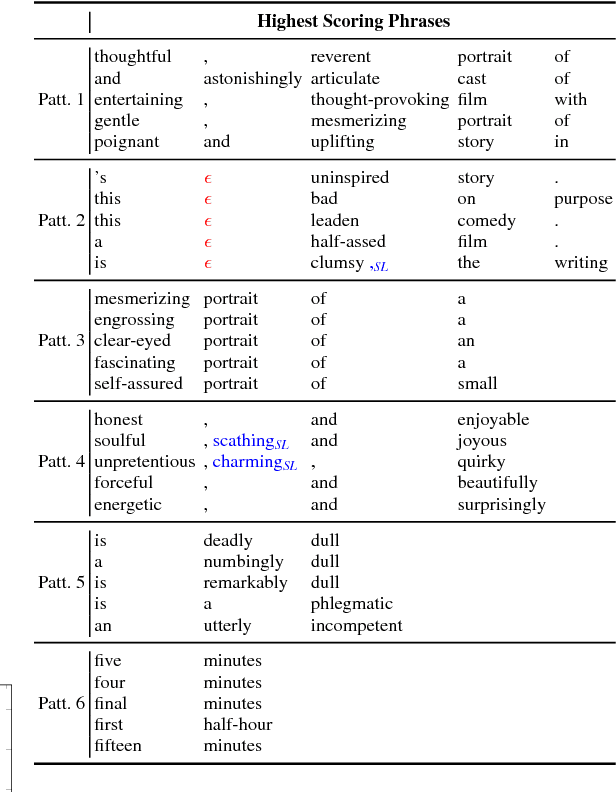
Recurrent and convolutional neural networks comprise two distinct families of models that have proven to be useful for encoding natural language utterances. In this paper we present SoPa, a new model that aims to bridge these two approaches. SoPa combines neural representation learning with weighted finite-state automata (WFSAs) to learn a soft version of traditional surface patterns. We show that SoPa is an extension of a one-layer CNN, and that such CNNs are equivalent to a restricted version of SoPa, and accordingly, to a restricted form of WFSA. Empirically, on three text classification tasks, SoPa is comparable or better than both a BiLSTM (RNN) baseline and a CNN baseline, and is particularly useful in small data settings.