 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen More Data Hurts: A Troubling Quirk in Developing Broad-Coverage Natural Language Understanding Systems
Paper and Code
May 24, 2022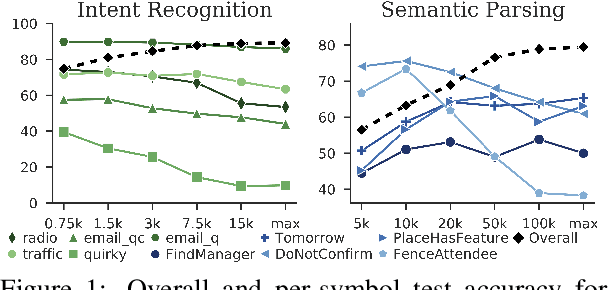


In natural language understanding (NLU) production systems, users' evolving needs necessitate the addition of new features over time, indexed by new symbols added to the meaning representation space. This requires additional training data and results in ever-growing datasets. We present the first systematic investigation into this incremental symbol learning scenario. Our analyses reveal a troubling quirk in building (broad-coverage) NLU systems: as the training dataset grows, more data is needed to learn new symbols, forming a vicious cycle. We show that this trend holds for multiple mainstream models on two common NLU tasks: intent recognition and semantic parsing. Rejecting class imbalance as the sole culprit, we reveal that the trend is closely associated with an effect we call source signal dilution, where strong lexical cues for the new symbol become diluted as the training dataset grows. Selectively dropping training examples to prevent dilution often reverses the trend, showing the over-reliance of mainstream neural NLU models on simple lexical cues and their lack of contextual understanding.