 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen More Data Hurts: A Troubling Quirk in Developing Broad-Coverage Natural Language Understanding Systems
May 24, 2022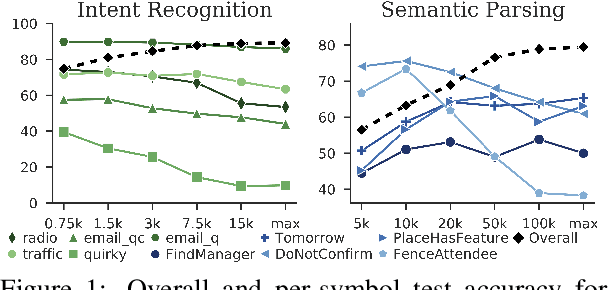


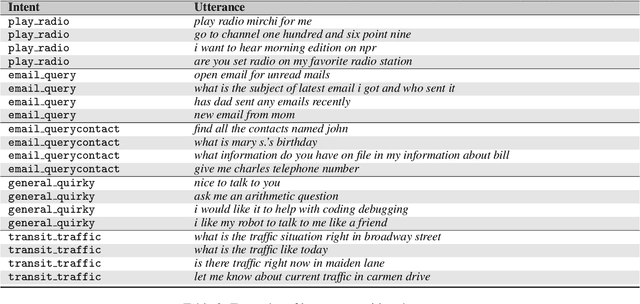
In natural language understanding (NLU) production systems, users' evolving needs necessitate the addition of new features over time, indexed by new symbols added to the meaning representation space. This requires additional training data and results in ever-growing datasets. We present the first systematic investigation into this incremental symbol learning scenario. Our analyses reveal a troubling quirk in building (broad-coverage) NLU systems: as the training dataset grows, more data is needed to learn new symbols, forming a vicious cycle. We show that this trend holds for multiple mainstream models on two common NLU tasks: intent recognition and semantic parsing. Rejecting class imbalance as the sole culprit, we reveal that the trend is closely associated with an effect we call source signal dilution, where strong lexical cues for the new symbol become diluted as the training dataset grows. Selectively dropping training examples to prevent dilution often reverses the trend, showing the over-reliance of mainstream neural NLU models on simple lexical cues and their lack of contextual understanding.
Coarse-to-Fine Curriculum Learning
Jun 08, 2021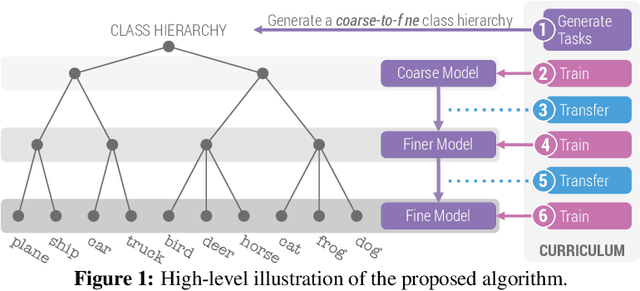

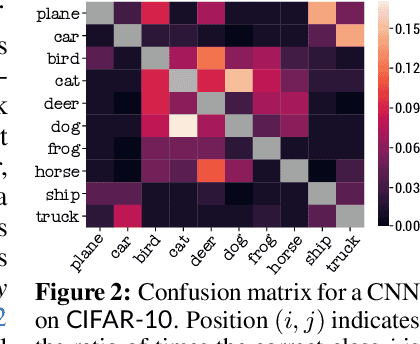
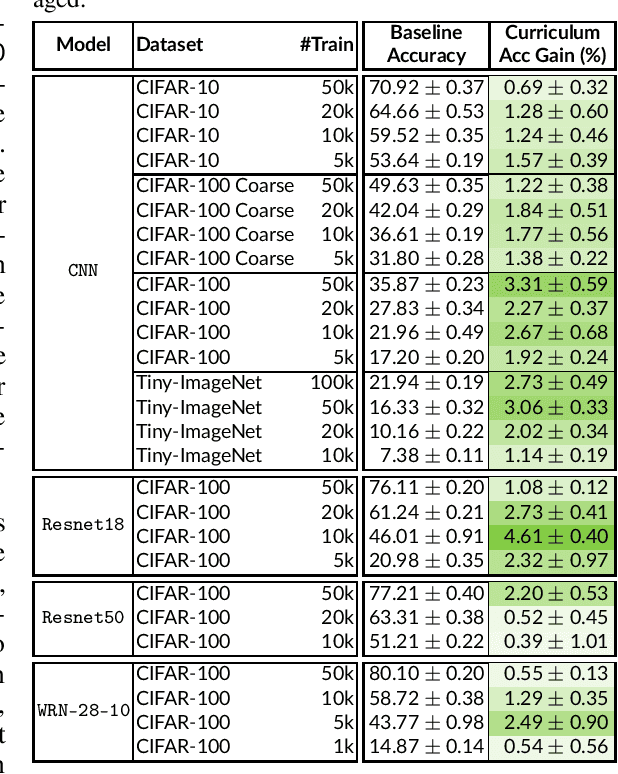
When faced with learning challenging new tasks, humans often follow sequences of steps that allow them to incrementally build up the necessary skills for performing these new tasks. However, in machine learning, models are most often trained to solve the target tasks directly.Inspired by human learning, we propose a novel curriculum learning approach which decomposes challenging tasks into sequences of easier intermediate goals that are used to pre-train a model before tackling the target task. We focus on classification tasks, and design the intermediate tasks using an automatically constructed label hierarchy. We train the model at each level of the hierarchy, from coarse labels to fine labels, transferring acquired knowledge across these levels. For instance, the model will first learn to distinguish animals from objects, and then use this acquired knowledge when learning to classify among more fine-grained classes such as cat, dog, car, and truck. Most existing curriculum learning algorithms for supervised learning consist of scheduling the order in which the training examples are presented to the model. In contrast, our approach focuses on the output space of the model. We evaluate our method on several established datasets and show significant performance gains especially on classification problems with many labels. We also evaluate on a new synthetic dataset which allows us to study multiple aspects of our method.
Constrained Language Models Yield Few-Shot Semantic Parsers
Apr 18, 2021

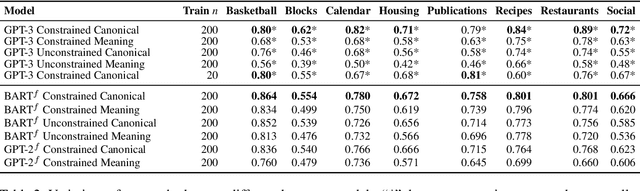

We explore the use of large pretrained language models as few-shot semantic parsers. The goal in semantic parsing is to generate a structured meaning representation given a natural language input. However, language models are trained to generate natural language. To bridge the gap, we use language models to paraphrase inputs into a controlled sublanguage resembling English that can be automatically mapped to a target meaning representation. With a small amount of data and very little code to convert into English-like representations, we provide a blueprint for rapidly bootstrapping semantic parsers and demonstrate good performance on multiple tasks.
Re-TACRED: Addressing Shortcomings of the TACRED Dataset
Apr 16, 2021
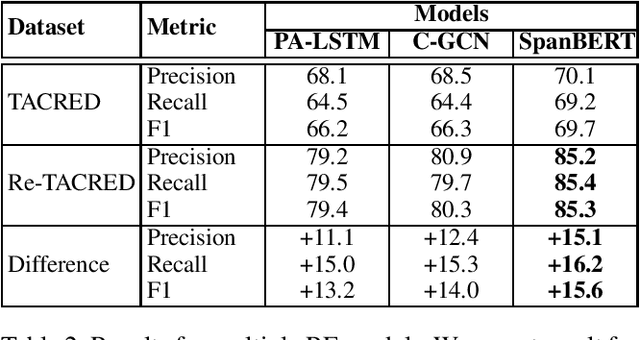
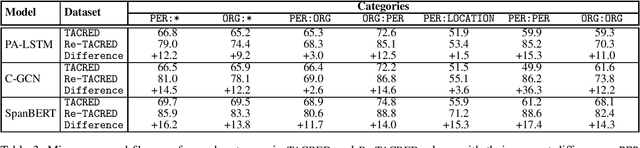
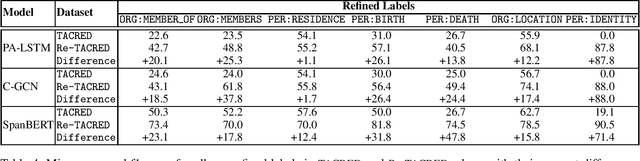
TACRED is one of the largest and most widely used sentence-level relation extraction datasets. Proposed models that are evaluated using this dataset consistently set new state-of-the-art performance. However, they still exhibit large error rates despite leveraging external knowledge and unsupervised pretraining on large text corpora. A recent study suggested that this may be due to poor dataset quality. The study observed that over 50% of the most challenging sentences from the development and test sets are incorrectly labeled and account for an average drop of 8% f1-score in model performance. However, this study was limited to a small biased sample of 5k (out of a total of 106k) sentences, substantially restricting the generalizability and broader implications of its findings. In this paper, we address these shortcomings by: (i) performing a comprehensive study over the whole TACRED dataset, (ii) proposing an improved crowdsourcing strategy and deploying it to re-annotate the whole dataset, and (iii) performing a thorough analysis to understand how correcting the TACRED annotations affects previously published results. After verification, we observed that 23.9% of TACRED labels are incorrect. Moreover, evaluating several models on our revised dataset yields an average f1-score improvement of 14.3% and helps uncover significant relationships between the different models (rather than simply offsetting or scaling their scores by a constant factor). Finally, aside from our analysis we also release Re-TACRED, a new completely re-annotated version of the TACRED dataset that can be used to perform reliable evaluation of relation extraction models.
HyperDynamics: Meta-Learning Object and Agent Dynamics with Hypernetworks
Mar 17, 2021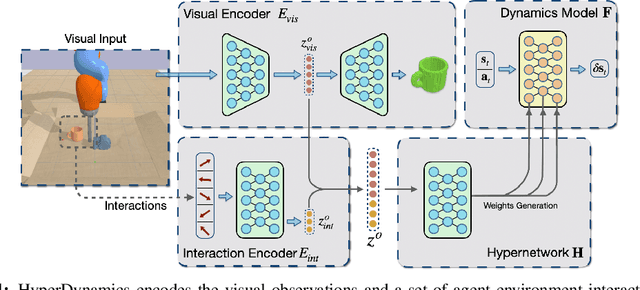
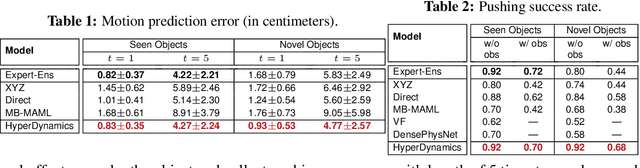

We propose HyperDynamics, a dynamics meta-learning framework that conditions on an agent's interactions with the environment and optionally its visual observations, and generates the parameters of neural dynamics models based on inferred properties of the dynamical system. Physical and visual properties of the environment that are not part of the low-dimensional state yet affect its temporal dynamics are inferred from the interaction history and visual observations, and are implicitly captured in the generated parameters. We test HyperDynamics on a set of object pushing and locomotion tasks. It outperforms existing dynamics models in the literature that adapt to environment variations by learning dynamics over high dimensional visual observations, capturing the interactions of the agent in recurrent state representations, or using gradient-based meta-optimization. We also show our method matches the performance of an ensemble of separately trained experts, while also being able to generalize well to unseen environment variations at test time. We attribute its good performance to the multiplicative interactions between the inferred system properties -- captured in the generated parameters -- and the low-dimensional state representation of the dynamical system.
Improving Relation Extraction by Leveraging Knowledge Graph Link Prediction
Dec 09, 2020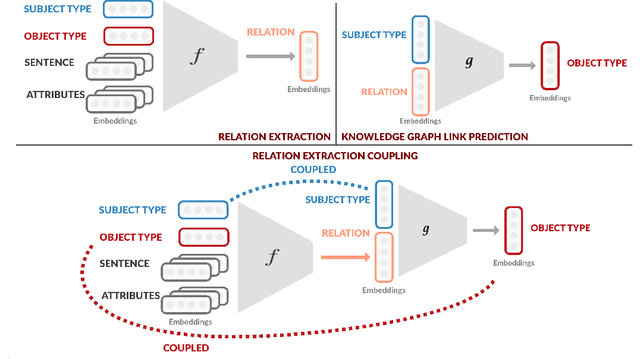



Relation extraction (RE) aims to predict a relation between a subject and an object in a sentence, while knowledge graph link prediction (KGLP) aims to predict a set of objects, O, given a subject and a relation from a knowledge graph. These two problems are closely related as their respective objectives are intertwined: given a sentence containing a subject and an object o, a RE model predicts a relation that can then be used by a KGLP model together with the subject, to predict a set of objects O. Thus, we expect object o to be in set O. In this paper, we leverage this insight by proposing a multi-task learning approach that improves the performance of RE models by jointly training on RE and KGLP tasks. We illustrate the generality of our approach by applying it on several existing RE models and empirically demonstrate how it helps them achieve consistent performance gains.
Learning from Imperfect Annotations
Apr 07, 2020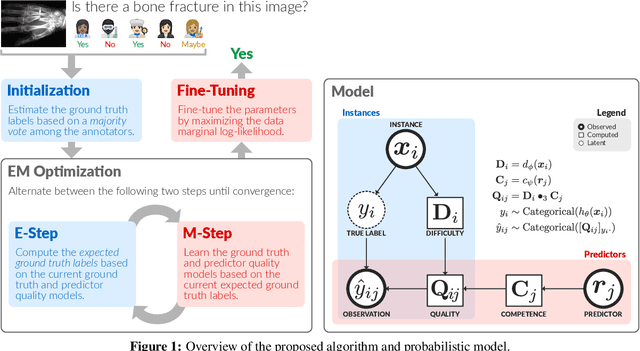
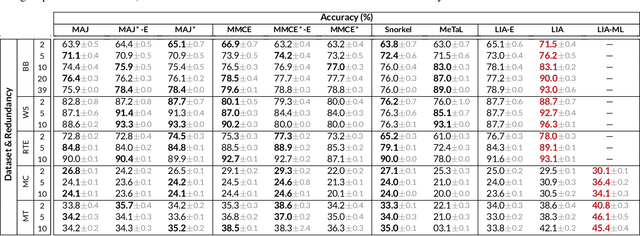
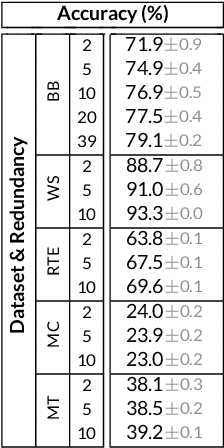
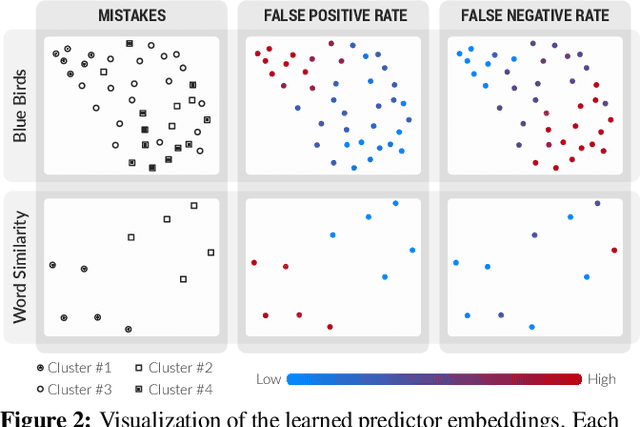
Many machine learning systems today are trained on large amounts of human-annotated data. Data annotation tasks that require a high level of competency make data acquisition expensive, while the resulting labels are often subjective, inconsistent, and may contain a variety of human biases. To improve the data quality, practitioners often need to collect multiple annotations per example and aggregate them before training models. Such a multi-stage approach results in redundant annotations and may often produce imperfect "ground truth" that may limit the potential of training accurate machine learning models. We propose a new end-to-end framework that enables us to: (i) merge the aggregation step with model training, thus allowing deep learning systems to learn to predict ground truth estimates directly from the available data, and (ii) model difficulties of examples and learn representations of the annotators that allow us to estimate and take into account their competencies. Our approach is general and has many applications, including training more accurate models on crowdsourced data, ensemble learning, as well as classifier accuracy estimation from unlabeled data. We conduct an extensive experimental evaluation of our method on 5 crowdsourcing datasets of varied difficulty and show accuracy gains of up to 25% over the current state-of-the-art approaches for aggregating annotations, as well as significant reductions in the required annotation redundancy.
Jelly Bean World: A Testbed for Never-Ending Learning
Feb 15, 2020
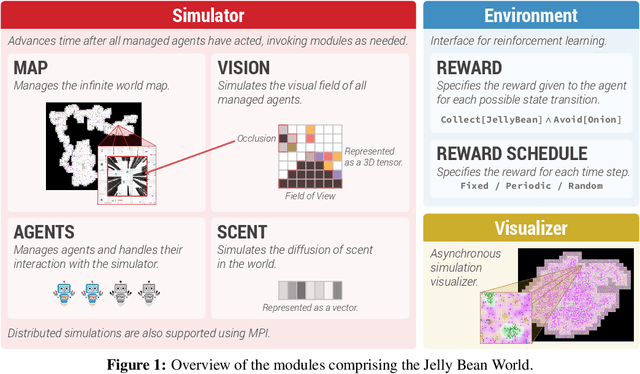


Machine learning has shown growing success in recent years. However, current machine learning systems are highly specialized, trained for particular problems or domains, and typically on a single narrow dataset. Human learning, on the other hand, is highly general and adaptable. Never-ending learning is a machine learning paradigm that aims to bridge this gap, with the goal of encouraging researchers to design machine learning systems that can learn to perform a wider variety of inter-related tasks in more complex environments. To date, there is no environment or testbed to facilitate the development and evaluation of never-ending learning systems. To this end, we propose the Jelly Bean World testbed. The Jelly Bean World allows experimentation over two-dimensional grid worlds which are filled with items and in which agents can navigate. This testbed provides environments that are sufficiently complex and where more generally intelligent algorithms ought to perform better than current state-of-the-art reinforcement learning approaches. It does so by producing non-stationary environments and facilitating experimentation with multi-task, multi-agent, multi-modal, and curriculum learning settings. We hope that this new freely-available software will prompt new research and interest in the development and evaluation of never-ending learning systems and more broadly, general intelligence systems.
* Published as a conference paper at ICLR 2020
Competence-based Curriculum Learning for Neural Machine Translation
Mar 26, 2019
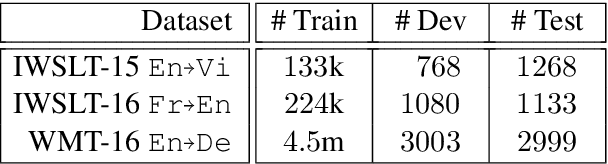


Current state-of-the-art NMT systems use large neural networks that are not only slow to train, but also often require many heuristics and optimization tricks, such as specialized learning rate schedules and large batch sizes. This is undesirable as it requires extensive hyperparameter tuning. In this paper, we propose a curriculum learning framework for NMT that reduces training time, reduces the need for specialized heuristics or large batch sizes, and results in overall better performance. Our framework consists of a principled way of deciding which training samples are shown to the model at different times during training, based on the estimated difficulty of a sample and the current competence of the model. Filtering training samples in this manner prevents the model from getting stuck in bad local optima, making it converge faster and reach a better solution than the common approach of uniformly sampling training examples. Furthermore, the proposed method can be easily applied to existing NMT models by simply modifying their input data pipelines. We show that our framework can help improve the training time and the performance of both recurrent neural network models and Transformers, achieving up to a 70% decrease in training time, while at the same time obtaining accuracy improvements of up to 2.2 BLEU.
Contextual Parameter Generation for Universal Neural Machine Translation
Aug 26, 2018
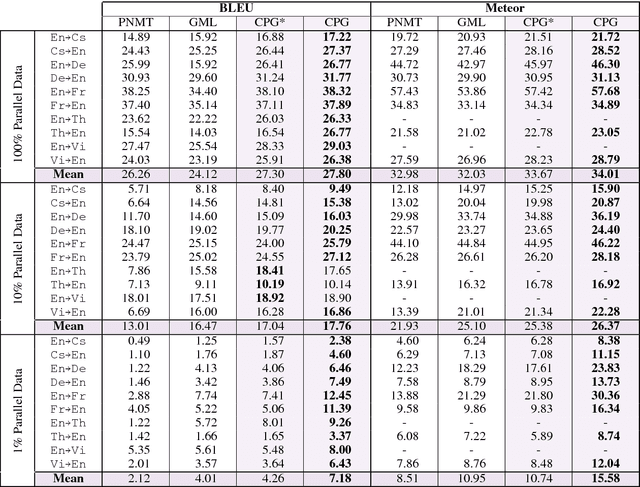
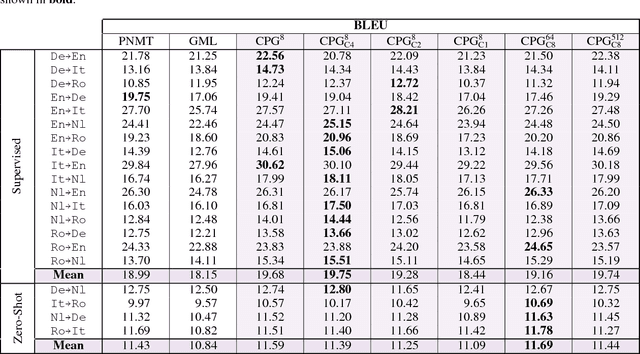

We propose a simple modification to existing neural machine translation (NMT) models that enables using a single universal model to translate between multiple languages while allowing for language specific parameterization, and that can also be used for domain adaptation. Our approach requires no changes to the model architecture of a standard NMT system, but instead introduces a new component, the contextual parameter generator (CPG), that generates the parameters of the system (e.g., weights in a neural network). This parameter generator accepts source and target language embeddings as input, and generates the parameters for the encoder and the decoder, respectively. The rest of the model remains unchanged and is shared across all languages. We show how this simple modification enables the system to use monolingual data for training and also perform zero-shot translation. We further show it is able to surpass state-of-the-art performance for both the IWSLT-15 and IWSLT-17 datasets and that the learned language embeddings are able to uncover interesting relationships between languages.