 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstructExcel: A Benchmark for Natural Language Instruction in Excel
Oct 23, 2023With the evolution of Large Language Models (LLMs) we can solve increasingly more complex NLP tasks across various domains, including spreadsheets. This work investigates whether LLMs can generate code (Excel OfficeScripts, a TypeScript API for executing many tasks in Excel) that solves Excel specific tasks provided via natural language user instructions. To do so we introduce a new large-scale benchmark, InstructExcel, created by leveraging the 'Automate' feature in Excel to automatically generate OfficeScripts from users' actions. Our benchmark includes over 10k samples covering 170+ Excel operations across 2,000 publicly available Excel spreadsheets. Experiments across various zero-shot and few-shot settings show that InstructExcel is a hard benchmark for state of the art models like GPT-4. We observe that (1) using GPT-4 over GPT-3.5, (2) providing more in-context examples, and (3) dynamic prompting can help improve performance on this benchmark.
ZEROTOP: Zero-Shot Task-Oriented Semantic Parsing using Large Language Models
Dec 21, 2022



We explore the use of large language models (LLMs) for zero-shot semantic parsing. Semantic parsing involves mapping natural language utterances to task-specific meaning representations. Language models are generally trained on the publicly available text and code and cannot be expected to directly generalize to domain-specific parsing tasks in a zero-shot setting. In this work, we propose ZEROTOP, a zero-shot task-oriented parsing method that decomposes a semantic parsing problem into a set of abstractive and extractive question-answering (QA) problems, enabling us to leverage the ability of LLMs to zero-shot answer reading comprehension questions. For each utterance, we prompt the LLM with questions corresponding to its top-level intent and a set of slots and use the LLM generations to construct the target meaning representation. We observe that current LLMs fail to detect unanswerable questions; and as a result, cannot handle questions corresponding to missing slots. To address this problem, we fine-tune a language model on public QA datasets using synthetic negative samples. Experimental results show that our QA-based decomposition paired with the fine-tuned LLM can correctly parse ~16% of utterances in the MTOP dataset without requiring any annotated data.
BenchCLAMP: A Benchmark for Evaluating Language Models on Semantic Parsing
Jun 21, 2022

We introduce BenchCLAMP, a Benchmark to evaluate Constrained LAnguage Model Parsing, which produces semantic outputs based on the analysis of input text through constrained decoding of a prompted or fine-tuned language model. Developers of pretrained language models currently benchmark on classification, span extraction and free-text generation tasks. Semantic parsing is neglected in language model evaluation because of the complexity of handling task-specific architectures and representations. Recent work has shown that generation from a prompted or fine-tuned language model can perform well at semantic parsing when the output is constrained to be a valid semantic representation. BenchCLAMP includes context-free grammars for six semantic parsing datasets with varied output meaning representations, as well as a constrained decoding interface to generate outputs covered by these grammars. We provide low, medium, and high resource splits for each dataset, allowing accurate comparison of various language models under different data regimes. Our benchmark supports both prompt-based learning as well as fine-tuning, and provides an easy-to-use toolkit for language model developers to evaluate on semantic parsing.
Addressing Resource and Privacy Constraints in Semantic Parsing Through Data Augmentation
May 18, 2022
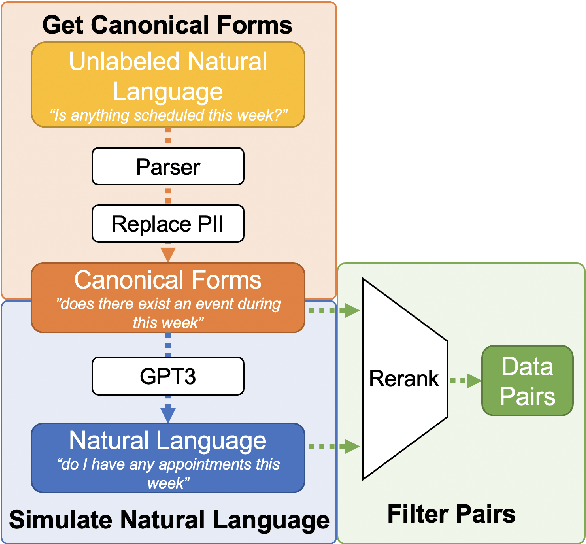


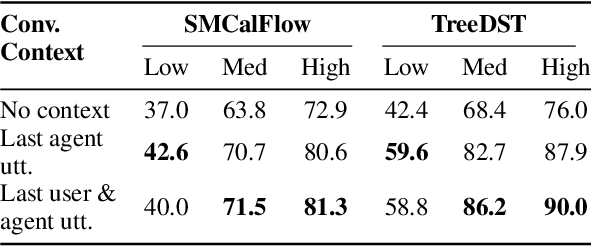
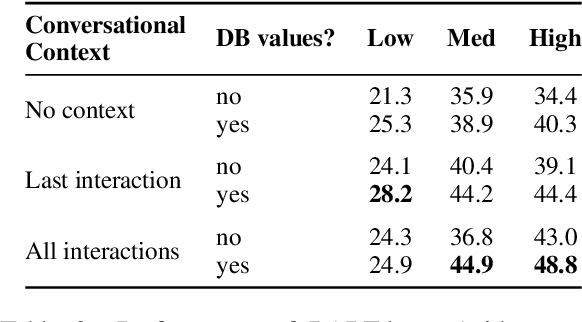
We introduce a novel setup for low-resource task-oriented semantic parsing which incorporates several constraints that may arise in real-world scenarios: (1) lack of similar datasets/models from a related domain, (2) inability to sample useful logical forms directly from a grammar, and (3) privacy requirements for unlabeled natural utterances. Our goal is to improve a low-resource semantic parser using utterances collected through user interactions. In this highly challenging but realistic setting, we investigate data augmentation approaches involving generating a set of structured canonical utterances corresponding to logical forms, before simulating corresponding natural language and filtering the resulting pairs. We find that such approaches are effective despite our restrictive setup: in a low-resource setting on the complex SMCalFlow calendaring dataset (Andreas et al., 2020), we observe 33% relative improvement over a non-data-augmented baseline in top-1 match.
Constrained Language Models Yield Few-Shot Semantic Parsers
Apr 18, 2021

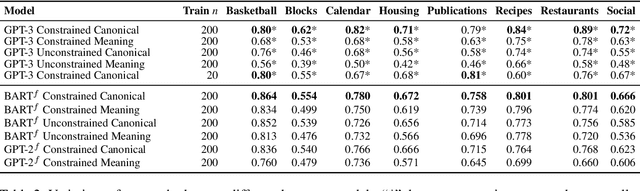

We explore the use of large pretrained language models as few-shot semantic parsers. The goal in semantic parsing is to generate a structured meaning representation given a natural language input. However, language models are trained to generate natural language. To bridge the gap, we use language models to paraphrase inputs into a controlled sublanguage resembling English that can be automatically mapped to a target meaning representation. With a small amount of data and very little code to convert into English-like representations, we provide a blueprint for rapidly bootstrapping semantic parsers and demonstrate good performance on multiple tasks.
Task-Oriented Dialogue as Dataflow Synthesis
Oct 02, 2020We describe an approach to task-oriented dialogue in which dialogue state is represented as a dataflow graph. A dialogue agent maps each user utterance to a program that extends this graph. Programs include metacomputation operators for reference and revision that reuse dataflow fragments from previous turns. Our graph-based state enables the expression and manipulation of complex user intents, and explicit metacomputation makes these intents easier for learned models to predict. We introduce a new dataset, SMCalFlow, featuring complex dialogues about events, weather, places, and people. Experiments show that dataflow graphs and metacomputation substantially improve representability and predictability in these natural dialogues. Additional experiments on the MultiWOZ dataset show that our dataflow representation enables an otherwise off-the-shelf sequence-to-sequence model to match the best existing task-specific state tracking model. The SMCalFlow dataset and code for replicating experiments are available at https://www.microsoft.com/en-us/research/project/dataflow-based-dialogue-semantic-machines.
Mapping to Declarative Knowledge for Word Problem Solving
Dec 26, 2017Math word problems form a natural abstraction to a range of quantitative reasoning problems, such as understanding financial news, sports results, and casualties of war. Solving such problems requires the understanding of several mathematical concepts such as dimensional analysis, subset relationships, etc. In this paper, we develop declarative rules which govern the translation of natural language description of these concepts to math expressions. We then present a framework for incorporating such declarative knowledge into word problem solving. Our method learns to map arithmetic word problem text to math expressions, by learning to select the relevant declarative knowledge for each operation of the solution expression. This provides a way to handle multiple concepts in the same problem while, at the same time, support interpretability of the answer expression. Our method models the mapping to declarative knowledge as a latent variable, thus removing the need for expensive annotations. Experimental evaluation suggests that our domain knowledge based solver outperforms all other systems, and that it generalizes better in the realistic case where the training data it is exposed to is biased in a different way than the test data.
Unit Dependency Graph and its Application to Arithmetic Word Problem Solving
Dec 03, 2016



Math word problems provide a natural abstraction to a range of natural language understanding problems that involve reasoning about quantities, such as interpreting election results, news about casualties, and the financial section of a newspaper. Units associated with the quantities often provide information that is essential to support this reasoning. This paper proposes a principled way to capture and reason about units and shows how it can benefit an arithmetic word problem solver. This paper presents the concept of Unit Dependency Graphs (UDGs), which provides a compact representation of the dependencies between units of numbers mentioned in a given problem. Inducing the UDG alleviates the brittleness of the unit extraction system and allows for a natural way to leverage domain knowledge about unit compatibility, for word problem solving. We introduce a decomposed model for inducing UDGs with minimal additional annotations, and use it to augment the expressions used in the arithmetic word problem solver of (Roy and Roth 2015) via a constrained inference framework. We show that introduction of UDGs reduces the error of the solver by over 10 %, surpassing all existing systems for solving arithmetic word problems. In addition, it also makes the system more robust to adaptation to new vocabulary and equation forms .
Equation Parsing: Mapping Sentences to Grounded Equations
Sep 28, 2016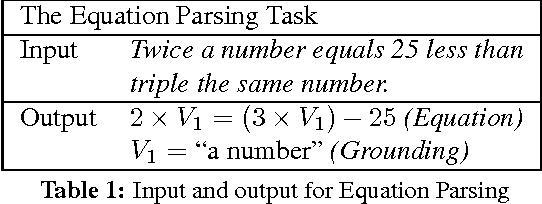
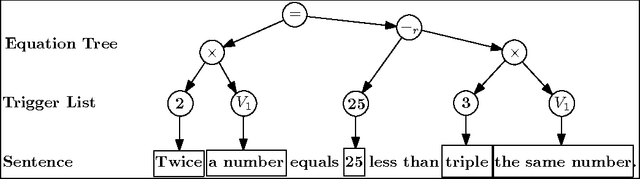
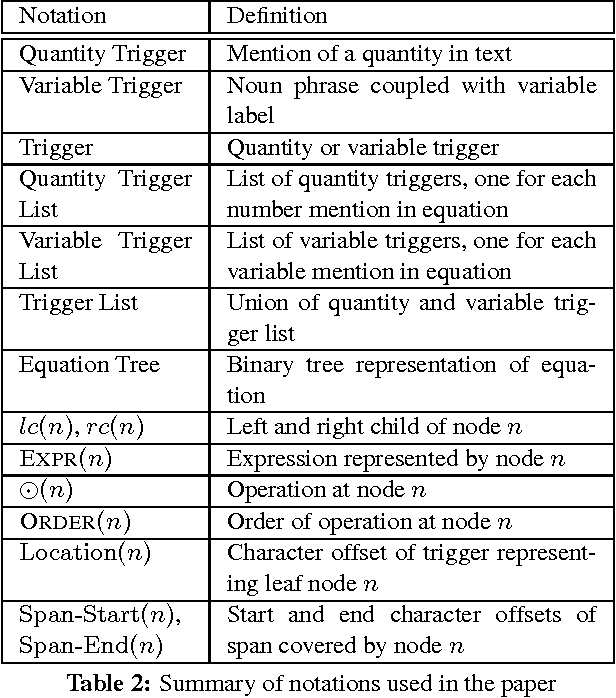
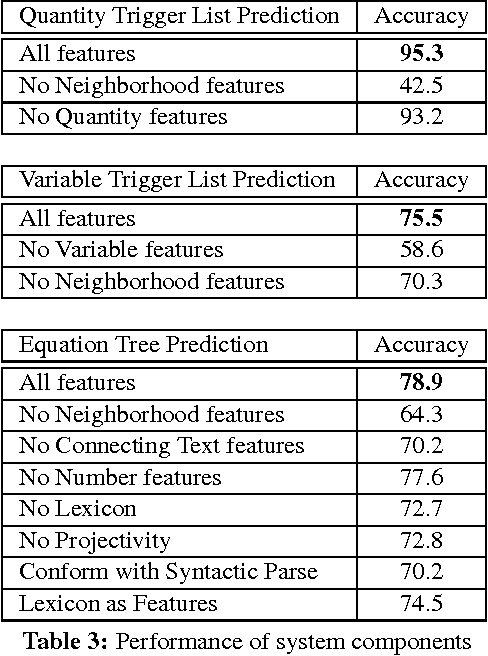
Identifying mathematical relations expressed in text is essential to understanding a broad range of natural language text from election reports, to financial news, to sport commentaries to mathematical word problems. This paper focuses on identifying and understanding mathematical relations described within a single sentence. We introduce the problem of Equation Parsing -- given a sentence, identify noun phrases which represent variables, and generate the mathematical equation expressing the relation described in the sentence. We introduce the notion of projective equation parsing and provide an efficient algorithm to parse text to projective equations. Our system makes use of a high precision lexicon of mathematical expressions and a pipeline of structured predictors, and generates correct equations in $70\%$ of the cases. In $60\%$ of the time, it also identifies the correct noun phrase $\rightarrow$ variables mapping, significantly outperforming baselines. We also release a new annotated dataset for task evaluation.
Solving General Arithmetic Word Problems
Aug 20, 2016


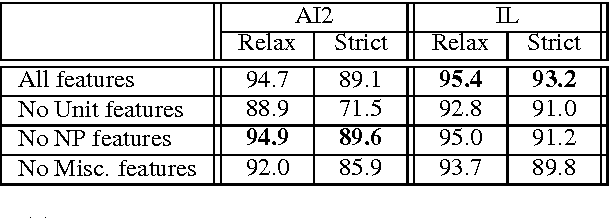
This paper presents a novel approach to automatically solving arithmetic word problems. This is the first algorithmic approach that can handle arithmetic problems with multiple steps and operations, without depending on additional annotations or predefined templates. We develop a theory for expression trees that can be used to represent and evaluate the target arithmetic expressions; we use it to uniquely decompose the target arithmetic problem to multiple classification problems; we then compose an expression tree, combining these with world knowledge through a constrained inference framework. Our classifiers gain from the use of {\em quantity schemas} that supports better extraction of features. Experimental results show that our method outperforms existing systems, achieving state of the art performance on benchmark datasets of arithmetic word problems.