 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair and Welfare-Efficient Constrained Multi-matchings under Uncertainty
Nov 04, 2024



We study fair allocation of constrained resources, where a market designer optimizes overall welfare while maintaining group fairness. In many large-scale settings, utilities are not known in advance, but are instead observed after realizing the allocation. We therefore estimate agent utilities using machine learning. Optimizing over estimates requires trading-off between mean utilities and their predictive variances. We discuss these trade-offs under two paradigms for preference modeling -- in the stochastic optimization regime, the market designer has access to a probability distribution over utilities, and in the robust optimization regime they have access to an uncertainty set containing the true utilities with high probability. We discuss utilitarian and egalitarian welfare objectives, and we explore how to optimize for them under stochastic and robust paradigms. We demonstrate the efficacy of our approaches on three publicly available conference reviewer assignment datasets. The approaches presented enable scalable constrained resource allocation under uncertainty for many combinations of objectives and preference models.
InstructExcel: A Benchmark for Natural Language Instruction in Excel
Oct 23, 2023With the evolution of Large Language Models (LLMs) we can solve increasingly more complex NLP tasks across various domains, including spreadsheets. This work investigates whether LLMs can generate code (Excel OfficeScripts, a TypeScript API for executing many tasks in Excel) that solves Excel specific tasks provided via natural language user instructions. To do so we introduce a new large-scale benchmark, InstructExcel, created by leveraging the 'Automate' feature in Excel to automatically generate OfficeScripts from users' actions. Our benchmark includes over 10k samples covering 170+ Excel operations across 2,000 publicly available Excel spreadsheets. Experiments across various zero-shot and few-shot settings show that InstructExcel is a hard benchmark for state of the art models like GPT-4. We observe that (1) using GPT-4 over GPT-3.5, (2) providing more in-context examples, and (3) dynamic prompting can help improve performance on this benchmark.
Graphical House Allocation
Jan 03, 2023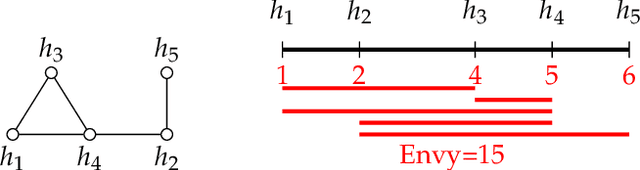


The classical house allocation problem involves assigning $n$ houses (or items) to $n$ agents according to their preferences. A key criterion in such problems is satisfying some fairness constraints such as envy-freeness. We consider a generalization of this problem wherein the agents are placed along the vertices of a graph (corresponding to a social network), and each agent can only experience envy towards its neighbors. Our goal is to minimize the aggregate envy among the agents as a natural fairness objective, i.e., the sum of all pairwise envy values over all edges in a social graph. When agents have identical and evenly-spaced valuations, our problem reduces to the well-studied problem of linear arrangements. For identical valuations with possibly uneven spacing, we show a number of deep and surprising ways in which our setting is a departure from this classical problem. More broadly, we contribute several structural and computational results for various classes of graphs, including NP-hardness results for disjoint unions of paths, cycles, stars, or cliques, and fixed-parameter tractable (and, in some cases, polynomial-time) algorithms for paths, cycles, stars, cliques, and their disjoint unions. Additionally, a conceptual contribution of our work is the formulation of a structural property for disconnected graphs that we call separability which results in efficient parameterized algorithms for finding optimal allocations.
Towards Realistic Single-Task Continuous Learning Research for NER
Oct 27, 2021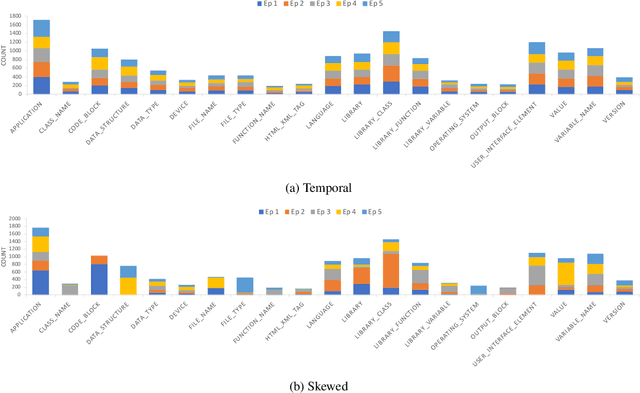
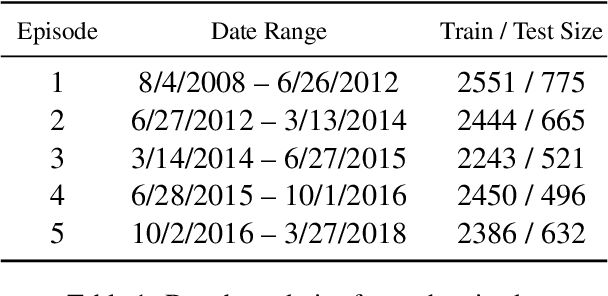
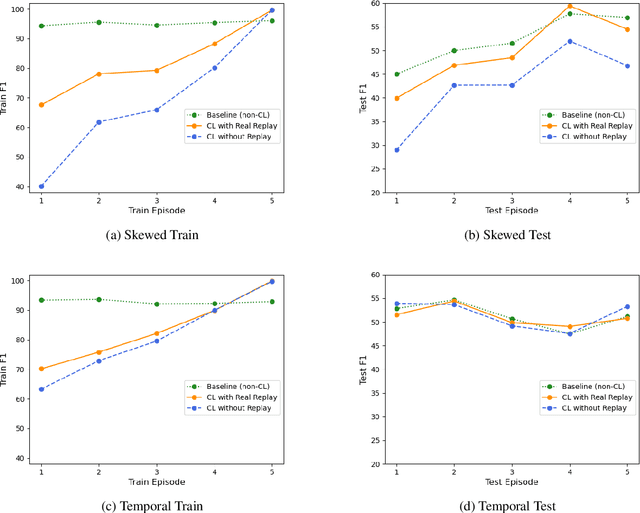
There is an increasing interest in continuous learning (CL), as data privacy is becoming a priority for real-world machine learning applications. Meanwhile, there is still a lack of academic NLP benchmarks that are applicable for realistic CL settings, which is a major challenge for the advancement of the field. In this paper we discuss some of the unrealistic data characteristics of public datasets, study the challenges of realistic single-task continuous learning as well as the effectiveness of data rehearsal as a way to mitigate accuracy loss. We construct a CL NER dataset from an existing publicly available dataset and release it along with the code to the research community.