 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Candidate Generation for Entity Linking on Short Social Media Texts
Oct 14, 2022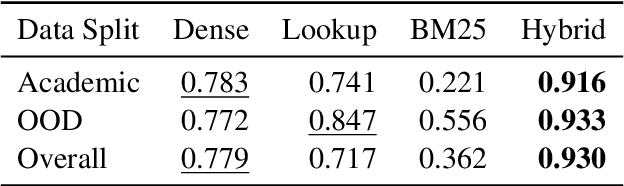
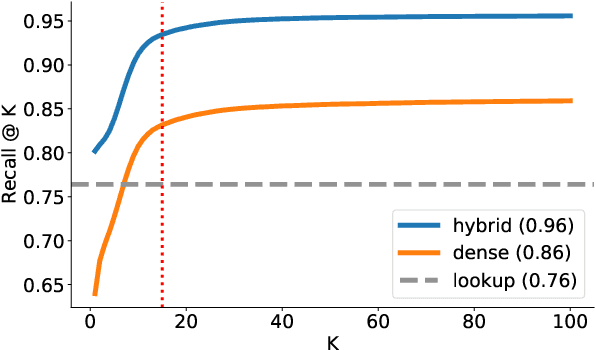
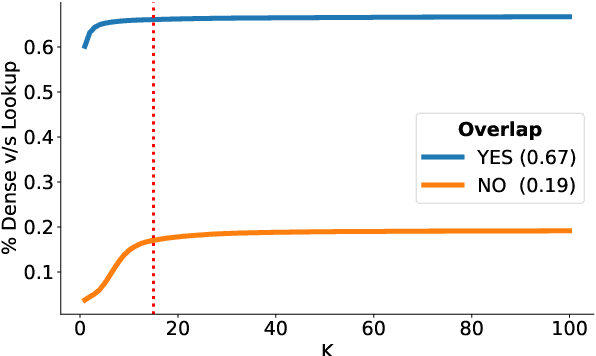
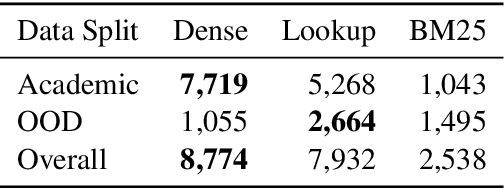
Entity Linking (EL) is the gateway into Knowledge Bases. Recent advances in EL utilize dense retrieval approaches for Candidate Generation, which addresses some of the shortcomings of the Lookup based approach of matching NER mentions against pre-computed dictionaries. In this work, we show that in the domain of Tweets, such methods suffer as users often include informal spelling, limited context, and lack of specificity, among other issues. We investigate these challenges on a large and recent Tweets benchmark for EL, empirically evaluate lookup and dense retrieval approaches, and demonstrate a hybrid solution using long contextual representation from Wikipedia is necessary to achieve considerable gains over previous work, achieving 0.93 recall.
Towards Realistic Single-Task Continuous Learning Research for NER
Oct 27, 2021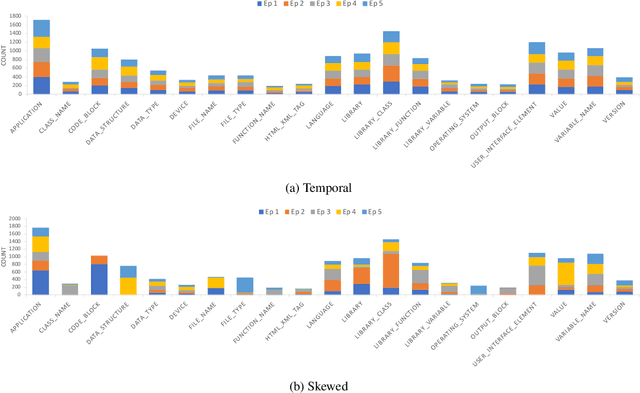
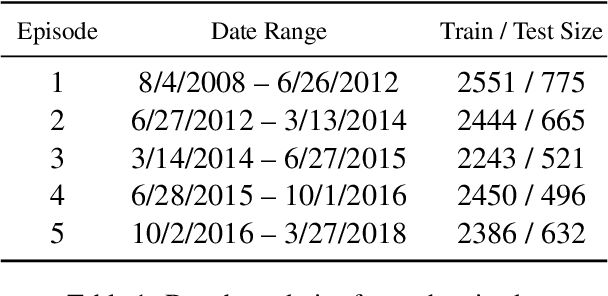
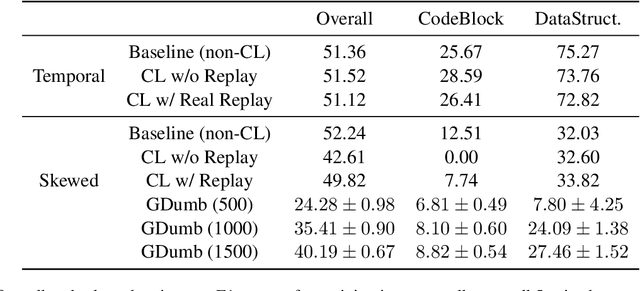
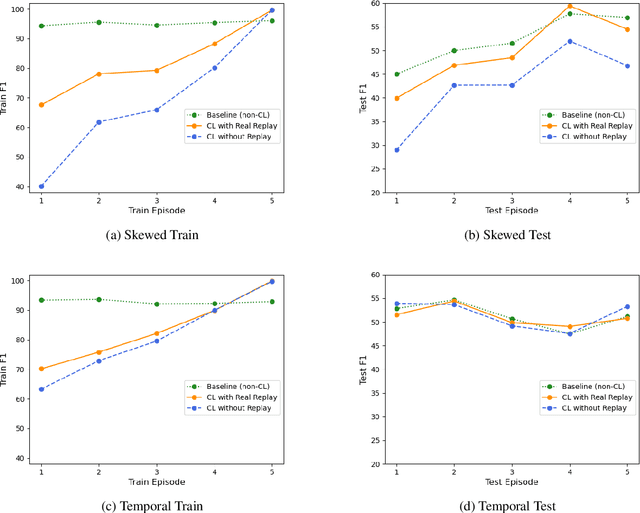
There is an increasing interest in continuous learning (CL), as data privacy is becoming a priority for real-world machine learning applications. Meanwhile, there is still a lack of academic NLP benchmarks that are applicable for realistic CL settings, which is a major challenge for the advancement of the field. In this paper we discuss some of the unrealistic data characteristics of public datasets, study the challenges of realistic single-task continuous learning as well as the effectiveness of data rehearsal as a way to mitigate accuracy loss. We construct a CL NER dataset from an existing publicly available dataset and release it along with the code to the research community.
Design Challenges in Named Entity Transliteration
Aug 07, 2018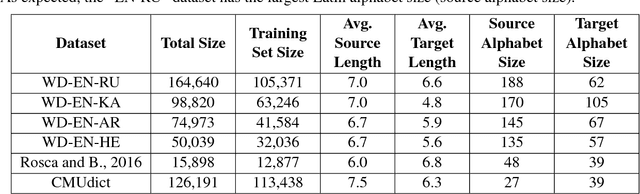



We analyze some of the fundamental design challenges that impact the development of a multilingual state-of-the-art named entity transliteration system, including curating bilingual named entity datasets and evaluation of multiple transliteration methods. We empirically evaluate the transliteration task using traditional weighted finite state transducer (WFST) approach against two neural approaches: the encoder-decoder recurrent neural network method and the recent, non-sequential Transformer method. In order to improve availability of bilingual named entity transliteration datasets, we release personal name bilingual dictionaries minded from Wikidata for English to Russian, Hebrew, Arabic and Japanese Katakana. Our code and dictionaries are publicly available.
Automated Generation of Multilingual Clusters for the Evaluation of Distributed Representations
Apr 05, 2017
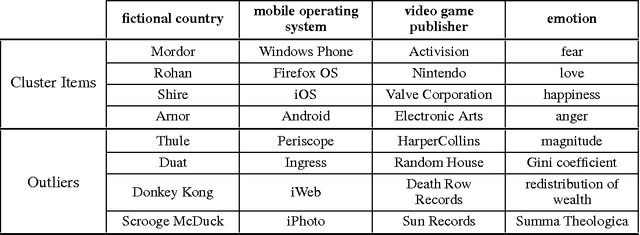
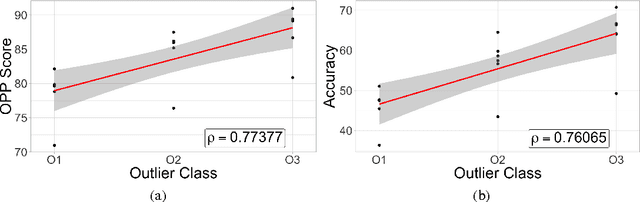
We propose a language-agnostic way of automatically generating sets of semantically similar clusters of entities along with sets of "outlier" elements, which may then be used to perform an intrinsic evaluation of word embeddings in the outlier detection task. We used our methodology to create a gold-standard dataset, which we call WikiSem500, and evaluated multiple state-of-the-art embeddings. The results show a correlation between performance on this dataset and performance on sentiment analysis.