Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Generation of Multilingual Clusters for the Evaluation of Distributed Representations
Apr 05, 2017
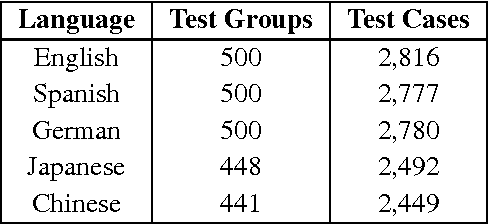
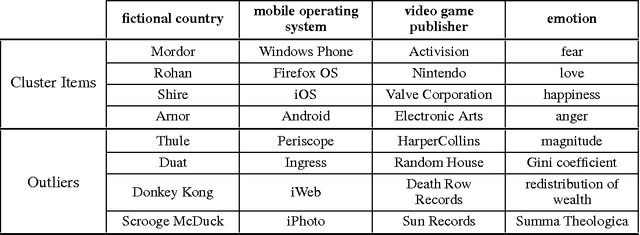
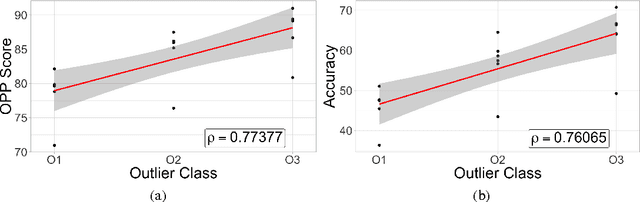
We propose a language-agnostic way of automatically generating sets of semantically similar clusters of entities along with sets of "outlier" elements, which may then be used to perform an intrinsic evaluation of word embeddings in the outlier detection task. We used our methodology to create a gold-standard dataset, which we call WikiSem500, and evaluated multiple state-of-the-art embeddings. The results show a correlation between performance on this dataset and performance on sentiment analysis.
* Published as a workshop paper at ICLR 2017
Via