 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Candidate Generation for Entity Linking on Short Social Media Texts
Oct 14, 2022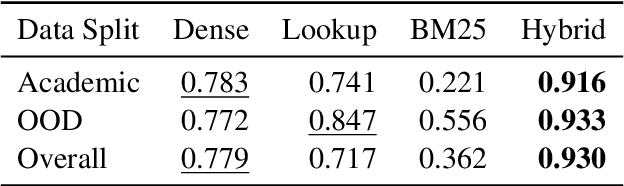
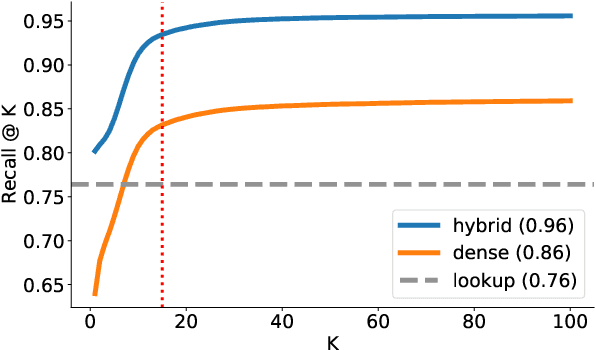
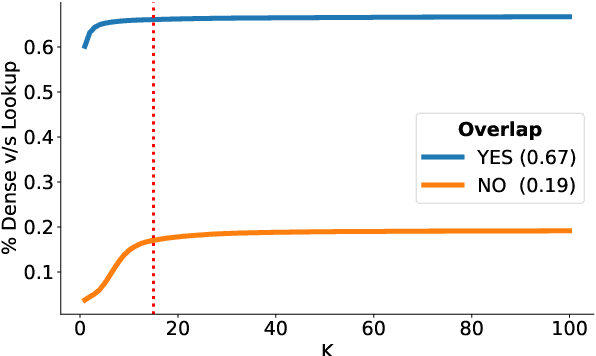
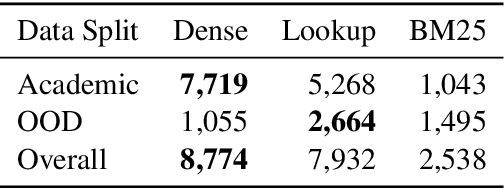
Entity Linking (EL) is the gateway into Knowledge Bases. Recent advances in EL utilize dense retrieval approaches for Candidate Generation, which addresses some of the shortcomings of the Lookup based approach of matching NER mentions against pre-computed dictionaries. In this work, we show that in the domain of Tweets, such methods suffer as users often include informal spelling, limited context, and lack of specificity, among other issues. We investigate these challenges on a large and recent Tweets benchmark for EL, empirically evaluate lookup and dense retrieval approaches, and demonstrate a hybrid solution using long contextual representation from Wikipedia is necessary to achieve considerable gains over previous work, achieving 0.93 recall.
TweetNERD -- End to End Entity Linking Benchmark for Tweets
Oct 14, 2022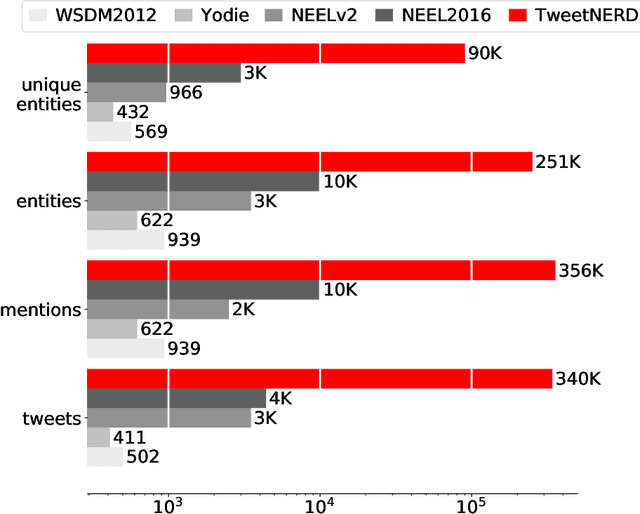


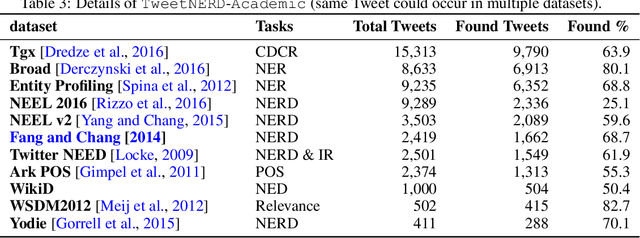
Named Entity Recognition and Disambiguation (NERD) systems are foundational for information retrieval, question answering, event detection, and other natural language processing (NLP) applications. We introduce TweetNERD, a dataset of 340K+ Tweets across 2010-2021, for benchmarking NERD systems on Tweets. This is the largest and most temporally diverse open sourced dataset benchmark for NERD on Tweets and can be used to facilitate research in this area. We describe evaluation setup with TweetNERD for three NERD tasks: Named Entity Recognition (NER), Entity Linking with True Spans (EL), and End to End Entity Linking (End2End); and provide performance of existing publicly available methods on specific TweetNERD splits. TweetNERD is available at: https://doi.org/10.5281/zenodo.6617192 under Creative Commons Attribution 4.0 International (CC BY 4.0) license. Check out more details at https://github.com/twitter-research/TweetNERD.