 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Whole Truth and Nothing But the Truth: Faithful and Controllable Dialogue Response Generation with Dataflow Transduction and Constrained Decoding
Sep 16, 2022
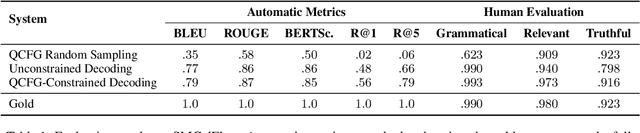
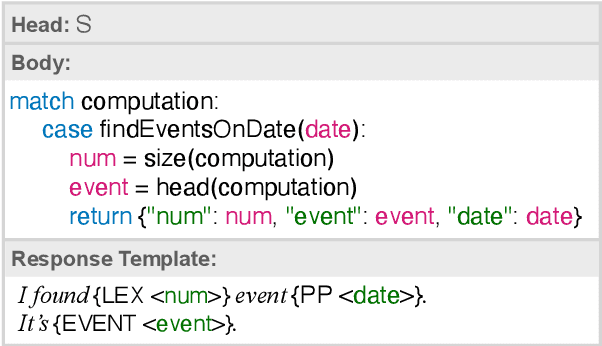
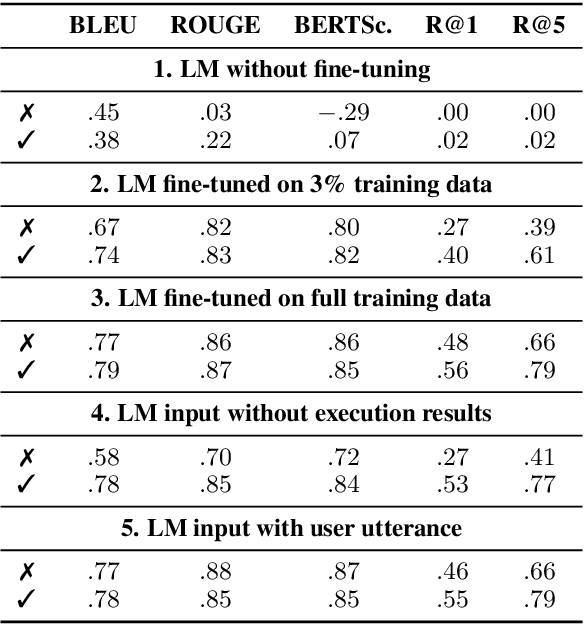
In a real-world dialogue system, generated responses must satisfy several interlocking constraints: being informative, truthful, and easy to control. The two predominant paradigms in language generation -- neural language modeling and rule-based generation -- both struggle to satisfy these constraints. Even the best neural models are prone to hallucination and omission of information, while existing formalisms for rule-based generation make it difficult to write grammars that are both flexible and fluent. We describe a hybrid architecture for dialogue response generation that combines the strengths of both approaches. This architecture has two components. First, a rule-based content selection model defined using a new formal framework called dataflow transduction, which uses declarative rules to transduce a dialogue agent's computations (represented as dataflow graphs) into context-free grammars representing the space of contextually acceptable responses. Second, a constrained decoding procedure that uses these grammars to constrain the output of a neural language model, which selects fluent utterances. The resulting system outperforms both rule-based and learned approaches in human evaluations of fluency, relevance, and truthfulness.
Task-Oriented Dialogue as Dataflow Synthesis
Oct 02, 2020We describe an approach to task-oriented dialogue in which dialogue state is represented as a dataflow graph. A dialogue agent maps each user utterance to a program that extends this graph. Programs include metacomputation operators for reference and revision that reuse dataflow fragments from previous turns. Our graph-based state enables the expression and manipulation of complex user intents, and explicit metacomputation makes these intents easier for learned models to predict. We introduce a new dataset, SMCalFlow, featuring complex dialogues about events, weather, places, and people. Experiments show that dataflow graphs and metacomputation substantially improve representability and predictability in these natural dialogues. Additional experiments on the MultiWOZ dataset show that our dataflow representation enables an otherwise off-the-shelf sequence-to-sequence model to match the best existing task-specific state tracking model. The SMCalFlow dataset and code for replicating experiments are available at https://www.microsoft.com/en-us/research/project/dataflow-based-dialogue-semantic-machines.