 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Whole Truth and Nothing But the Truth: Faithful and Controllable Dialogue Response Generation with Dataflow Transduction and Constrained Decoding
Sep 16, 2022
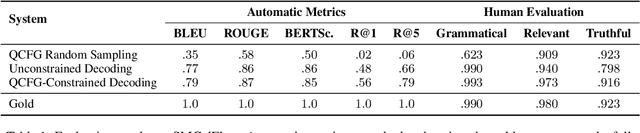
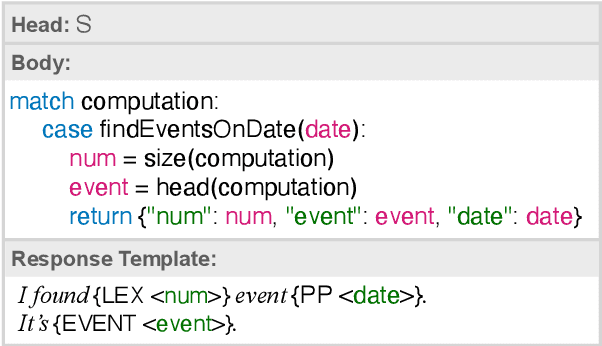
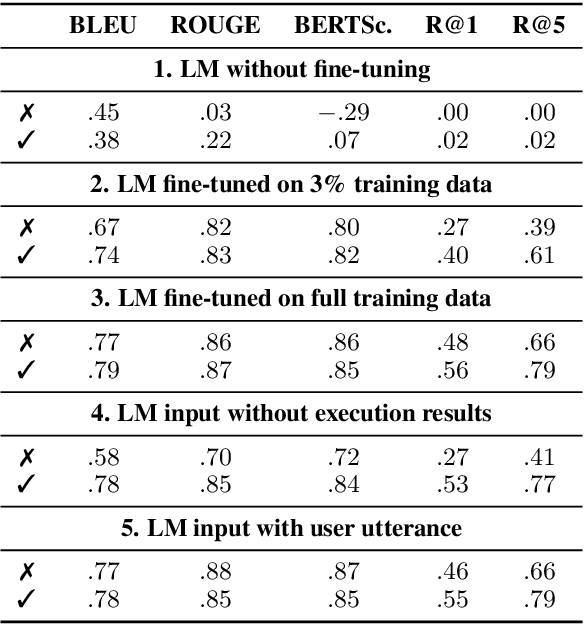
In a real-world dialogue system, generated responses must satisfy several interlocking constraints: being informative, truthful, and easy to control. The two predominant paradigms in language generation -- neural language modeling and rule-based generation -- both struggle to satisfy these constraints. Even the best neural models are prone to hallucination and omission of information, while existing formalisms for rule-based generation make it difficult to write grammars that are both flexible and fluent. We describe a hybrid architecture for dialogue response generation that combines the strengths of both approaches. This architecture has two components. First, a rule-based content selection model defined using a new formal framework called dataflow transduction, which uses declarative rules to transduce a dialogue agent's computations (represented as dataflow graphs) into context-free grammars representing the space of contextually acceptable responses. Second, a constrained decoding procedure that uses these grammars to constrain the output of a neural language model, which selects fluent utterances. The resulting system outperforms both rule-based and learned approaches in human evaluations of fluency, relevance, and truthfulness.
Task-Oriented Dialogue as Dataflow Synthesis
Oct 02, 2020We describe an approach to task-oriented dialogue in which dialogue state is represented as a dataflow graph. A dialogue agent maps each user utterance to a program that extends this graph. Programs include metacomputation operators for reference and revision that reuse dataflow fragments from previous turns. Our graph-based state enables the expression and manipulation of complex user intents, and explicit metacomputation makes these intents easier for learned models to predict. We introduce a new dataset, SMCalFlow, featuring complex dialogues about events, weather, places, and people. Experiments show that dataflow graphs and metacomputation substantially improve representability and predictability in these natural dialogues. Additional experiments on the MultiWOZ dataset show that our dataflow representation enables an otherwise off-the-shelf sequence-to-sequence model to match the best existing task-specific state tracking model. The SMCalFlow dataset and code for replicating experiments are available at https://www.microsoft.com/en-us/research/project/dataflow-based-dialogue-semantic-machines.
Structured Set Matching Networks for One-Shot Part Labeling
Apr 03, 2018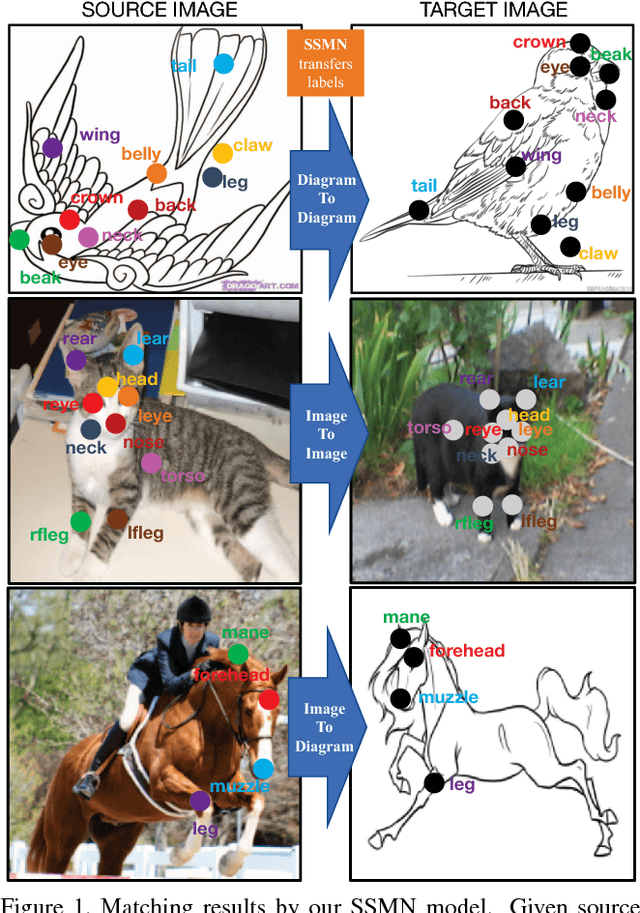
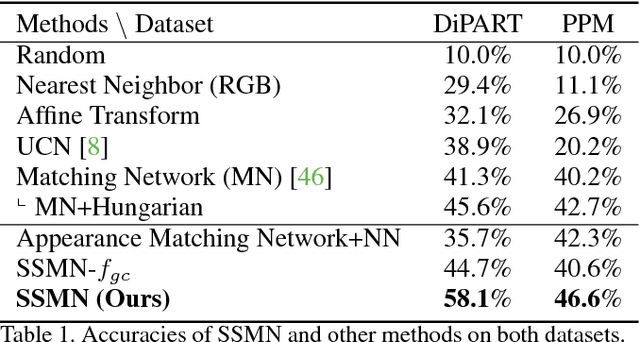
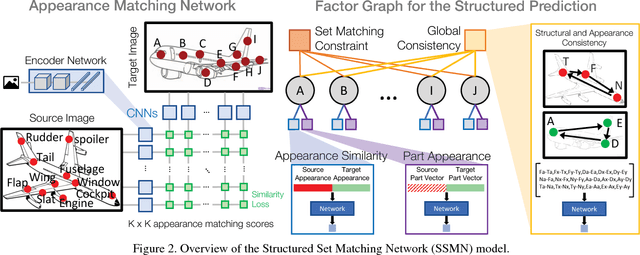

Diagrams often depict complex phenomena and serve as a good test bed for visual and textual reasoning. However, understanding diagrams using natural image understanding approaches requires large training datasets of diagrams, which are very hard to obtain. Instead, this can be addressed as a matching problem either between labeled diagrams, images or both. This problem is very challenging since the absence of significant color and texture renders local cues ambiguous and requires global reasoning. We consider the problem of one-shot part labeling: labeling multiple parts of an object in a target image given only a single source image of that category. For this set-to-set matching problem, we introduce the Structured Set Matching Network (SSMN), a structured prediction model that incorporates convolutional neural networks. The SSMN is trained using global normalization to maximize local match scores between corresponding elements and a global consistency score among all matched elements, while also enforcing a matching constraint between the two sets. The SSMN significantly outperforms several strong baselines on three label transfer scenarios: diagram-to-diagram, evaluated on a new diagram dataset of over 200 categories; image-to-image, evaluated on a dataset built on top of the Pascal Part Dataset; and image-to-diagram, evaluated on transferring labels across these datasets.
Learning a Neural Semantic Parser from User Feedback
Apr 27, 2017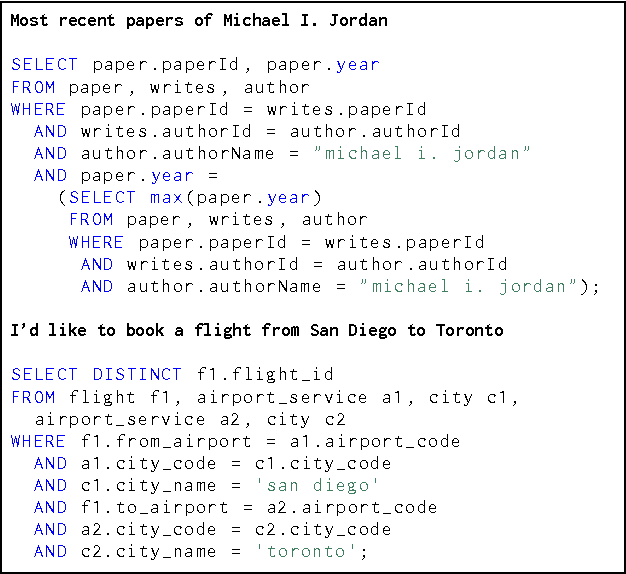
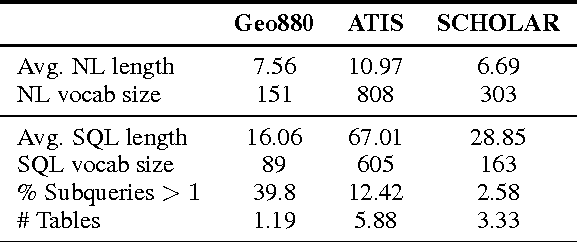
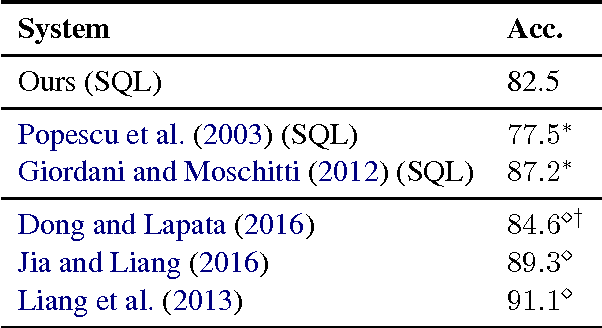
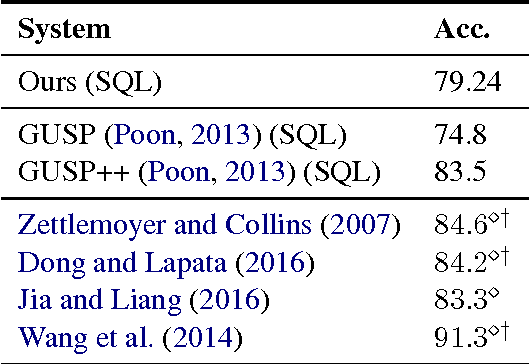
We present an approach to rapidly and easily build natural language interfaces to databases for new domains, whose performance improves over time based on user feedback, and requires minimal intervention. To achieve this, we adapt neural sequence models to map utterances directly to SQL with its full expressivity, bypassing any intermediate meaning representations. These models are immediately deployed online to solicit feedback from real users to flag incorrect queries. Finally, the popularity of SQL facilitates gathering annotations for incorrect predictions using the crowd, which is directly used to improve our models. This complete feedback loop, without intermediate representations or database specific engineering, opens up new ways of building high quality semantic parsers. Experiments suggest that this approach can be deployed quickly for any new target domain, as we show by learning a semantic parser for an online academic database from scratch.
Probabilistic Neural Programs
Dec 02, 2016
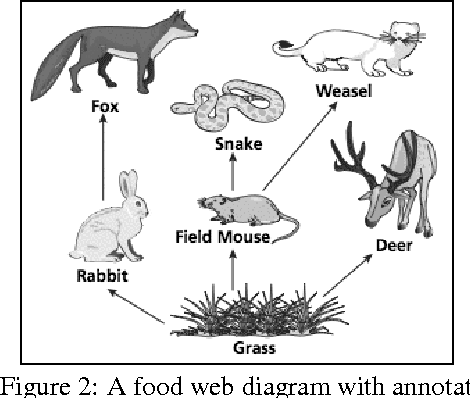
We present probabilistic neural programs, a framework for program induction that permits flexible specification of both a computational model and inference algorithm while simultaneously enabling the use of deep neural networks. Probabilistic neural programs combine a computation graph for specifying a neural network with an operator for weighted nondeterministic choice. Thus, a program describes both a collection of decisions as well as the neural network architecture used to make each one. We evaluate our approach on a challenging diagram question answering task where probabilistic neural programs correctly execute nearly twice as many programs as a baseline model.
Open-Vocabulary Semantic Parsing with both Distributional Statistics and Formal Knowledge
Nov 28, 2016
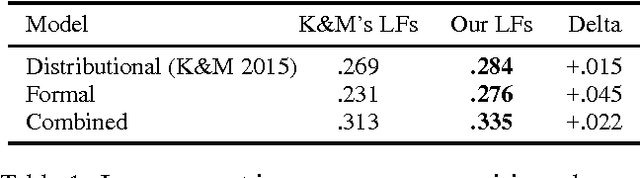
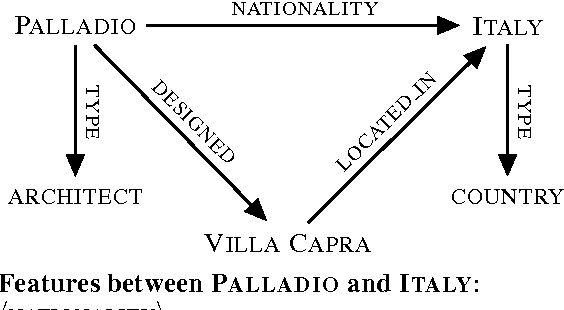

Traditional semantic parsers map language onto compositional, executable queries in a fixed schema. This mapping allows them to effectively leverage the information contained in large, formal knowledge bases (KBs, e.g., Freebase) to answer questions, but it is also fundamentally limiting---these semantic parsers can only assign meaning to language that falls within the KB's manually-produced schema. Recently proposed methods for open vocabulary semantic parsing overcome this limitation by learning execution models for arbitrary language, essentially using a text corpus as a kind of knowledge base. However, all prior approaches to open vocabulary semantic parsing replace a formal KB with textual information, making no use of the KB in their models. We show how to combine the disparate representations used by these two approaches, presenting for the first time a semantic parser that (1) produces compositional, executable representations of language, (2) can successfully leverage the information contained in both a formal KB and a large corpus, and (3) is not limited to the schema of the underlying KB. We demonstrate significantly improved performance over state-of-the-art baselines on an open-domain natural language question answering task.
Semantic Parsing to Probabilistic Programs for Situated Question Answering
Sep 24, 2016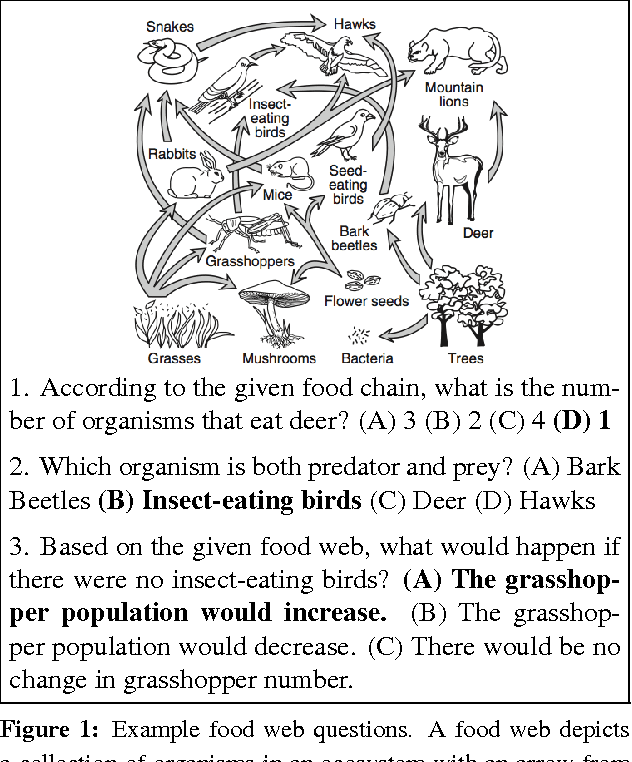
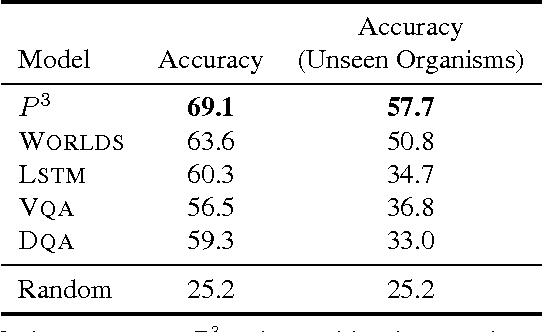
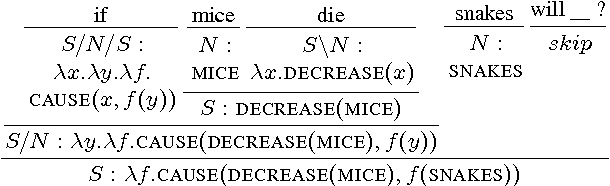

Situated question answering is the problem of answering questions about an environment such as an image or diagram. This problem requires jointly interpreting a question and an environment using background knowledge to select the correct answer. We present Parsing to Probabilistic Programs (P3), a novel situated question answering model that can use background knowledge and global features of the question/environment interpretation while retaining efficient approximate inference. Our key insight is to treat semantic parses as probabilistic programs that execute nondeterministically and whose possible executions represent environmental uncertainty. We evaluate our approach on a new, publicly-released data set of 5000 science diagram questions, outperforming several competitive classical and neural baselines.