 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArticulate AnyMesh: Open-Vocabulary 3D Articulated Objects Modeling
Feb 04, 2025



3D articulated objects modeling has long been a challenging problem, since it requires to capture both accurate surface geometries and semantically meaningful and spatially precise structures, parts, and joints. Existing methods heavily depend on training data from a limited set of handcrafted articulated object categories (e.g., cabinets and drawers), which restricts their ability to model a wide range of articulated objects in an open-vocabulary context. To address these limitations, we propose Articulate Anymesh, an automated framework that is able to convert any rigid 3D mesh into its articulated counterpart in an open-vocabulary manner. Given a 3D mesh, our framework utilizes advanced Vision-Language Models and visual prompting techniques to extract semantic information, allowing for both the segmentation of object parts and the construction of functional joints. Our experiments show that Articulate Anymesh can generate large-scale, high-quality 3D articulated objects, including tools, toys, mechanical devices, and vehicles, significantly expanding the coverage of existing 3D articulated object datasets. Additionally, we show that these generated assets can facilitate the acquisition of new articulated object manipulation skills in simulation, which can then be transferred to a real robotic system. Our Github website is https://articulate-anymesh.github.io.
UBSoft: A Simulation Platform for Robotic Skill Learning in Unbounded Soft Environments
Nov 19, 2024It is desired to equip robots with the capability of interacting with various soft materials as they are ubiquitous in the real world. While physics simulations are one of the predominant methods for data collection and robot training, simulating soft materials presents considerable challenges. Specifically, it is significantly more costly than simulating rigid objects in terms of simulation speed and storage requirements. These limitations typically restrict the scope of studies on soft materials to small and bounded areas, thereby hindering the learning of skills in broader spaces. To address this issue, we introduce UBSoft, a new simulation platform designed to support unbounded soft environments for robot skill acquisition. Our platform utilizes spatially adaptive resolution scales, where simulation resolution dynamically adjusts based on proximity to active robotic agents. Our framework markedly reduces the demand for extensive storage space and computation costs required for large-scale scenarios involving soft materials. We also establish a set of benchmark tasks in our platform, including both locomotion and manipulation tasks, and conduct experiments to evaluate the efficacy of various reinforcement learning algorithms and trajectory optimization techniques, both gradient-based and sampling-based. Preliminary results indicate that sampling-based trajectory optimization generally achieves better results for obtaining one trajectory to solve the task. Additionally, we conduct experiments in real-world environments to demonstrate that advancements made in our UBSoft simulator could translate to improved robot interactions with large-scale soft material. More videos can be found at https://vis-www.cs.umass.edu/ubsoft/.
Architect: Generating Vivid and Interactive 3D Scenes with Hierarchical 2D Inpainting
Nov 14, 2024

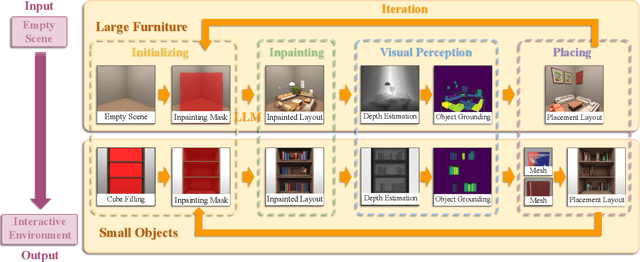
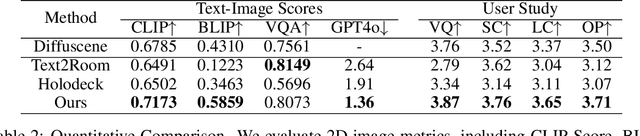
Creating large-scale interactive 3D environments is essential for the development of Robotics and Embodied AI research. Current methods, including manual design, procedural generation, diffusion-based scene generation, and large language model (LLM) guided scene design, are hindered by limitations such as excessive human effort, reliance on predefined rules or training datasets, and limited 3D spatial reasoning ability. Since pre-trained 2D image generative models better capture scene and object configuration than LLMs, we address these challenges by introducing Architect, a generative framework that creates complex and realistic 3D embodied environments leveraging diffusion-based 2D image inpainting. In detail, we utilize foundation visual perception models to obtain each generated object from the image and leverage pre-trained depth estimation models to lift the generated 2D image to 3D space. Our pipeline is further extended to a hierarchical and iterative inpainting process to continuously generate placement of large furniture and small objects to enrich the scene. This iterative structure brings the flexibility for our method to generate or refine scenes from various starting points, such as text, floor plans, or pre-arranged environments.
Thin-Shell Object Manipulations With Differentiable Physics Simulations
Mar 30, 2024



In this work, we aim to teach robots to manipulate various thin-shell materials. Prior works studying thin-shell object manipulation mostly rely on heuristic policies or learn policies from real-world video demonstrations, and only focus on limited material types and tasks (e.g., cloth unfolding). However, these approaches face significant challenges when extended to a wider variety of thin-shell materials and a diverse range of tasks. While virtual simulations are shown to be effective in diverse robot skill learning and evaluation, prior thin-shell simulation environments only support a subset of thin-shell materials, which also limits their supported range of tasks. We introduce ThinShellLab - a fully differentiable simulation platform tailored for robotic interactions with diverse thin-shell materials possessing varying material properties, enabling flexible thin-shell manipulation skill learning and evaluation. Our experiments suggest that manipulating thin-shell objects presents several unique challenges: 1) thin-shell manipulation relies heavily on frictional forces due to the objects' co-dimensional nature, 2) the materials being manipulated are highly sensitive to minimal variations in interaction actions, and 3) the constant and frequent alteration in contact pairs makes trajectory optimization methods susceptible to local optima, and neither standard reinforcement learning algorithms nor trajectory optimization methods (either gradient-based or gradient-free) are able to solve the tasks alone. To overcome these challenges, we present an optimization scheme that couples sampling-based trajectory optimization and gradient-based optimization, boosting both learning efficiency and converged performance across various proposed tasks. In addition, the differentiable nature of our platform facilitates a smooth sim-to-real transition.
DIFFTACTILE: A Physics-based Differentiable Tactile Simulator for Contact-rich Robotic Manipulation
Mar 13, 2024We introduce DIFFTACTILE, a physics-based differentiable tactile simulation system designed to enhance robotic manipulation with dense and physically accurate tactile feedback. In contrast to prior tactile simulators which primarily focus on manipulating rigid bodies and often rely on simplified approximations to model stress and deformations of materials in contact, DIFFTACTILE emphasizes physics-based contact modeling with high fidelity, supporting simulations of diverse contact modes and interactions with objects possessing a wide range of material properties. Our system incorporates several key components, including a Finite Element Method (FEM)-based soft body model for simulating the sensing elastomer, a multi-material simulator for modeling diverse object types (such as elastic, elastoplastic, cables) under manipulation, a penalty-based contact model for handling contact dynamics. The differentiable nature of our system facilitates gradient-based optimization for both 1) refining physical properties in simulation using real-world data, hence narrowing the sim-to-real gap and 2) efficient learning of tactile-assisted grasping and contact-rich manipulation skills. Additionally, we introduce a method to infer the optical response of our tactile sensor to contact using an efficient pixel-based neural module. We anticipate that DIFFTACTILE will serve as a useful platform for studying contact-rich manipulations, leveraging the benefits of dense tactile feedback and differentiable physics. Code and supplementary materials are available at the project website https://difftactile.github.io/.
RL-VLM-F: Reinforcement Learning from Vision Language Foundation Model Feedback
Feb 10, 2024



Reward engineering has long been a challenge in Reinforcement Learning (RL) research, as it often requires extensive human effort and iterative processes of trial-and-error to design effective reward functions. In this paper, we propose RL-VLM-F, a method that automatically generates reward functions for agents to learn new tasks, using only a text description of the task goal and the agent's visual observations, by leveraging feedbacks from vision language foundation models (VLMs). The key to our approach is to query these models to give preferences over pairs of the agent's image observations based on the text description of the task goal, and then learn a reward function from the preference labels, rather than directly prompting these models to output a raw reward score, which can be noisy and inconsistent. We demonstrate that RL-VLM-F successfully produces effective rewards and policies across various domains - including classic control, as well as manipulation of rigid, articulated, and deformable objects - without the need for human supervision, outperforming prior methods that use large pretrained models for reward generation under the same assumptions.
RoboGen: Towards Unleashing Infinite Data for Automated Robot Learning via Generative Simulation
Nov 13, 2023

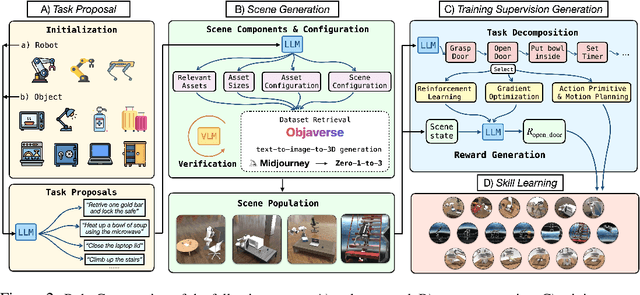

We present RoboGen, a generative robotic agent that automatically learns diverse robotic skills at scale via generative simulation. RoboGen leverages the latest advancements in foundation and generative models. Instead of directly using or adapting these models to produce policies or low-level actions, we advocate for a generative scheme, which uses these models to automatically generate diversified tasks, scenes, and training supervisions, thereby scaling up robotic skill learning with minimal human supervision. Our approach equips a robotic agent with a self-guided propose-generate-learn cycle: the agent first proposes interesting tasks and skills to develop, and then generates corresponding simulation environments by populating pertinent objects and assets with proper spatial configurations. Afterwards, the agent decomposes the proposed high-level task into sub-tasks, selects the optimal learning approach (reinforcement learning, motion planning, or trajectory optimization), generates required training supervision, and then learns policies to acquire the proposed skill. Our work attempts to extract the extensive and versatile knowledge embedded in large-scale models and transfer them to the field of robotics. Our fully generative pipeline can be queried repeatedly, producing an endless stream of skill demonstrations associated with diverse tasks and environments.
Gen2Sim: Scaling up Robot Learning in Simulation with Generative Models
Oct 27, 2023Generalist robot manipulators need to learn a wide variety of manipulation skills across diverse environments. Current robot training pipelines rely on humans to provide kinesthetic demonstrations or to program simulation environments and to code up reward functions for reinforcement learning. Such human involvement is an important bottleneck towards scaling up robot learning across diverse tasks and environments. We propose Generation to Simulation (Gen2Sim), a method for scaling up robot skill learning in simulation by automating generation of 3D assets, task descriptions, task decompositions and reward functions using large pre-trained generative models of language and vision. We generate 3D assets for simulation by lifting open-world 2D object-centric images to 3D using image diffusion models and querying LLMs to determine plausible physics parameters. Given URDF files of generated and human-developed assets, we chain-of-thought prompt LLMs to map these to relevant task descriptions, temporal decompositions, and corresponding python reward functions for reinforcement learning. We show Gen2Sim succeeds in learning policies for diverse long horizon tasks, where reinforcement learning with non temporally decomposed reward functions fails. Gen2Sim provides a viable path for scaling up reinforcement learning for robot manipulators in simulation, both by diversifying and expanding task and environment development, and by facilitating the discovery of reinforcement-learned behaviors through temporal task decomposition in RL. Our work contributes hundreds of simulated assets, tasks and demonstrations, taking a step towards fully autonomous robotic manipulation skill acquisition in simulation.
Act3D: Infinite Resolution Action Detection Transformer for Robotic Manipulation
Jun 30, 2023



3D perceptual representations are well suited for robot manipulation as they easily encode occlusions and simplify spatial reasoning. Many manipulation tasks require high spatial precision in end-effector pose prediction, typically demanding high-resolution 3D perceptual grids that are computationally expensive to process. As a result, most manipulation policies operate directly in 2D, foregoing 3D inductive biases. In this paper, we propose Act3D, a manipulation policy Transformer that casts 6-DoF keypose prediction as 3D detection with adaptive spatial computation. It takes as input 3D feature clouds unprojected from one or more camera views, iteratively samples 3D point grids in free space in a coarse-to-fine manner, featurizes them using relative spatial attention to the physical feature cloud, and selects the best feature point for end-effector pose prediction. Act3D sets a new state-of-the-art in RLbench, an established manipulation benchmark. Our model achieves 10% absolute improvement over the previous SOTA 2D multi-view policy on 74 RLbench tasks and 22% absolute improvement with 3x less compute over the previous SOTA 3D policy. In thorough ablations, we show the importance of relative spatial attention, large-scale vision-language pre-trained 2D backbones, and weight tying across coarse-to-fine attentions. Code and videos are available at our project site: https://act3d.github.io/.
Towards A Foundation Model for Generalist Robots: Diverse Skill Learning at Scale via Automated Task and Scene Generation
May 17, 2023



This document serves as a position paper that outlines the authors' vision for a potential pathway towards generalist robots. The purpose of this document is to share the excitement of the authors with the community and highlight a promising research direction in robotics and AI. The authors believe the proposed paradigm is a feasible path towards accomplishing the long-standing goal of robotics research: deploying robots, or embodied AI agents more broadly, in various non-factory real-world settings to perform diverse tasks. This document presents a specific idea for mining knowledge in the latest large-scale foundation models for robotics research. Instead of directly adapting these models or using them to guide low-level policy learning, it advocates for using them to generate diversified tasks and scenes at scale, thereby scaling up low-level skill learning and ultimately leading to a foundation model for robotics that empowers generalist robots. The authors are actively pursuing this direction, but in the meantime, they recognize that the ambitious goal of building generalist robots with large-scale policy training demands significant resources such as computing power and hardware, and research groups in academia alone may face severe resource constraints in implementing the entire vision. Therefore, the authors believe sharing their thoughts at this early stage could foster discussions, attract interest towards the proposed pathway and related topics from industry groups, and potentially spur significant technical advancements in the field.