 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPR-1: Interactive Physical Reasoner
Nov 19, 2025Humans learn by observing, interacting with environments, and internalizing physics and causality. Here, we aim to ask whether an agent can similarly acquire human-like reasoning from interaction and keep improving with more experience. We study this in a Game-to-Unseen (G2U) setting, curating 1,000+ heterogeneous games with diverse physical and causal mechanisms, and evaluate at three human-like levels: Survival, Curiosity, Utility, from primitive intuition to goal-driven reasoning. Our analysis reveals complementary failures: VLM/VLA agents reason but lack look-ahead in interactive settings, while world models imagine but imitate visual patterns rather than analyze physics and causality. We therefore propose IPR (Interactive Physical Reasoner), using world-model rollouts to score and reinforce a VLM's policy, and introduce PhysCode, a physics-centric action code aligning semantic intent with dynamics to provide a shared action space for prediction and reasoning. Pretrained on 1,000+ games, our IPR performs robustly on three levels, matches GPT-5 overall, and surpasses it on Curiosity. We find that performance improves with more training games and interaction steps, and that the model also zero-shot transfers to unseen games. These results support physics-centric interaction as a path to steadily improving physical reasoning.
LuciBot: Automated Robot Policy Learning from Generated Videos
Mar 12, 2025Automatically generating training supervision for embodied tasks is crucial, as manual designing is tedious and not scalable. While prior works use large language models (LLMs) or vision-language models (VLMs) to generate rewards, these approaches are largely limited to simple tasks with well-defined rewards, such as pick-and-place. This limitation arises because LLMs struggle to interpret complex scenes compressed into text or code due to their restricted input modality, while VLM-based rewards, though better at visual perception, remain limited by their less expressive output modality. To address these challenges, we leverage the imagination capability of general-purpose video generation models. Given an initial simulation frame and a textual task description, the video generation model produces a video demonstrating task completion with correct semantics. We then extract rich supervisory signals from the generated video, including 6D object pose sequences, 2D segmentations, and estimated depth, to facilitate task learning in simulation. Our approach significantly improves supervision quality for complex embodied tasks, enabling large-scale training in simulators.
Architect: Generating Vivid and Interactive 3D Scenes with Hierarchical 2D Inpainting
Nov 14, 2024

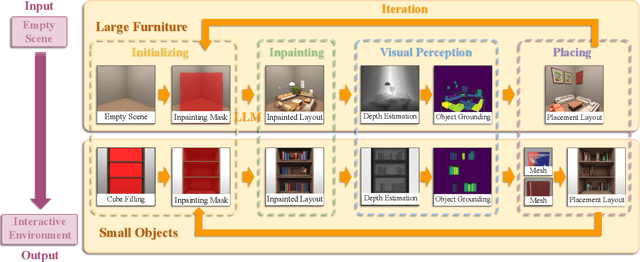
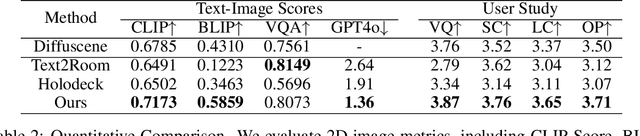
Creating large-scale interactive 3D environments is essential for the development of Robotics and Embodied AI research. Current methods, including manual design, procedural generation, diffusion-based scene generation, and large language model (LLM) guided scene design, are hindered by limitations such as excessive human effort, reliance on predefined rules or training datasets, and limited 3D spatial reasoning ability. Since pre-trained 2D image generative models better capture scene and object configuration than LLMs, we address these challenges by introducing Architect, a generative framework that creates complex and realistic 3D embodied environments leveraging diffusion-based 2D image inpainting. In detail, we utilize foundation visual perception models to obtain each generated object from the image and leverage pre-trained depth estimation models to lift the generated 2D image to 3D space. Our pipeline is further extended to a hierarchical and iterative inpainting process to continuously generate placement of large furniture and small objects to enrich the scene. This iterative structure brings the flexibility for our method to generate or refine scenes from various starting points, such as text, floor plans, or pre-arranged environments.
Take A Step Back: Rethinking the Two Stages in Visual Reasoning
Jul 29, 2024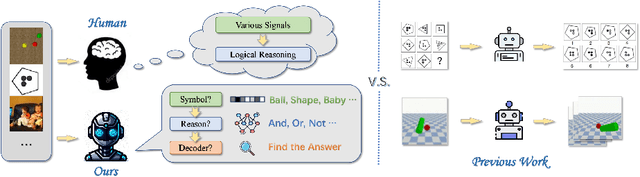

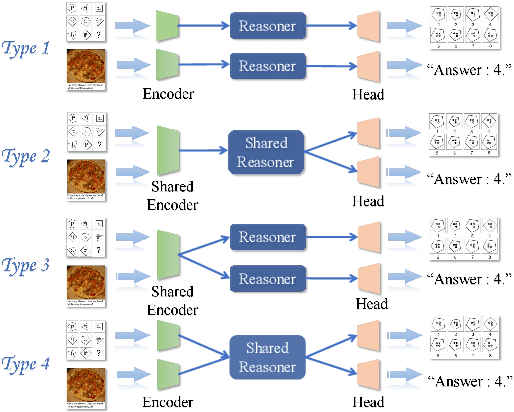
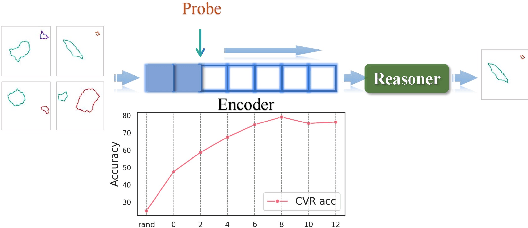
Visual reasoning, as a prominent research area, plays a crucial role in AI by facilitating concept formation and interaction with the world. However, current works are usually carried out separately on small datasets thus lacking generalization ability. Through rigorous evaluation of diverse benchmarks, we demonstrate the shortcomings of existing ad-hoc methods in achieving cross-domain reasoning and their tendency to data bias fitting. In this paper, we revisit visual reasoning with a two-stage perspective: (1) symbolization and (2) logical reasoning given symbols or their representations. We find that the reasoning stage is better at generalization than symbolization. Thus, it is more efficient to implement symbolization via separated encoders for different data domains while using a shared reasoner. Given our findings, we establish design principles for visual reasoning frameworks following the separated symbolization and shared reasoning. The proposed two-stage framework achieves impressive generalization ability on various visual reasoning tasks, including puzzles, physical prediction, and visual question answering (VQA), encompassing both 2D and 3D modalities. We believe our insights will pave the way for generalizable visual reasoning.