 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotSmith: Generative Robotic Tool Design for Acquisition of Complex Manipulation Skills
Jun 17, 2025



Endowing robots with tool design abilities is critical for enabling them to solve complex manipulation tasks that would otherwise be intractable. While recent generative frameworks can automatically synthesize task settings, such as 3D scenes and reward functions, they have not yet addressed the challenge of tool-use scenarios. Simply retrieving human-designed tools might not be ideal since many tools (e.g., a rolling pin) are difficult for robotic manipulators to handle. Furthermore, existing tool design approaches either rely on predefined templates with limited parameter tuning or apply generic 3D generation methods that are not optimized for tool creation. To address these limitations, we propose RobotSmith, an automated pipeline that leverages the implicit physical knowledge embedded in vision-language models (VLMs) alongside the more accurate physics provided by physics simulations to design and use tools for robotic manipulation. Our system (1) iteratively proposes tool designs using collaborative VLM agents, (2) generates low-level robot trajectories for tool use, and (3) jointly optimizes tool geometry and usage for task performance. We evaluate our approach across a wide range of manipulation tasks involving rigid, deformable, and fluid objects. Experiments show that our method consistently outperforms strong baselines in terms of both task success rate and overall performance. Notably, our approach achieves a 50.0\% average success rate, significantly surpassing other baselines such as 3D generation (21.4%) and tool retrieval (11.1%). Finally, we deploy our system in real-world settings, demonstrating that the generated tools and their usage plans transfer effectively to physical execution, validating the practicality and generalization capabilities of our approach.
TopoGaussian: Inferring Internal Topology Structures from Visual Clues
Mar 16, 2025We present TopoGaussian, a holistic, particle-based pipeline for inferring the interior structure of an opaque object from easily accessible photos and videos as input. Traditional mesh-based approaches require tedious and error-prone mesh filling and fixing process, while typically output rough boundary surface. Our pipeline combines Gaussian Splatting with a novel, versatile particle-based differentiable simulator that simultaneously accommodates constitutive model, actuator, and collision, without interference with mesh. Based on the gradients from this simulator, we provide flexible choice of topology representation for optimization, including particle, neural implicit surface, and quadratic surface. The resultant pipeline takes easily accessible photos and videos as input and outputs the topology that matches the physical characteristics of the input. We demonstrate the efficacy of our pipeline on a synthetic dataset and four real-world tasks with 3D-printed prototypes. Compared with existing mesh-based method, our pipeline is 5.26x faster on average with improved shape quality. These results highlight the potential of our pipeline in 3D vision, soft robotics, and manufacturing applications.
LuciBot: Automated Robot Policy Learning from Generated Videos
Mar 12, 2025Automatically generating training supervision for embodied tasks is crucial, as manual designing is tedious and not scalable. While prior works use large language models (LLMs) or vision-language models (VLMs) to generate rewards, these approaches are largely limited to simple tasks with well-defined rewards, such as pick-and-place. This limitation arises because LLMs struggle to interpret complex scenes compressed into text or code due to their restricted input modality, while VLM-based rewards, though better at visual perception, remain limited by their less expressive output modality. To address these challenges, we leverage the imagination capability of general-purpose video generation models. Given an initial simulation frame and a textual task description, the video generation model produces a video demonstrating task completion with correct semantics. We then extract rich supervisory signals from the generated video, including 6D object pose sequences, 2D segmentations, and estimated depth, to facilitate task learning in simulation. Our approach significantly improves supervision quality for complex embodied tasks, enabling large-scale training in simulators.
UBSoft: A Simulation Platform for Robotic Skill Learning in Unbounded Soft Environments
Nov 19, 2024It is desired to equip robots with the capability of interacting with various soft materials as they are ubiquitous in the real world. While physics simulations are one of the predominant methods for data collection and robot training, simulating soft materials presents considerable challenges. Specifically, it is significantly more costly than simulating rigid objects in terms of simulation speed and storage requirements. These limitations typically restrict the scope of studies on soft materials to small and bounded areas, thereby hindering the learning of skills in broader spaces. To address this issue, we introduce UBSoft, a new simulation platform designed to support unbounded soft environments for robot skill acquisition. Our platform utilizes spatially adaptive resolution scales, where simulation resolution dynamically adjusts based on proximity to active robotic agents. Our framework markedly reduces the demand for extensive storage space and computation costs required for large-scale scenarios involving soft materials. We also establish a set of benchmark tasks in our platform, including both locomotion and manipulation tasks, and conduct experiments to evaluate the efficacy of various reinforcement learning algorithms and trajectory optimization techniques, both gradient-based and sampling-based. Preliminary results indicate that sampling-based trajectory optimization generally achieves better results for obtaining one trajectory to solve the task. Additionally, we conduct experiments in real-world environments to demonstrate that advancements made in our UBSoft simulator could translate to improved robot interactions with large-scale soft material. More videos can be found at https://vis-www.cs.umass.edu/ubsoft/.
DiffVL: Scaling Up Soft Body Manipulation using Vision-Language Driven Differentiable Physics
Dec 11, 2023


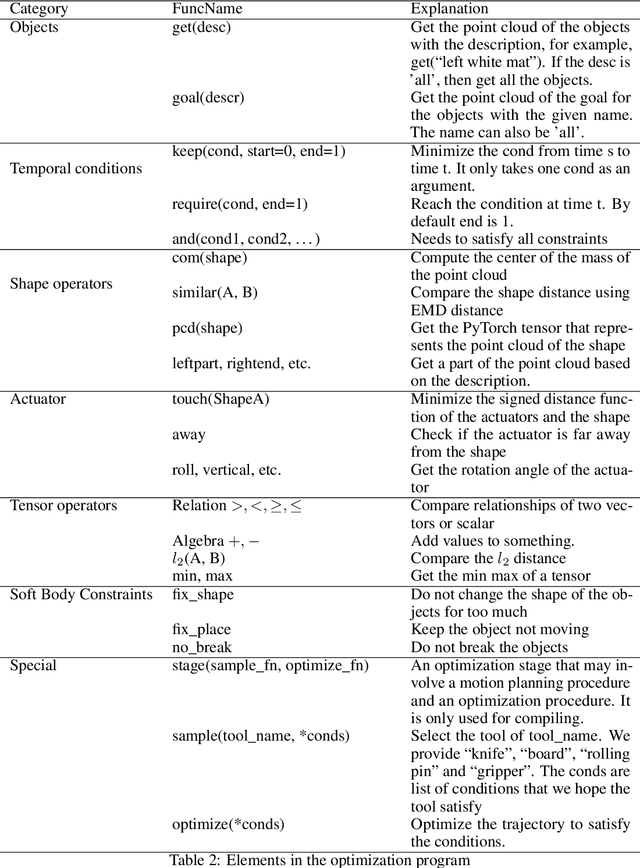
Combining gradient-based trajectory optimization with differentiable physics simulation is an efficient technique for solving soft-body manipulation problems. Using a well-crafted optimization objective, the solver can quickly converge onto a valid trajectory. However, writing the appropriate objective functions requires expert knowledge, making it difficult to collect a large set of naturalistic problems from non-expert users. We introduce DiffVL, a method that enables non-expert users to communicate soft-body manipulation tasks -- a combination of vision and natural language, given in multiple stages -- that can be readily leveraged by a differential physics solver. We have developed GUI tools that enable non-expert users to specify 100 tasks inspired by real-life soft-body manipulations from online videos, which we'll make public. We leverage large language models to translate task descriptions into machine-interpretable optimization objectives. The optimization objectives can help differentiable physics solvers to solve these long-horizon multistage tasks that are challenging for previous baselines.
3D Concept Learning and Reasoning from Multi-View Images
Mar 20, 2023



Humans are able to accurately reason in 3D by gathering multi-view observations of the surrounding world. Inspired by this insight, we introduce a new large-scale benchmark for 3D multi-view visual question answering (3DMV-VQA). This dataset is collected by an embodied agent actively moving and capturing RGB images in an environment using the Habitat simulator. In total, it consists of approximately 5k scenes, 600k images, paired with 50k questions. We evaluate various state-of-the-art models for visual reasoning on our benchmark and find that they all perform poorly. We suggest that a principled approach for 3D reasoning from multi-view images should be to infer a compact 3D representation of the world from the multi-view images, which is further grounded on open-vocabulary semantic concepts, and then to execute reasoning on these 3D representations. As the first step towards this approach, we propose a novel 3D concept learning and reasoning (3D-CLR) framework that seamlessly combines these components via neural fields, 2D pre-trained vision-language models, and neural reasoning operators. Experimental results suggest that our framework outperforms baseline models by a large margin, but the challenge remains largely unsolved. We further perform an in-depth analysis of the challenges and highlight potential future directions.
3D Concept Grounding on Neural Fields
Jul 13, 2022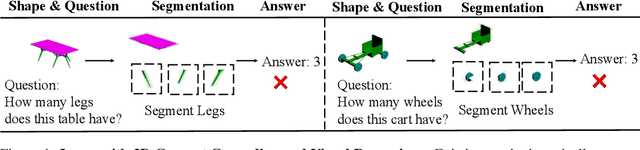
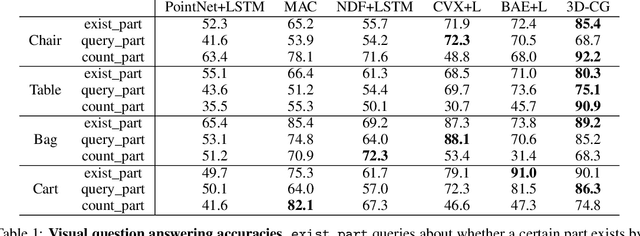
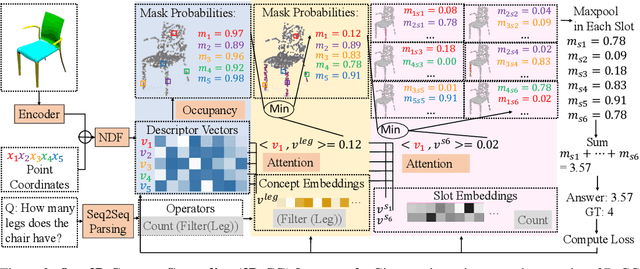
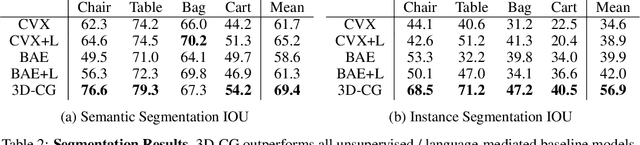
In this paper, we address the challenging problem of 3D concept grounding (i.e. segmenting and learning visual concepts) by looking at RGBD images and reasoning about paired questions and answers. Existing visual reasoning approaches typically utilize supervised methods to extract 2D segmentation masks on which concepts are grounded. In contrast, humans are capable of grounding concepts on the underlying 3D representation of images. However, traditionally inferred 3D representations (e.g., point clouds, voxelgrids, and meshes) cannot capture continuous 3D features flexibly, thus making it challenging to ground concepts to 3D regions based on the language description of the object being referred to. To address both issues, we propose to leverage the continuous, differentiable nature of neural fields to segment and learn concepts. Specifically, each 3D coordinate in a scene is represented as a high-dimensional descriptor. Concept grounding can then be performed by computing the similarity between the descriptor vector of a 3D coordinate and the vector embedding of a language concept, which enables segmentations and concept learning to be jointly learned on neural fields in a differentiable fashion. As a result, both 3D semantic and instance segmentations can emerge directly from question answering supervision using a set of defined neural operators on top of neural fields (e.g., filtering and counting). Experimental results show that our proposed framework outperforms unsupervised/language-mediated segmentation models on semantic and instance segmentation tasks, as well as outperforms existing models on the challenging 3D aware visual reasoning tasks. Furthermore, our framework can generalize well to unseen shape categories and real scans.