 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Community: An Open World for Humans, Robots, and Society
Aug 20, 2025

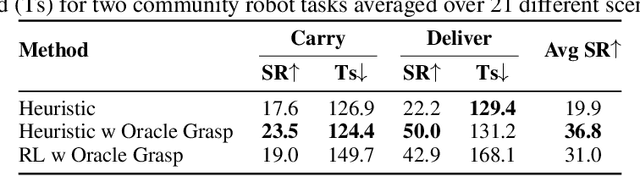

The rapid progress in AI and Robotics may lead to a profound societal transformation, as humans and robots begin to coexist within shared communities, introducing both opportunities and challenges. To explore this future, we present Virtual Community-an open-world platform for humans, robots, and society-built on a universal physics engine and grounded in real-world 3D scenes. With Virtual Community, we aim to study embodied social intelligence at scale: 1) How robots can intelligently cooperate or compete; 2) How humans develop social relations and build community; 3) More importantly, how intelligent robots and humans can co-exist in an open world. To support these, Virtual Community features: 1) An open-source multi-agent physics simulator that supports robots, humans, and their interactions within a society; 2) A large-scale, real-world aligned community generation pipeline, including vast outdoor space, diverse indoor scenes, and a community of grounded agents with rich characters and appearances. Leveraging Virtual Community, we propose two novel challenges. The Community Planning Challenge evaluates multi-agent reasoning and planning ability in open-world settings, such as cooperating to help agents with daily activities and efficiently connecting other agents. The Community Robot Challenge requires multiple heterogeneous robots to collaborate in solving complex open-world tasks. We evaluate various baselines on these tasks and demonstrate the challenges in both high-level open-world task planning and low-level cooperation controls. We hope that Virtual Community will unlock further study of human-robot coexistence within open-world environments.
Articulate AnyMesh: Open-Vocabulary 3D Articulated Objects Modeling
Feb 04, 2025



3D articulated objects modeling has long been a challenging problem, since it requires to capture both accurate surface geometries and semantically meaningful and spatially precise structures, parts, and joints. Existing methods heavily depend on training data from a limited set of handcrafted articulated object categories (e.g., cabinets and drawers), which restricts their ability to model a wide range of articulated objects in an open-vocabulary context. To address these limitations, we propose Articulate Anymesh, an automated framework that is able to convert any rigid 3D mesh into its articulated counterpart in an open-vocabulary manner. Given a 3D mesh, our framework utilizes advanced Vision-Language Models and visual prompting techniques to extract semantic information, allowing for both the segmentation of object parts and the construction of functional joints. Our experiments show that Articulate Anymesh can generate large-scale, high-quality 3D articulated objects, including tools, toys, mechanical devices, and vehicles, significantly expanding the coverage of existing 3D articulated object datasets. Additionally, we show that these generated assets can facilitate the acquisition of new articulated object manipulation skills in simulation, which can then be transferred to a real robotic system. Our Github website is https://articulate-anymesh.github.io.
Coarse-Fine Spectral-Aware Deformable Convolution For Hyperspectral Image Reconstruction
Jun 18, 2024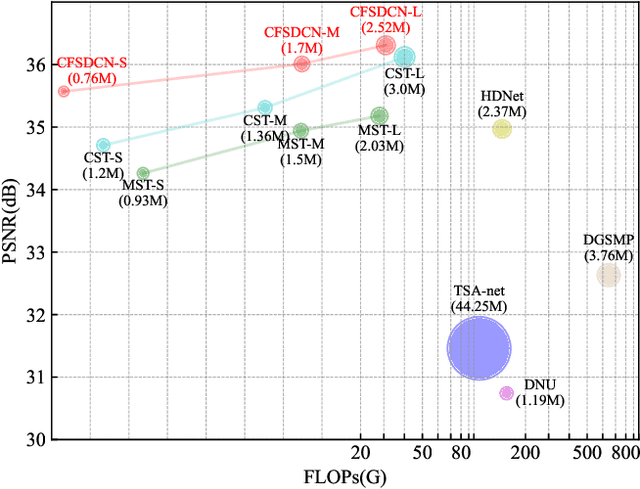
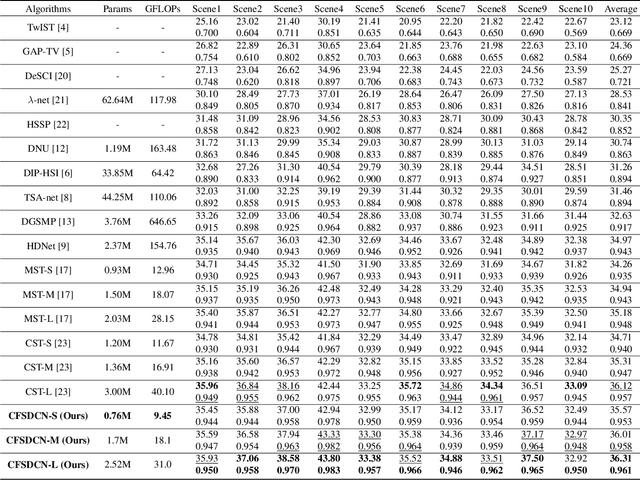
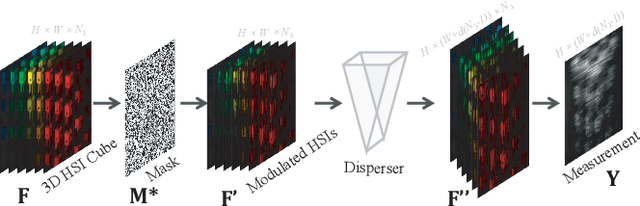

We study the inverse problem of Coded Aperture Snapshot Spectral Imaging (CASSI), which captures a spatial-spectral data cube using snapshot 2D measurements and uses algorithms to reconstruct 3D hyperspectral images (HSI). However, current methods based on Convolutional Neural Networks (CNNs) struggle to capture long-range dependencies and non-local similarities. The recently popular Transformer-based methods are poorly deployed on downstream tasks due to the high computational cost caused by self-attention. In this paper, we propose Coarse-Fine Spectral-Aware Deformable Convolution Network (CFSDCN), applying deformable convolutional networks (DCN) to this task for the first time. Considering the sparsity of HSI, we design a deformable convolution module that exploits its deformability to capture long-range dependencies and non-local similarities. In addition, we propose a new spectral information interaction module that considers both coarse-grained and fine-grained spectral similarities. Extensive experiments demonstrate that our CFSDCN significantly outperforms previous state-of-the-art (SOTA) methods on both simulated and real HSI datasets.
3D-VLA: A 3D Vision-Language-Action Generative World Model
Mar 14, 2024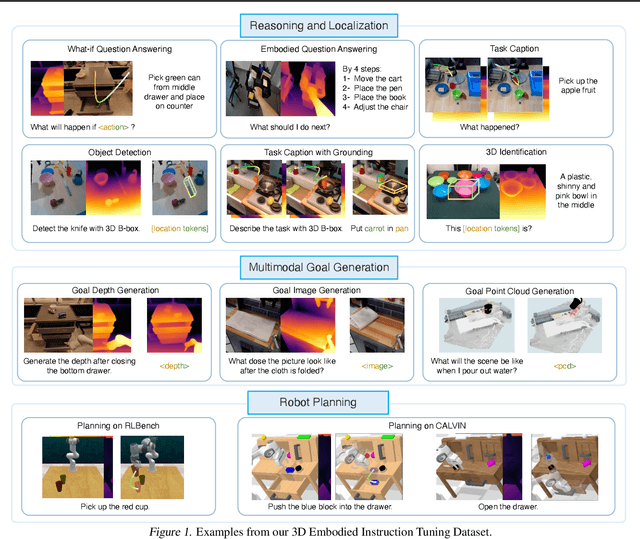
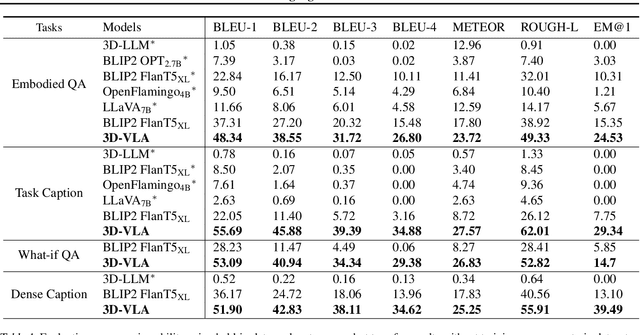
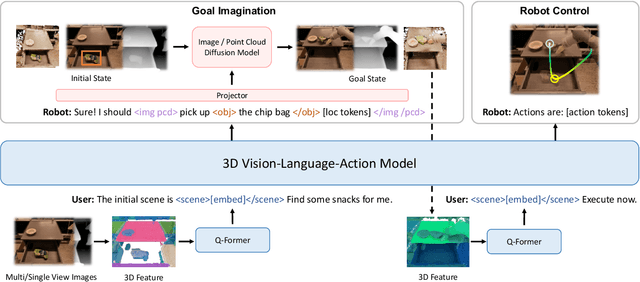
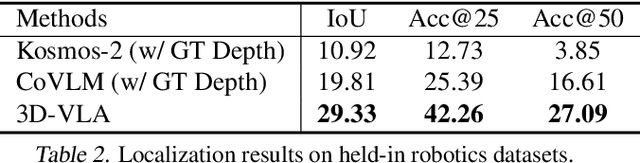
Recent vision-language-action (VLA) models rely on 2D inputs, lacking integration with the broader realm of the 3D physical world. Furthermore, they perform action prediction by learning a direct mapping from perception to action, neglecting the vast dynamics of the world and the relations between actions and dynamics. In contrast, human beings are endowed with world models that depict imagination about future scenarios to plan actions accordingly. To this end, we propose 3D-VLA by introducing a new family of embodied foundation models that seamlessly link 3D perception, reasoning, and action through a generative world model. Specifically, 3D-VLA is built on top of a 3D-based large language model (LLM), and a set of interaction tokens is introduced to engage with the embodied environment. Furthermore, to inject generation abilities into the model, we train a series of embodied diffusion models and align them into the LLM for predicting the goal images and point clouds. To train our 3D-VLA, we curate a large-scale 3D embodied instruction dataset by extracting vast 3D-related information from existing robotics datasets. Our experiments on held-in datasets demonstrate that 3D-VLA significantly improves the reasoning, multimodal generation, and planning capabilities in embodied environments, showcasing its potential in real-world applications.
A Simple Duality Proof for Wasserstein Distributionally Robust Optimization
Apr 30, 2022
We present a short and elementary proof of the duality for Wasserstein distributionally robust optimization, which holds for any arbitrary Kantorovich transport distance, any arbitrary measurable loss function, and any arbitrary nominal probability distribution, as long as certain interchangeability principle holds.