 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHBVLA: Pushing 1-Bit Post-Training Quantization for Vision-Language-Action Models
Feb 14, 2026Vision-Language-Action (VLA) models enable instruction-following embodied control, but their large compute and memory footprints hinder deployment on resource-constrained robots and edge platforms. While reducing weights to 1-bit precision through binarization can greatly improve efficiency, existing methods fail to narrow the distribution gap between binarized and full-precision weights, causing quantization errors to accumulate under long-horizon closed-loop execution and severely degrade actions. To fill this gap, we propose HBVLA, a VLA-tailored binarization framework. First, we use a policy-aware enhanced Hessian to identify weights that are truly critical for action generation. Then, we employ a sparse orthogonal transform for non-salient weights to induce a low-entropy intermediate state. Finally, we quantize both salient and non-salient weights in the Harr domain with group-wise 1-bit quantization. We have evaluated our approach on different VLAs: on LIBERO, quantized OpenVLA-OFT retains 92.2% of full-precision performance; on SimplerEnv, quantized CogAct retains 93.6%, significantly outperforming state-of-the-art binarization methods. We further validate our method on real-world evaluation suite and the results show that HBVLA incurs only marginal success-rate degradation compared to the full-precision model, demonstrating robust deployability under tight hardware constraints. Our work provides a practical foundation for ultra-low-bit quantization of VLAs, enabling more reliable deployment on hardware-limited robotic platforms.
MindChat: A Privacy-preserving Large Language Model for Mental Health Support
Jan 05, 2026Large language models (LLMs) have shown promise for mental health support, yet training such models is constrained by the scarcity and sensitivity of real counseling dialogues. In this article, we present MindChat, a privacy-preserving LLM for mental health support, together with MindCorpus, a synthetic multi-turn counseling dataset constructed via a multi-agent role-playing framework. To synthesize high-quality counseling data, the developed dialogue-construction framework employs a dual closed-loop feedback design to integrate psychological expertise and counseling techniques through role-playing: (i) turn-level critique-and-revision to improve coherence and counseling appropriateness within a session, and (ii) session-level strategy refinement to progressively enrich counselor behaviors across sessions. To mitigate privacy risks under decentralized data ownership, we fine-tune the base model using federated learning with parameter-efficient LoRA adapters and incorporate differentially private optimization to reduce membership and memorization risks. Experiments on synthetic-data quality assessment and counseling capability evaluation show that MindCorpus improves training effectiveness and that MindChat is competitive with existing general and counseling-oriented LLM baselines under both automatic LLM-judge and human evaluation protocols, while exhibiting reduced privacy leakage under membership inference attacks.
ReMA: A Training-Free Plug-and-Play Mixing Augmentation for Video Behavior Recognition
Jan 01, 2026Video behavior recognition demands stable and discriminative representations under complex spatiotemporal variations. However, prevailing data augmentation strategies for videos remain largely perturbation-driven, often introducing uncontrolled variations that amplify non-discriminative factors, which finally weaken intra-class distributional structure and representation drift with inconsistent gains across temporal scales. To address these problems, we propose Representation-aware Mixing Augmentation (ReMA), a plug-and-play augmentation strategy that formulates mixing as a controlled replacement process to expand representations while preserving class-conditional stability. ReMA integrates two complementary mechanisms. Firstly, the Representation Alignment Mechanism (RAM) performs structured intra-class mixing under distributional alignment constraints, suppressing irrelevant intra-class drift while enhancing statistical reliability. Then, the Dynamic Selection Mechanism (DSM) generates motion-aware spatiotemporal masks to localize perturbations, guiding them away from discrimination-sensitive regions and promoting temporal coherence. By jointly controlling how and where mixing is applied, ReMA improves representation robustness without additional supervision or trainable parameters. Extensive experiments on diverse video behavior benchmarks demonstrate that ReMA consistently enhances generalization and robustness across different spatiotemporal granularities.
Disentangling Emotional Bases and Transient Fluctuations: A Low-Rank Sparse Decomposition Approach for Video Affective Analysis
Nov 14, 2025Video-based Affective Computing (VAC), vital for emotion analysis and human-computer interaction, suffers from model instability and representational degradation due to complex emotional dynamics. Since the meaning of different emotional fluctuations may differ under different emotional contexts, the core limitation is the lack of a hierarchical structural mechanism to disentangle distinct affective components, i.e., emotional bases (the long-term emotional tone), and transient fluctuations (the short-term emotional fluctuations). To address this, we propose the Low-Rank Sparse Emotion Understanding Framework (LSEF), a unified model grounded in the Low-Rank Sparse Principle, which theoretically reframes affective dynamics as a hierarchical low-rank sparse compositional process. LSEF employs three plug-and-play modules, i.e., the Stability Encoding Module (SEM) captures low-rank emotional bases; the Dynamic Decoupling Module (DDM) isolates sparse transient signals; and the Consistency Integration Module (CIM) reconstructs multi-scale stability and reactivity coherence. This framework is optimized by a Rank Aware Optimization (RAO) strategy that adaptively balances gradient smoothness and sensitivity. Extensive experiments across multiple datasets confirm that LSEF significantly enhances robustness and dynamic discrimination, which further validates the effectiveness and generality of hierarchical low-rank sparse modeling for understanding affective dynamics.
Decoupling Contrastive Decoding: Robust Hallucination Mitigation in Multimodal Large Language Models
Apr 09, 2025



Although multimodal large language models (MLLMs) exhibit remarkable reasoning capabilities on complex multimodal understanding tasks, they still suffer from the notorious hallucination issue: generating outputs misaligned with obvious visual or factual evidence. Currently, training-based solutions, like direct preference optimization (DPO), leverage paired preference data to suppress hallucinations. However, they risk sacrificing general reasoning capabilities due to the likelihood displacement. Meanwhile, training-free solutions, like contrastive decoding, achieve this goal by subtracting the estimated hallucination pattern from a distorted input. Yet, these handcrafted perturbations (e.g., add noise to images) may poorly capture authentic hallucination patterns. To avoid these weaknesses of existing methods, and realize robust hallucination mitigation (i.e., maintaining general reasoning performance), we propose a novel framework: Decoupling Contrastive Decoding (DCD). Specifically, DCD decouples the learning of positive and negative samples in preference datasets, and trains separate positive and negative image projections within the MLLM. The negative projection implicitly models real hallucination patterns, which enables vision-aware negative images in the contrastive decoding inference stage. Our DCD alleviates likelihood displacement by avoiding pairwise optimization and generalizes robustly without handcrafted degradation. Extensive ablations across hallucination benchmarks and general reasoning tasks demonstrate the effectiveness of DCD, i.e., it matches DPO's hallucination suppression while preserving general capabilities and outperforms the handcrafted contrastive decoding methods.
Long Video Diffusion Generation with Segmented Cross-Attention and Content-Rich Video Data Curation
Dec 02, 2024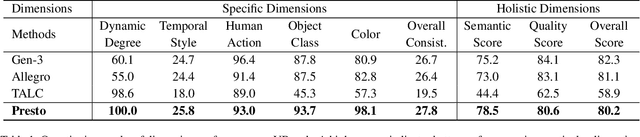
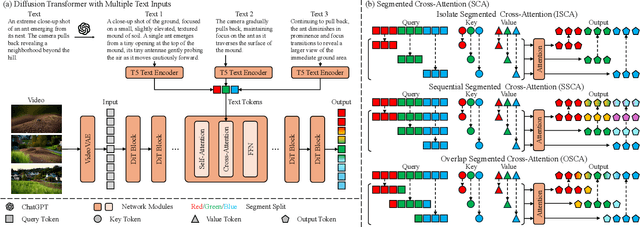


We introduce Presto, a novel video diffusion model designed to generate 15-second videos with long-range coherence and rich content. Extending video generation methods to maintain scenario diversity over long durations presents significant challenges. To address this, we propose a Segmented Cross-Attention (SCA) strategy, which splits hidden states into segments along the temporal dimension, allowing each segment to cross-attend to a corresponding sub-caption. SCA requires no additional parameters, enabling seamless incorporation into current DiT-based architectures. To facilitate high-quality long video generation, we build the LongTake-HD dataset, consisting of 261k content-rich videos with scenario coherence, annotated with an overall video caption and five progressive sub-captions. Experiments show that our Presto achieves 78.5% on the VBench Semantic Score and 100% on the Dynamic Degree, outperforming existing state-of-the-art video generation methods. This demonstrates that our proposed Presto significantly enhances content richness, maintains long-range coherence, and captures intricate textual details. More details are displayed on our project page: https://presto-video.github.io/.
RapVerse: Coherent Vocals and Whole-Body Motions Generations from Text
May 30, 2024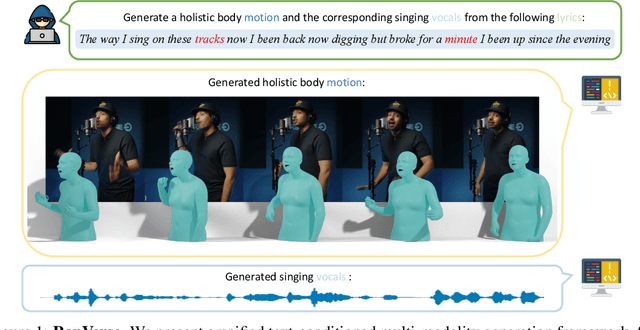
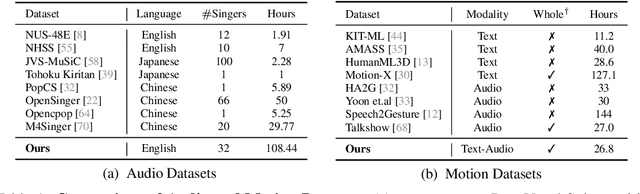
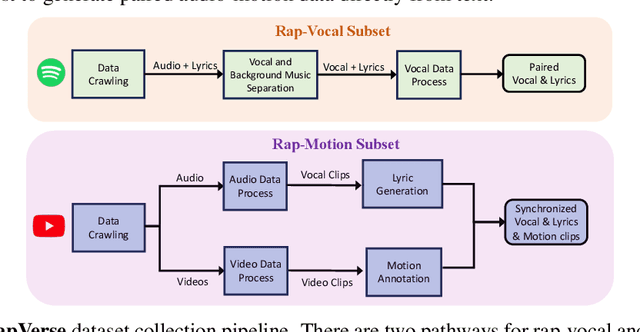
In this work, we introduce a challenging task for simultaneously generating 3D holistic body motions and singing vocals directly from textual lyrics inputs, advancing beyond existing works that typically address these two modalities in isolation. To facilitate this, we first collect the RapVerse dataset, a large dataset containing synchronous rapping vocals, lyrics, and high-quality 3D holistic body meshes. With the RapVerse dataset, we investigate the extent to which scaling autoregressive multimodal transformers across language, audio, and motion can enhance the coherent and realistic generation of vocals and whole-body human motions. For modality unification, a vector-quantized variational autoencoder is employed to encode whole-body motion sequences into discrete motion tokens, while a vocal-to-unit model is leveraged to obtain quantized audio tokens preserving content, prosodic information, and singer identity. By jointly performing transformer modeling on these three modalities in a unified way, our framework ensures a seamless and realistic blend of vocals and human motions. Extensive experiments demonstrate that our unified generation framework not only produces coherent and realistic singing vocals alongside human motions directly from textual inputs but also rivals the performance of specialized single-modality generation systems, establishing new benchmarks for joint vocal-motion generation. The project page is available for research purposes at https://vis-www.cs.umass.edu/RapVerse.
Estimate the building height at a 10-meter resolution based on Sentinel data
May 02, 2024



Building height is an important indicator for scientific research and practical application. However, building height products with a high spatial resolution (10m) are still very scarce. To meet the needs of high-resolution building height estimation models, this study established a set of spatial-spectral-temporal feature databases, combining SAR data provided by Sentinel-1, optical data provided by Sentinel-2, and shape data provided by building footprints. The statistical indicators on the time scale are extracted to form a rich database of 160 features. This study combined with permutation feature importance, Shapley Additive Explanations, and Random Forest variable importance, and the final stable features are obtained through an expert scoring system. This study took 12 large, medium, and small cities in the United States as the training data. It used moving windows to aggregate the pixels to solve the impact of SAR image displacement and building shadows. This study built a building height model based on a random forest model and compared three model ensemble methods of bagging, boosting, and stacking. To evaluate the accuracy of the prediction results, this study collected Lidar data in the test area, and the evaluation results showed that its R-Square reached 0.78, which can prove that the building height can be obtained effectively. The fast production of high-resolution building height data can support large-scale scientific research and application in many fields.
3D-VLA: A 3D Vision-Language-Action Generative World Model
Mar 14, 2024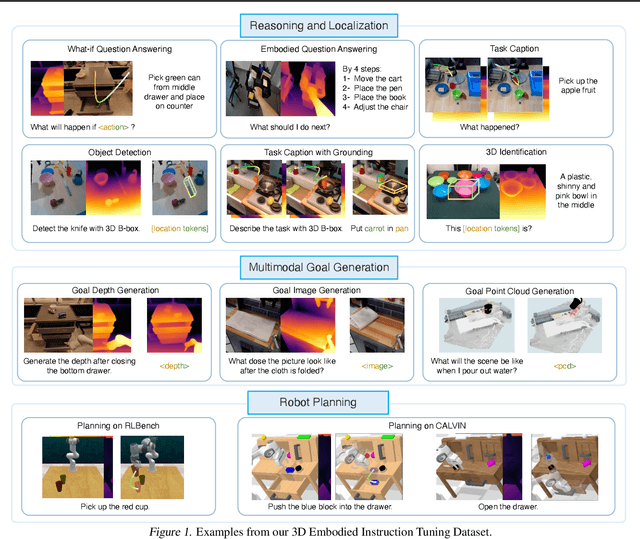
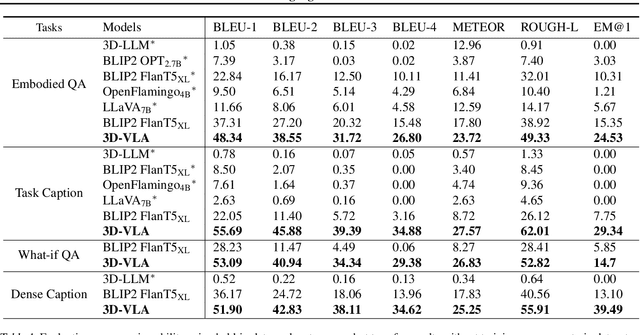
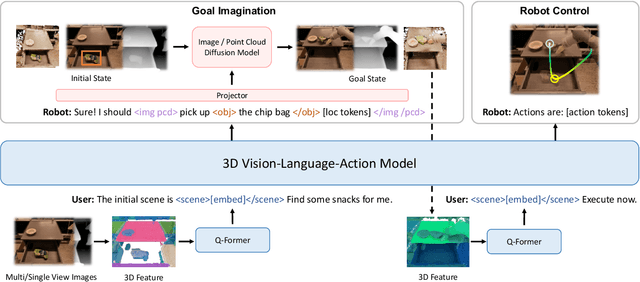
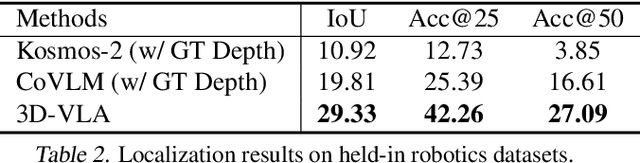
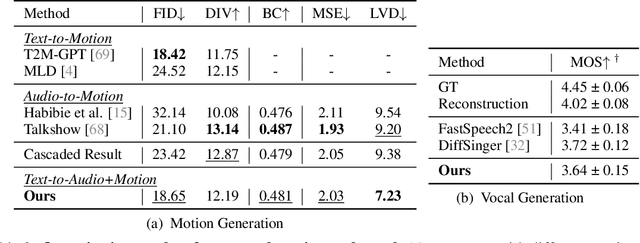
Recent vision-language-action (VLA) models rely on 2D inputs, lacking integration with the broader realm of the 3D physical world. Furthermore, they perform action prediction by learning a direct mapping from perception to action, neglecting the vast dynamics of the world and the relations between actions and dynamics. In contrast, human beings are endowed with world models that depict imagination about future scenarios to plan actions accordingly. To this end, we propose 3D-VLA by introducing a new family of embodied foundation models that seamlessly link 3D perception, reasoning, and action through a generative world model. Specifically, 3D-VLA is built on top of a 3D-based large language model (LLM), and a set of interaction tokens is introduced to engage with the embodied environment. Furthermore, to inject generation abilities into the model, we train a series of embodied diffusion models and align them into the LLM for predicting the goal images and point clouds. To train our 3D-VLA, we curate a large-scale 3D embodied instruction dataset by extracting vast 3D-related information from existing robotics datasets. Our experiments on held-in datasets demonstrate that 3D-VLA significantly improves the reasoning, multimodal generation, and planning capabilities in embodied environments, showcasing its potential in real-world applications.
ContPhy: Continuum Physical Concept Learning and Reasoning from Videos
Feb 09, 2024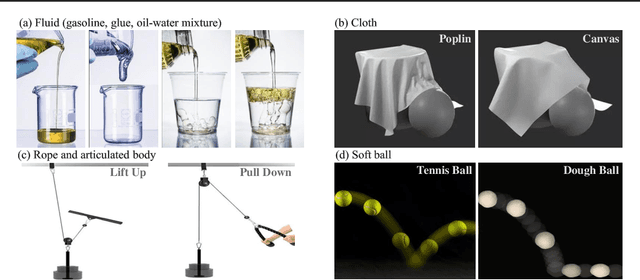
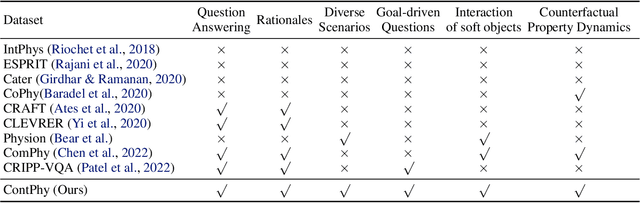
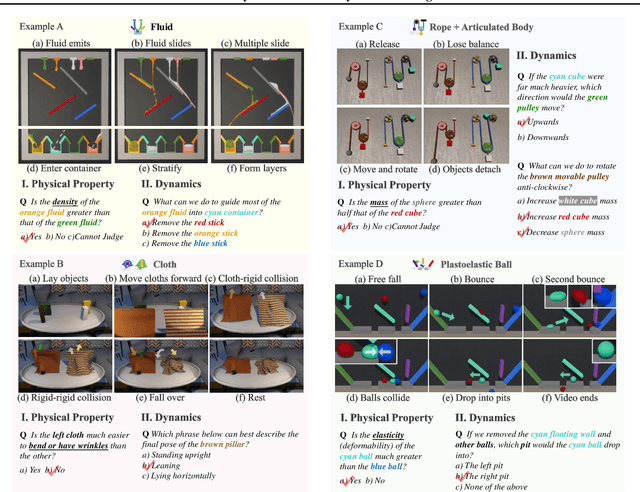
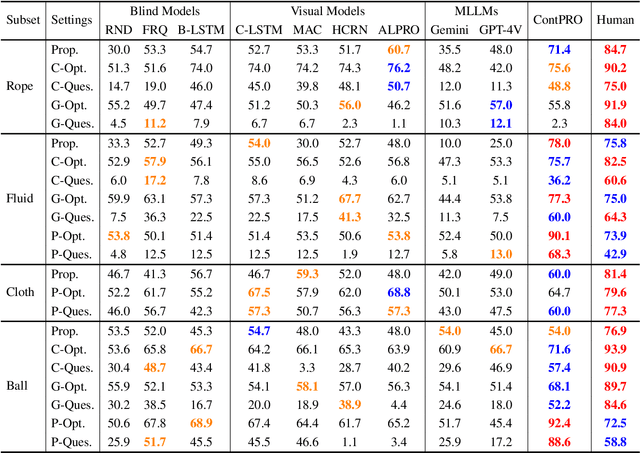
We introduce the Continuum Physical Dataset (ContPhy), a novel benchmark for assessing machine physical commonsense. ContPhy complements existing physical reasoning benchmarks by encompassing the inference of diverse physical properties, such as mass and density, across various scenarios and predicting corresponding dynamics. We evaluated a range of AI models and found that they still struggle to achieve satisfactory performance on ContPhy, which shows that the current AI models still lack physical commonsense for the continuum, especially soft-bodies, and illustrates the value of the proposed dataset. We also introduce an oracle model (ContPRO) that marries the particle-based physical dynamic models with the recent large language models, which enjoy the advantages of both models, precise dynamic predictions, and interpretable reasoning. ContPhy aims to spur progress in perception and reasoning within diverse physical settings, narrowing the divide between human and machine intelligence in understanding the physical world. Project page: https://physical-reasoning-project.github.io.